引用《https://blog.csdn.net/nigeaoaojiao/article/details/54909921》
hlog介绍:

hlog构建:

从图中可以看出,对于一个hlog日志,整一个region server中的region数据都写入到同一个日志中,日志中最小单元的格式为<HLogKey,WALEdit>
hlogKey格式:
- sequenceid,自增id
- write time,写入时间,修改操作何时写入日志的时间戳
- cluster ids,集群id,满足用户多集群之间复制的需求
- region 信息
- table name,表名
hlog滚动:
region server每个一段时间就会生成一个log文件(默认1小时,可以设置),设置日志滚动机制,类似于binlog的处理机制。虽然会产生会多文件,但是考虑到删除文件时,直接将文件删除是最方便的方式。
hlog失效:
当一个日志文件的数据全部从MemStore中flush到了HFile中,该日志文件即可以被删除掉了。可以通过自增id——sequenceid判断,当一个文件中的sequenceid小于Memstore中flush记录的最大的sequenceid即可判断。当一个log被判定为失效后,会被移到oldWALs目录下
hlog删除:
hmaster后台启动一个线程每个一段时间(默认一分钟)检查文件夹OldWALs,判断下面的log是否真正的失效,确认失效即删除。
hbase日志恢复流程:
regionServer是否存活:
hbase中,master检查regionServer是否存活是通过zookeeper实现的,regionServer通过向zookeeper注册节点(/hbase/rs目录下),并且定时向zookeeper上报心跳来证明自己处于存活状态。master通过查看该目录的节点查看regionServer是否存活。
region server出问题的情况:
- regionServer出现长时间的full gc
- regionServer宕机
- zookeeper出问题
- 网络问题
- 等等

在master看来,就是在zookeeper中查看不到具体的region Server注册的节点,这时候就会进行数据恢复。
hbase的日志恢复有三种方式:
- logSplitting
- Distributed log splitting
- Distributed log replay
logSplitting:
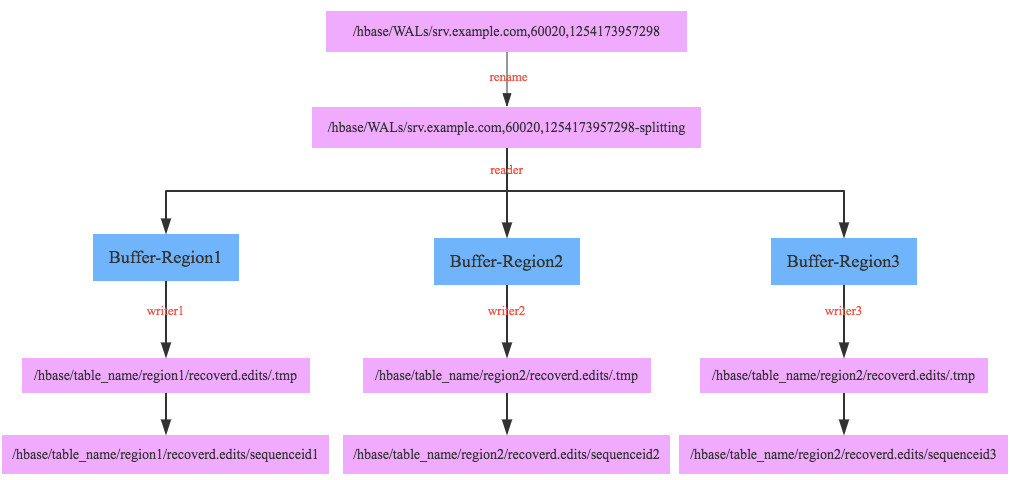
hbase的日志分割方式,整个过程都由HMaster执行。
- 首先将日志复制一份,重命名后缀加-splitting。
- 启动一个线程依次读取log,根据hlogkey中不同的region,写入到不同的buffer中。知道全部的log读完
- 对应每个buffer启动一个线程,将每个buffer的数据写入到hdfs中
- 之后,等hmaster分配完region后,将hdfs中数据写入到对应的region中
因为是单线程恢复,在出现大量的机器宕机后,需要恢复的数据过大,耗时会变得非常长。
Distributed log splitting:
DLS是LS的分布式实现,借助了master和多个regionserver的计算能力,将hlog的splitting任务分散到不同的regionserver上。

- hmaster分别将每个log(该日志在hdfs上的路径)作为一个任务发布到zookeeper上(/hbase/splitWAL节点下),设置起始状态为TASK_UNASSIGNED。
- 所有存活的regionserver都注册这个节点上等待任务,一旦hmaster发布任务,全部regionserver开始竞争任务,即全部regionserver尝试修改任务状态为TASK_OWNED,修改成功即竞争成功。
- regionserver抢占任务成功后,分配任务给相应的线程处理。处理成功修改状态为TASK_DONE,失败修改状态为TASK_ERR。
- hmaster一直监听者该节点,一旦有状态修改就会收到通知,如果任务成功,则删除对应任务节点,如果任务失败,则从新发布任务。
- 具体regionserver处理一个任务的流程和LS处理流程一样
DLS有一个问题,生成的小文件过多,对于M个region,N个hlog日志最终会生成M*N个文件。
Distributed log replay:
DLR方式相对于DLS方式来说,流程上做了一些改动:
- DLR先分配region,在切分回放HLog,region重新分配后状态被设置为recovering,该状态只能写不能读取。而在HLog splitting分配到buffer后,不写文件,而是直接执行回放操作。