Date: 2017-01-01 10:10:10
HTTP知识笔记(一般)
网络基础TCP/IP协议族
计算机与网络设置之间要互相通信,怎么办,怎么样不同的计算机之间互相通信。
这就需要统一定义相应的协议,大家互相遵守协议,这样按照协议的规定来传输数据,这样大家就都互相认识了。
协议中规定了很多内容。从电缆的规格到ip地址的选定方法,寻找异地用户的方法,双方建立的通信的顺序,以及web页面显示需要处理的步骤等等。
一句话,大家就是按照协议规定的走就没问题了。
TCP/IP的分层管理
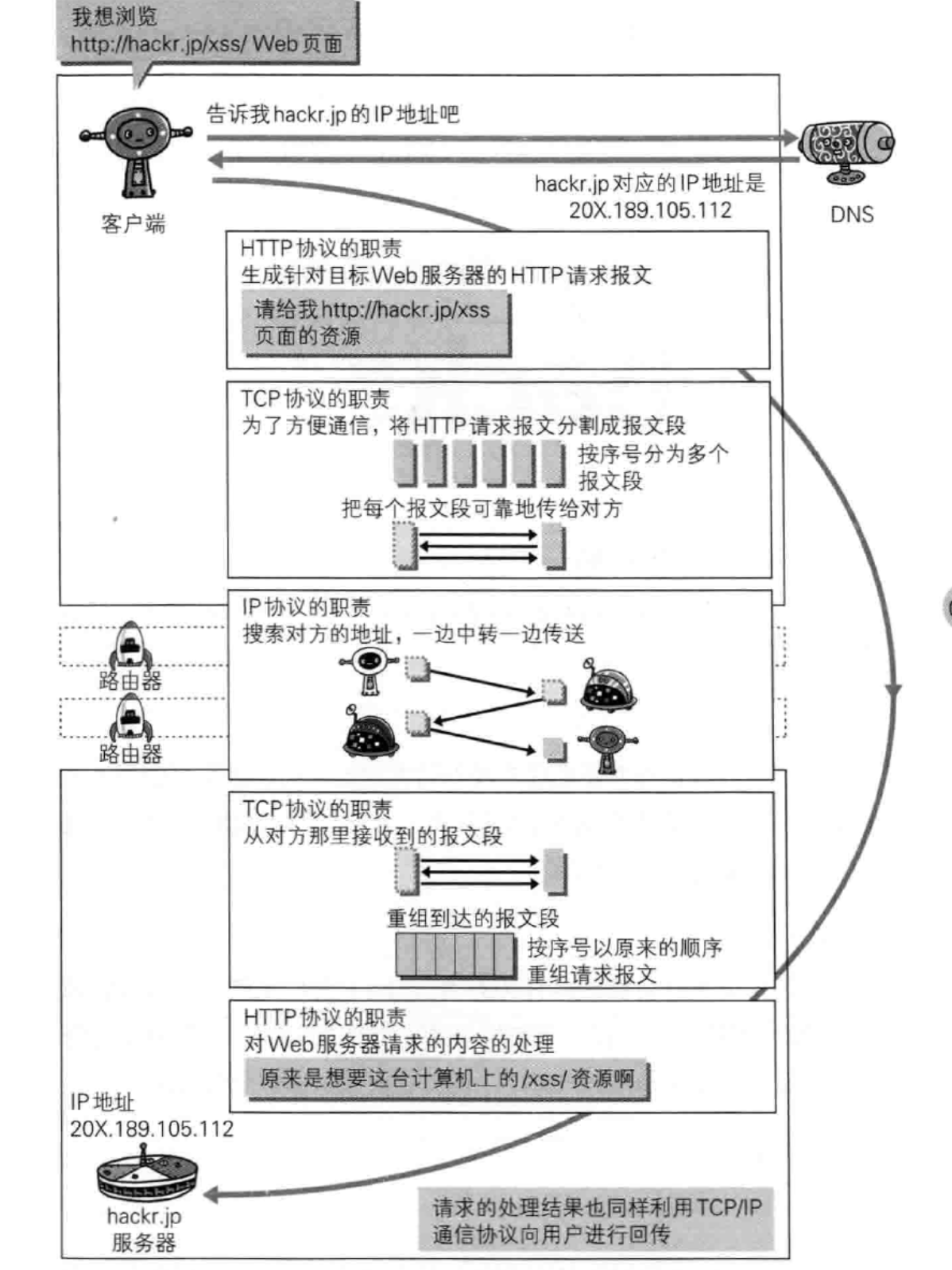
TCP/IP协议族的分为4层:应用层,传输层,网络层和数据链路层。
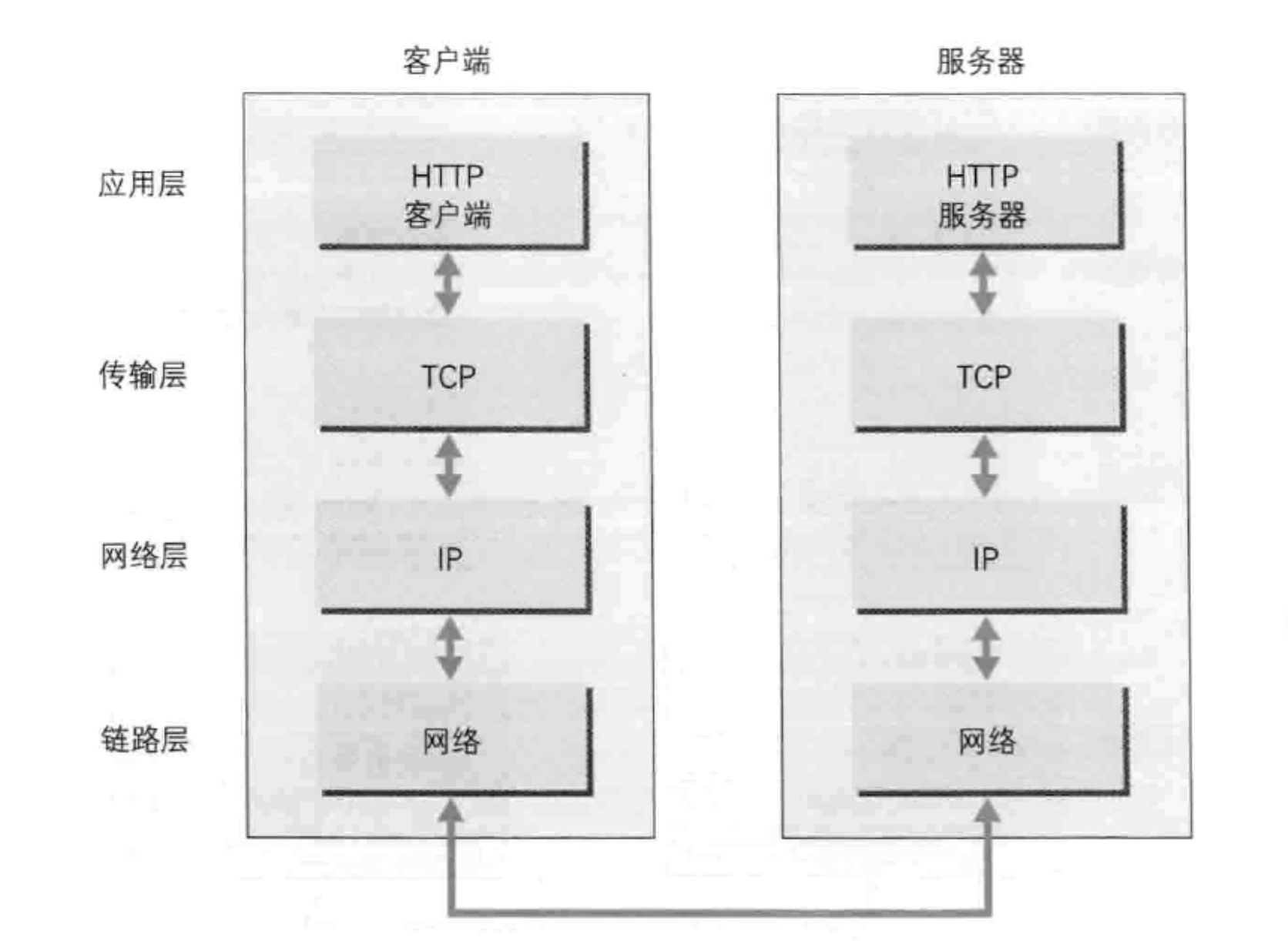
- 应用层:决定向用户提供应用服务时通信的活动(http,ftp,dns)
- 传输层:提供处于网络链接中的两台计算机之间的数据传输。(tcp,udp)
- 网络应用层:处理在网络上流动的数据包。该层规定了通过怎样的路径到达对方计算机,并把数据包传送给对方。(IP)与对方计算机之间传输数据需要通过多台计算机或者网络设备传输,网络层所起到的作用就是在众多的选项内选择一条传输路线。
