Grep及基本正则表达式
正则表达式就是为了处理大量的文本|字符串而定义的一套规则和方法
Linux中的正则表达式,最常应用正则表达式的命令是grep(egrep),sed,awk。
正则表达式分为两种:
基本正则表达式(BRE,basic regular expression)
扩展正则表达式(ERE,extended regular expression)
grep常用参数及作用
–color 匹配到的字符串显示颜色
-i 忽略字符大小写
-o 仅显示匹配的字串
-v 反向选取, 即显示不匹配的行
-E 使用扩展正则表达式
-n 显示行号
-w 以字符串匹配
元数据 意义和范例
1)^word 搜寻word开头的行
例:搜寻以#开头的行,grep -n ‘^#’ file
2)word$ 搜寻word结尾的行
例:搜寻以.结尾的行,grep -n ‘.$’ file
3). 匹配任意一个字符
例:匹配e和e之间有任意一个字符,grep -n ‘e.e’ file
4)\ 转义字符
5)* 前面的一个字符重复0到多次
例:匹配gle,gogle,google,gooogle等,grep -n ‘go*gle’ file
6)[list] 匹配一系列字符中的一个
例:[n1-n2] 匹配一个字符范围中的一个字符
匹配数字字符,grep -n ‘[0-9]’ file
7)[^list] 匹配字符集以外的字符
例:匹配非o字符,grep -n ‘[^o]’ file
8){n1,n2} 前面的单个字符重复n1,n2次
例:匹配google,gooogle,grep -n ’ go{2,3}gle ’ file
9)<word 单词的开头
例:匹配以g开头的单词,grep -n <g file
10)word> 单词的结尾
例:匹配以tion结尾的单词,grep -n tion> file
11)‘ ‘ 强引用,引号内的内容不变
“ ” 弱引用,变量会替换
12)[[:alnum:]] 代表英文大小写字符及数字,即 0-9, A-Z, a-z
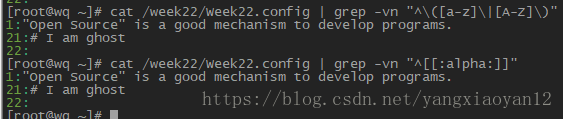
13)[[:alpha:]] 代表任何英文大小写字符,即 A-Z, a-z
14)[[:space:]] 任何会产生空白的字符,包括空白键, [Tab] 等等
15)[[:digit:]] 代表数字,即 0-9
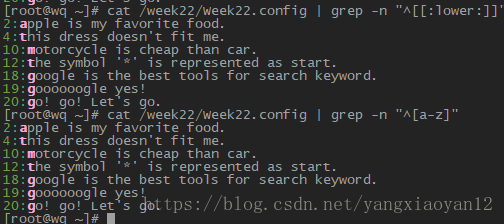
16)[[:lower:]] 代表小写字符,即 a-z
17)[[:upper:]] 代表大写字符,即 A-Z
练习题
例1
#1、显示/proc/meminfo文件中以大小s开头的行(要求:使用两种方法)
cat /proc/meminfo |grep -i “^s”
cat /proc/meminfo |grep “^(s|S)”

#2、显示/etc/passwd文件中不以/bin/bash结尾的行
cat /etc/passwd |grep -v “:/bin/bash$”
#3、显示用户rpc默认的shell程序
cat /etc/passwd |grep -w “^alice” |cut -d: -f 7
#4、找出/etc/passwd中的两位或三位数
cat /etc/passwd |grep -wo “[[:digit:]]{2,3}”
仅用w参数会先以字符串开始匹配,而wo参数符合题目的“两位数或三位数”
#5、显示CentOS7的/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面有非空白字符的行
cat /etc/grub2.cfg | grep “[[:space:]]+[’ ']."
cat /etc/grub2.cfg | grep "[[:space:]]+[[:space:]].”
以下省略
#6、找出“netstat -tan”命令结果中以LISTEN后跟任意多个空白字符结尾的行
netstat -tan | grep “.LISTEN[[:space:]]$”
LISTEN前加上“.*”会让前面部分以高亮显示




#7、显示CentOS7上所有系统用户的用户名和UID
cat /etc/passwd |cut -d: -f1,3 |grep -w “[1-9][0-9]{,2}$”
cat /etc/passwd |cut -d: -f1,3 |grep -w “[1-9][0-9]{,2}”