- 链路层:用来处理链接网络的硬件部分。包括操作系统,硬件的设备驱动,网卡,光纤等物理可见部分。
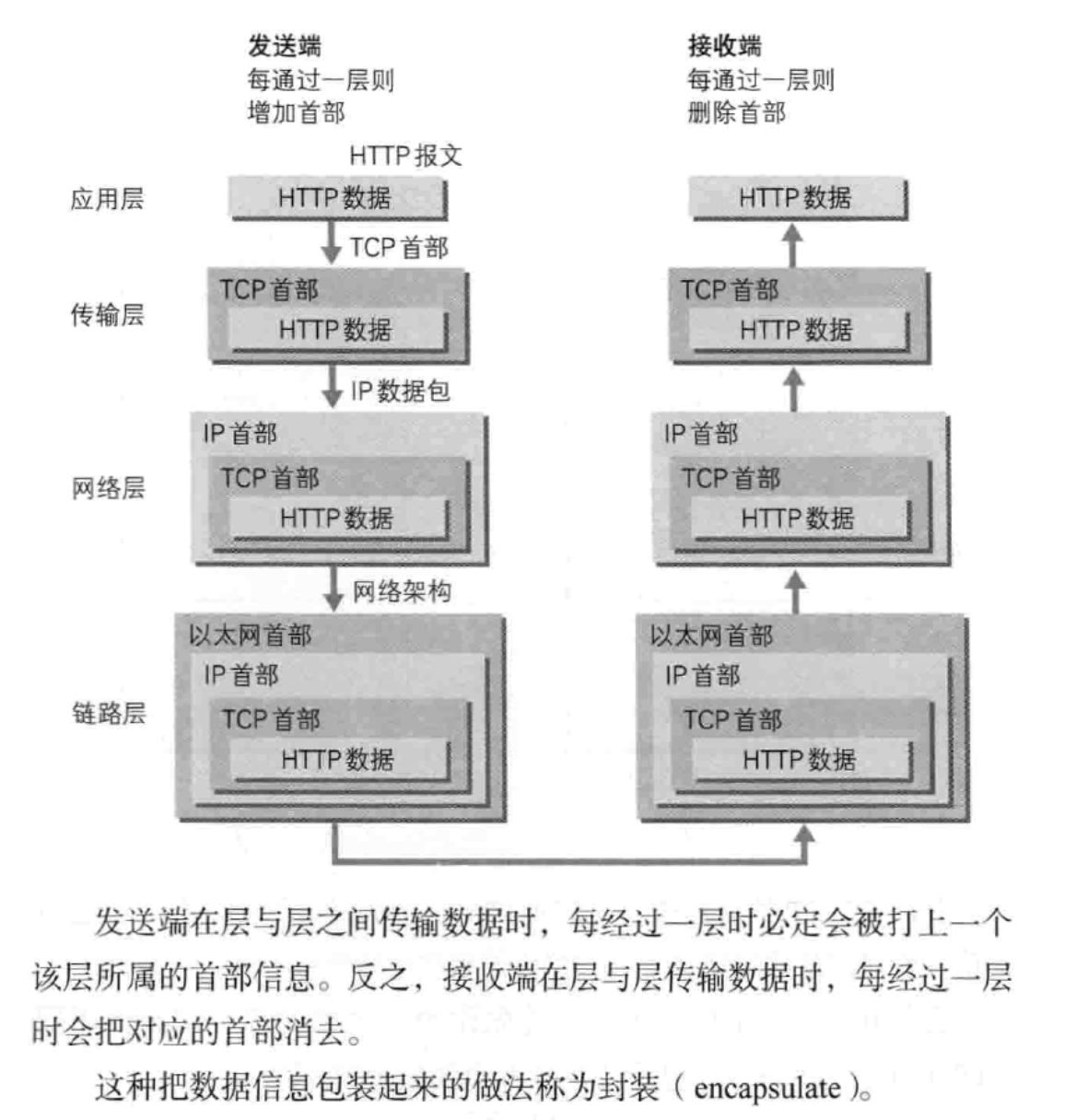
负责传输的IP协议
IP协议的作用就是把各种数据包发送给对方。IP地址指明了节点被分配到的地址,MAC地址是网卡所属的固定地址,IP地址可以和MAC地址配对。
ARP协议:地址解析协议。根据通信方的IP地址就可以反查出对应的MAC地址。
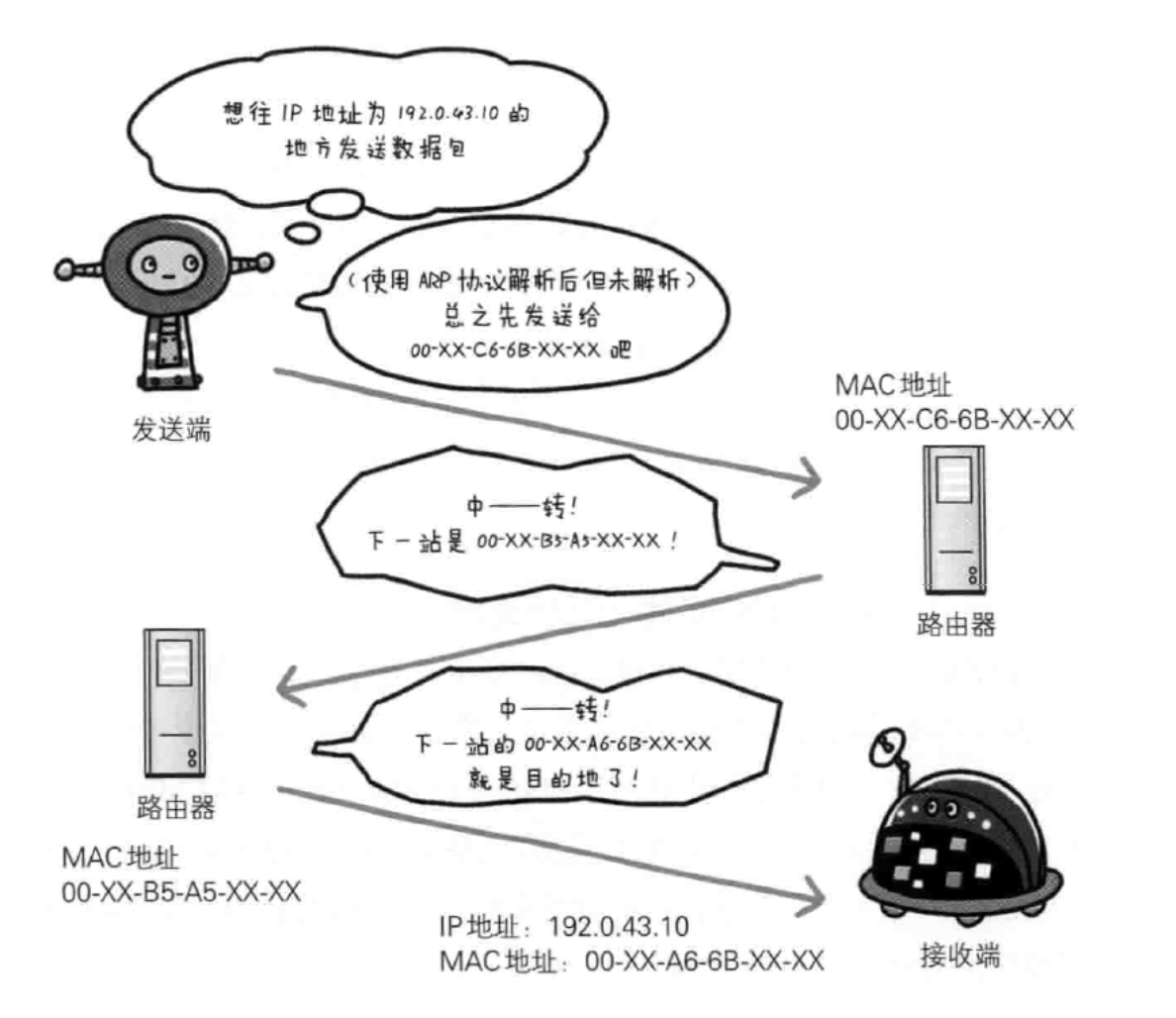
IP查找目标MAC地址的时候并不是立即能找到的,这个时候就需要路由器与路由器之间的转发,这样才能最终找到。
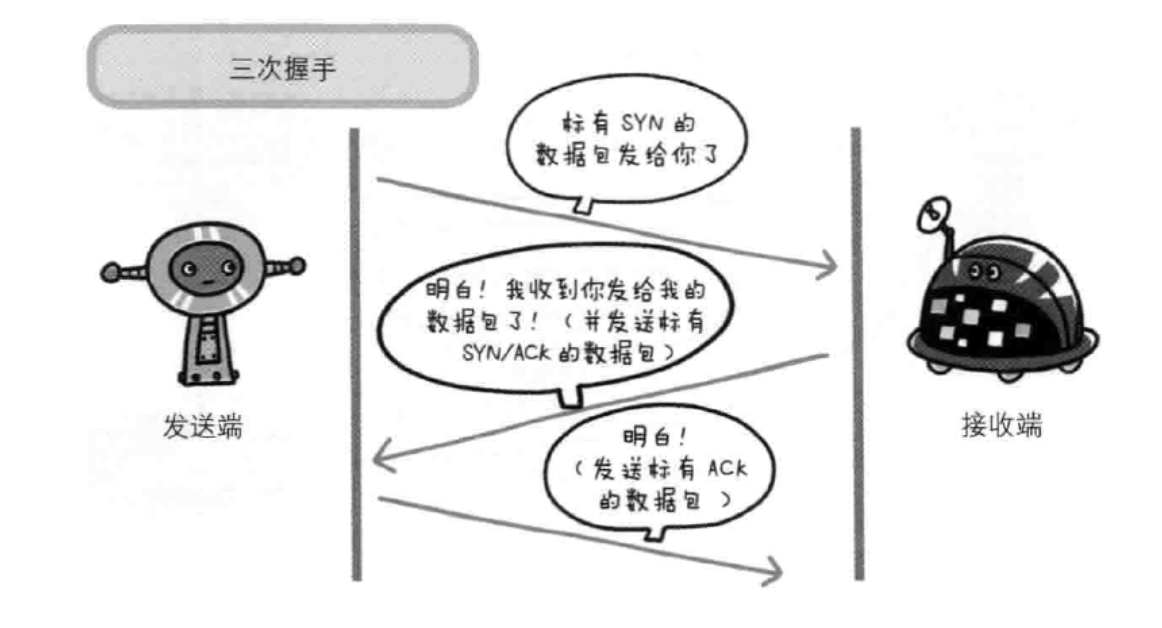
TCP保证可靠性。
三次握手
协议族之间的互相配合
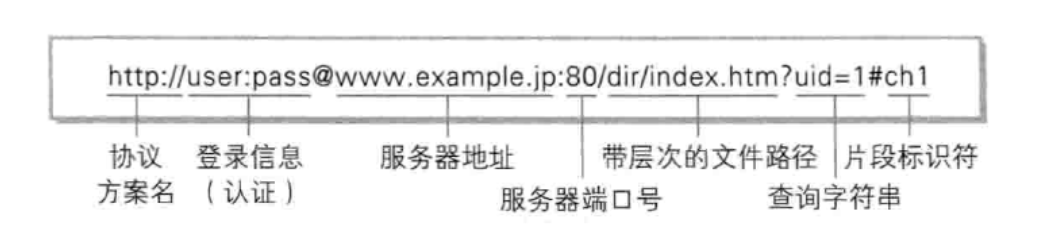
简单URI介绍
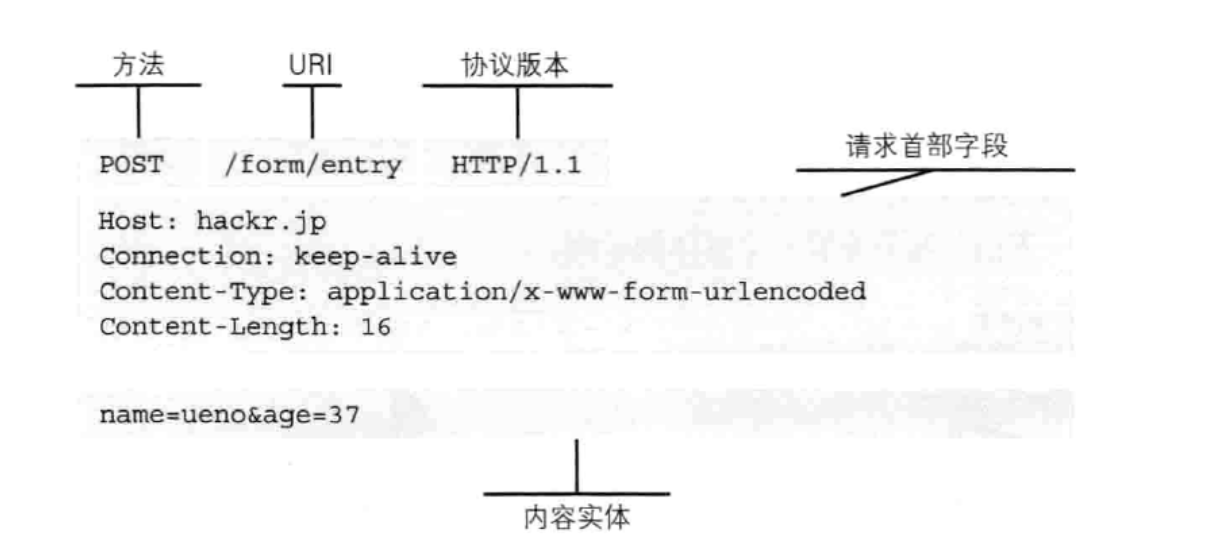
HTTP协议