#8、添加用户bash、testbash、basher、sh、nologin(其shell为/sbin/nologin),找出/etc/passwd用户名
和shell同名的行
cat /etc/passwd |grep -w “([^:]* ):.*/\1$”
#9、利用df和grep,取出磁盘各分区利用率,并从大到小排序
df |grep “^/dev/sd”|grep -wo “[0-9]+%”|sort -nr
#10、显示三个用户root、wang的UID和默认shell
cat /etc/passwd |grep -w “^(root|alice|jack)” |cut -d: -f 3,7
#11、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行
cat /etc/rc.d/init.d/functions |grep -i “^([_[:alnum:]]+()”
#12、使用egrep取出/etc/rc.d/init.d/functions中其基名
echo “/etc/rc.d/init.d/functions” | grep -Eo “[^/][/]?$"|tr -d “/”
#13、使用egrep取出上面路径的目录名
echo “/etc/rc.d/init.d/” | grep -Eo “. * [/]<”
因为“init.d”是目录,取出它所在目录的上级目录,若“initd”是文件,路径部分相同,因为“init.d/后无内容”;若有内容“init.d/空格”路径部分会 跟只有init.d目录相同;若有内容“init.d/dd或init.d/1或init.d/#”路径部分会多“init.d/”;
#14、统计last命令中以root登录的每个主机IP地址登录次数
last |grep -w "^root.<pts” | grep -wE “((([0-9])|([1-9][0-9])|(1[0-9]{2})|(2[0-4][0-9])|
(25[0-5]))[.]){3}(([0-9])|([1-9][0-9])|(1[0-9]{,2})|(2[0-4][0-9])|(25[0-5])){1}[[:space:]]”
|tr -s " "|cut -d " " -f3|sort|uniq -c
#15、利用扩展正则表达式分别表示0-9、10-99、100-199、200-249、250-255
[0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5]
#16、显示ifconfig命令结果中所有IPv4地址
ifconfig |grep -owE “((([0-9]{1,2})|(1[0-9]{2})|(2[0-4][0-9])|(25[0-5]))[.]){3}(([0-9]
{1,2})|(1[0-9]{,2})|(2[0-4][0-9])|(25[0-5])){1}[[:space:]]”
#17、将此字符串:welcome to magedu linux 中的每个字符去重并排序,重复次数多的排到前面
cat test | grep -o “[[:lower:]]”|sort |uniq -c|sort -nr |tr -s ’ ’ | cut -d " " -f 3 |tr -d
‘\n’
#18.找出ifconfig命令结果中的1-255之间的数字
ifconfig | grep -E “<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])>”







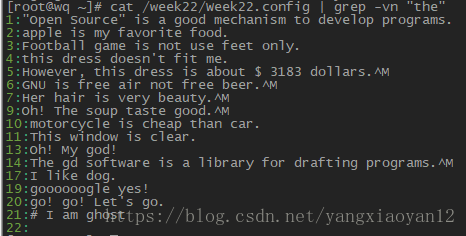
例2请在Week22.config上完成以下题目

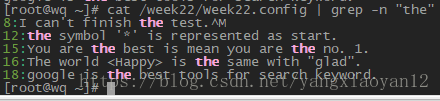
- 取得所有 the 字符相关信息及行号
- 取得无 the 字符相关信息及行号
- 取得 test 或 taste 这两个单字相关信息及行号
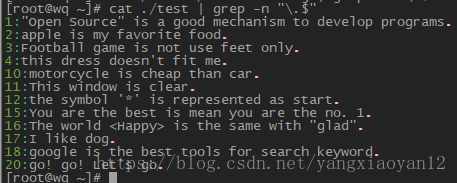
- 取得所有 oo 字符相关信息及行号
- 不想取 oo 前面有 g 的字符相关信息及行号
- oo 前面不想要有小写的字符相关信息及行号
- 取得 the 只在行首相关信息及行号
- 取得有 数字 相关信息及行号
- 取得开头是小写 相关信息及行号
- 不想要开头是英文字母 相关信息及行号
- 取得行尾结束为小数点. 相关信息及行号
- 取得空白行 相关信息及行号
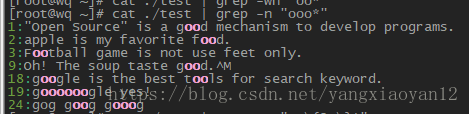
- 取得g??d 的字符相关信息及行号
- 取得至少两个 o 以上的字符相关信息及行号
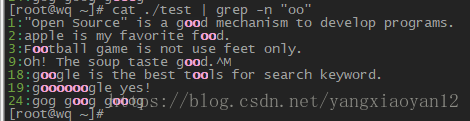
- 取得开头与结尾都是 g ,两个g 之间仅能存在至少一个 o 相关信息及行号
- 取得g 开头与 g 结尾的字符,当中的字符可有可无 相关信息及行号
- 取得两个连续 o 的字符相关信息及行号
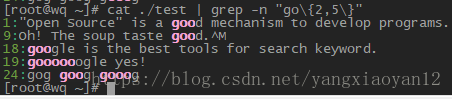
- 取得g 后面连接2到5个 o,然后再接一个 g 的字符相关信息及行号
. egrep及扩展正则表达式
通过参数-E支持扩展正则表达式,另外grep单独提供了一个扩展命令叫做egrep用来支持扩展正则表达式,这条命令和grep -E等价(grep -E == egrep)
扩展正则表达式就是在基本正则表达式的基础上,增加了一些元数据












元数据 意义和范例
- 重复前面字符1到多次
例:匹配god,good,goood等字符串,grep -nE go+d’ file
? 匹配0或1次前面的字符
例:匹配gd,god,grep -nE ‘go?d’ file
| 或or的方式匹配多个字符串
例:匹配god或者good,grep -nE’god|good’ file
() 匹配整个括号内的字符串,原来都是匹配单个字符
例:搜索good或者glad,grep -nE ‘g(oo|la)’ file
- 前面的字符重复0到多次