http(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,常基于TCP的连接方式,HTTP1.1版本中给出一种持续连接的机制,绝大多数的Web开发,都是构建在HTTP协议之上的Web应用。
uri资源定位

HTTP方法
- GET 请求url资源,获取响应的主体内容。
- POST 用来传输实体的主体,虽然GET方法也可以,但是一般用GET方法进行传输。
- HEAD 和GET方法一样,只是不返回报文的主体部分,用于确认URI的有效性及资源更新的日期等。
- PUT 用来传输文件。就像FTP的文件上传一样,要求在请求报文的主体中包含文件内容,然后保存到请求的uri指定的位置。由于PUT自身不带验证机制,任何人都可以上传文件,所以安全考虑一般不使用PUT上传文件。
- DELETE 请求服务器删除Request-URI所标识的资源
- OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求

TRACE 追踪路径。trace方法是让web服务器端将之前的请求通信环回给客户端的方法。请求时在Max-Forwards首部字段中填入数值,每经过一个服务器端就将该数字减1,当数值刚好减到0时,就停止继续传输。
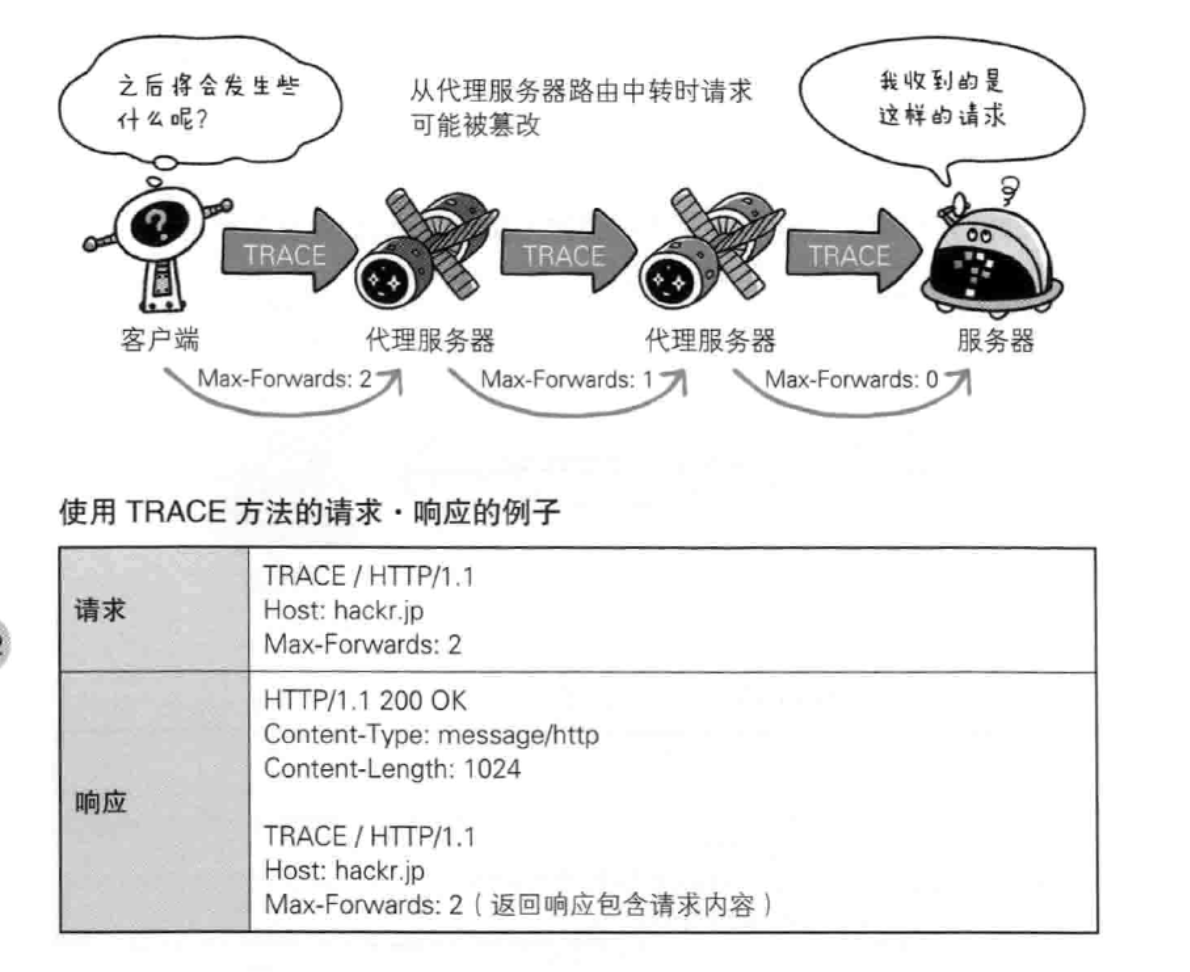
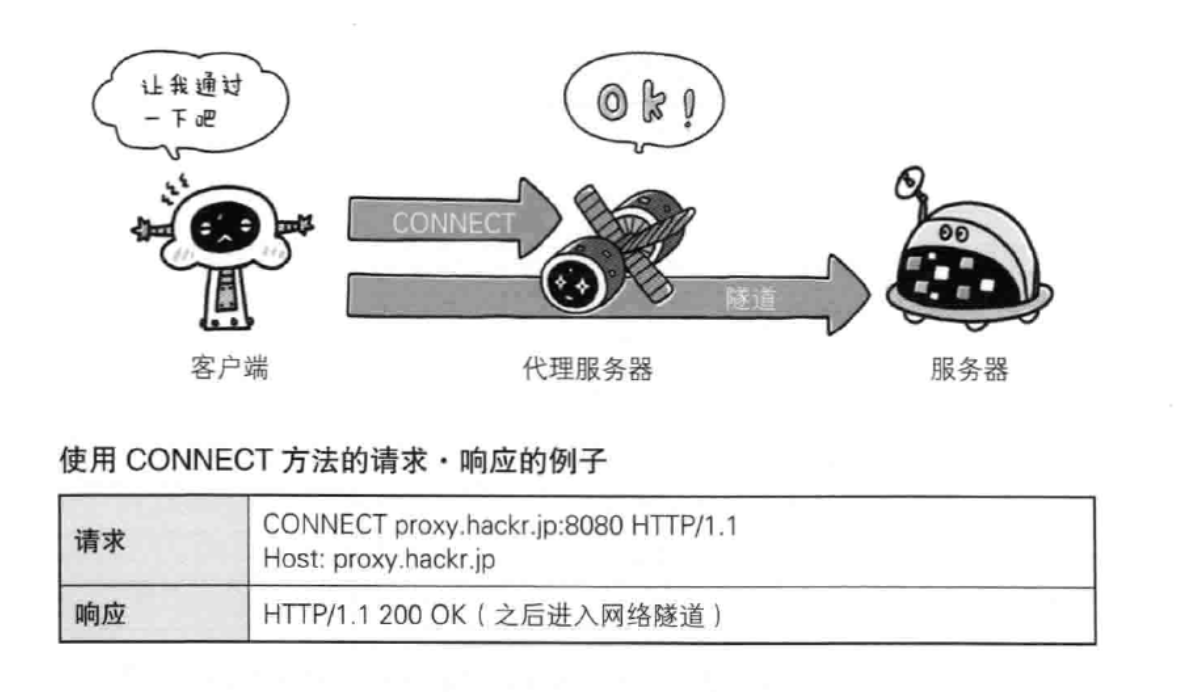
CONNECT 要求用隧道协议链接代理:方法要求与代理服务器通信时建立隧道,实现用隧道协议进行TCP通行。主要使用SSL和TLS协议把通信内容加密后经过网络隧道传输。
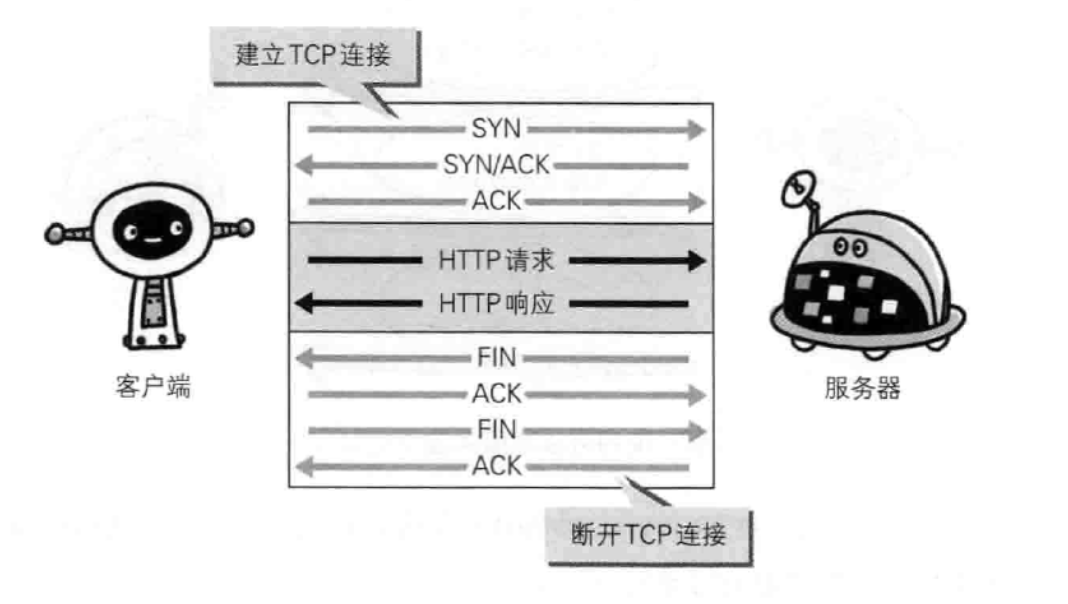
持久连接节省通信信量
HTTP协议的初始版本中,每进行一次HTTP通信就要断开一次TCP连接。
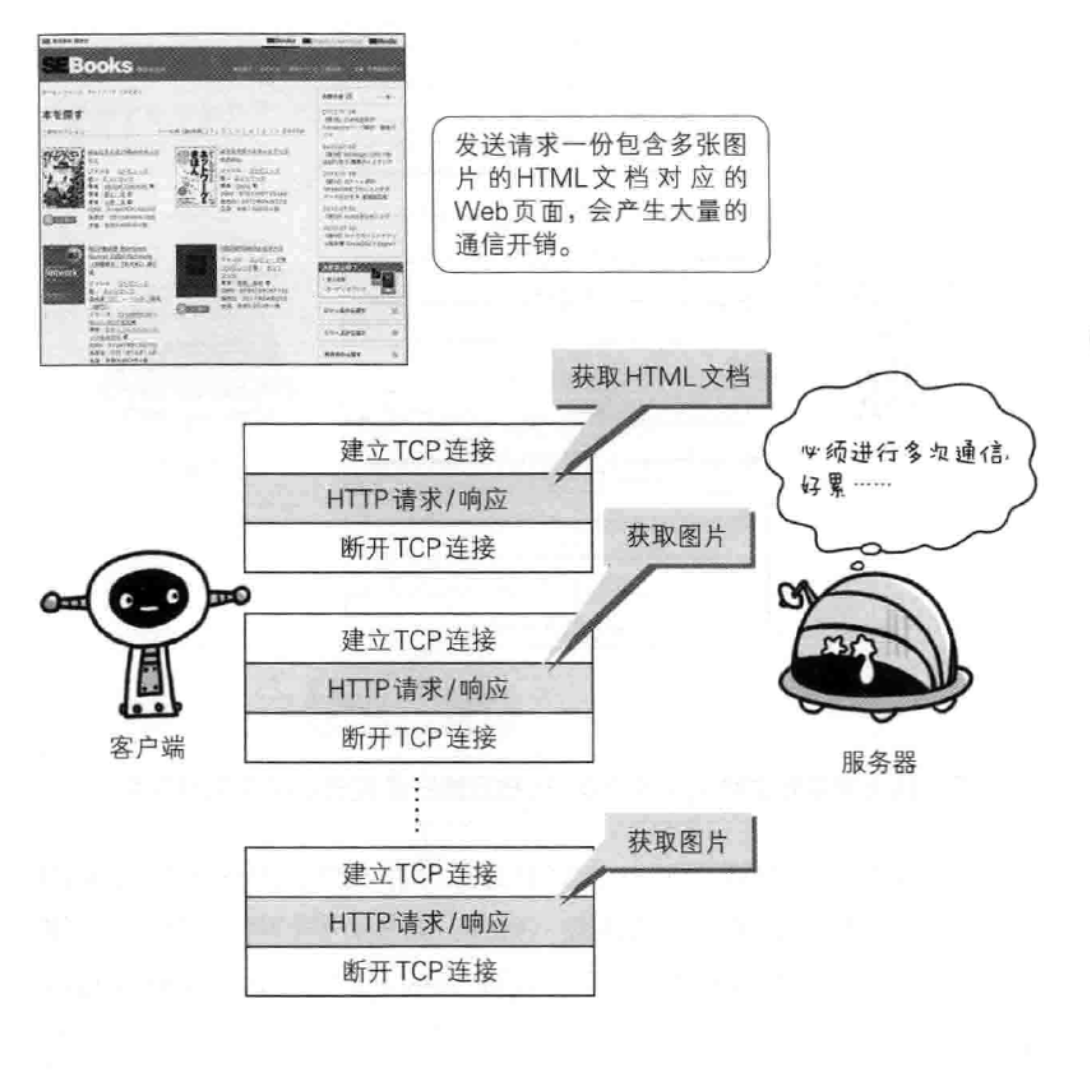
问题?例如当页面中有多张图片时,需要断开重新连接,断开重新连接请求不同的图片。
持久连接:keep-alive
在http1.0和1.1版本中,添加了一个keep-alive属性。持久连接的特点,只要任意一端没有明确断开连接,则TCP保持连接状态。
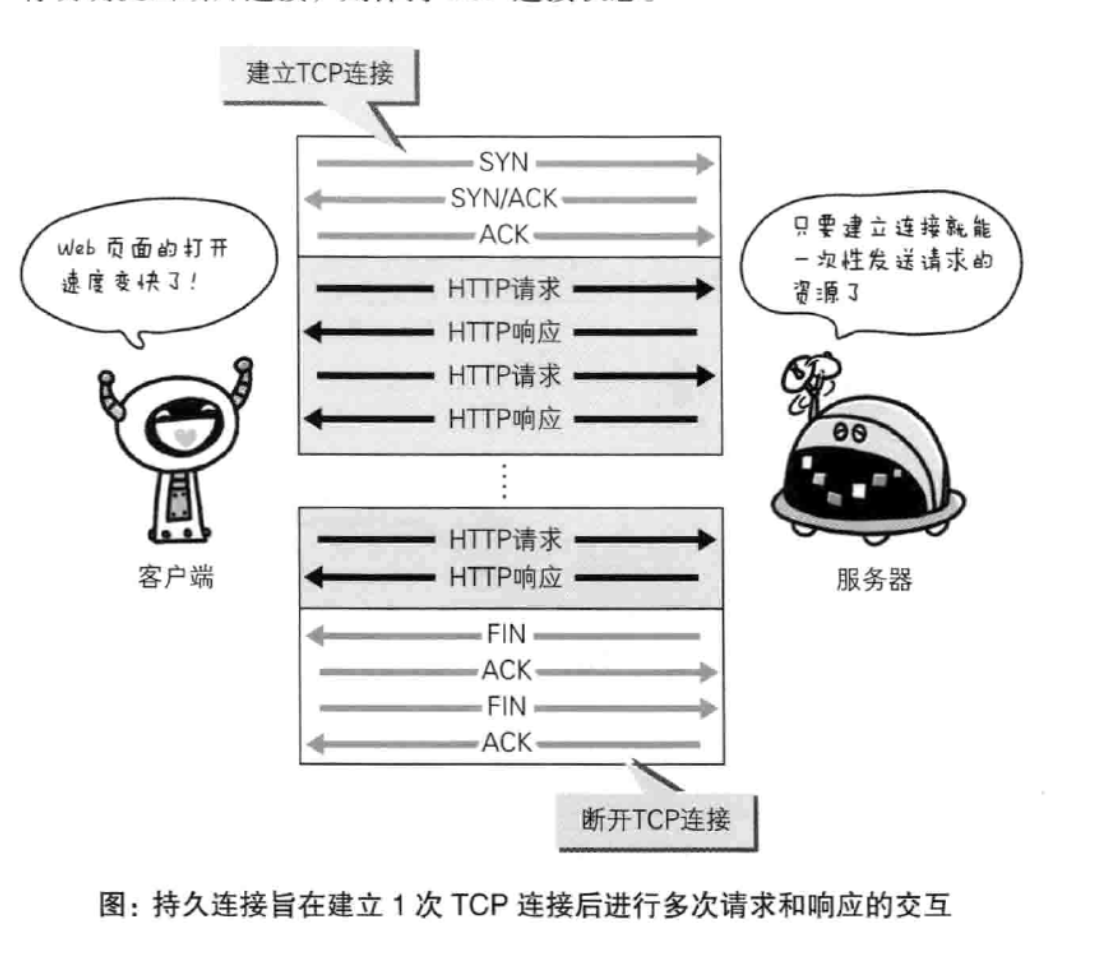
持久连接的好处就是减少TCP连接的重复建立和断开所造成的额外开销。
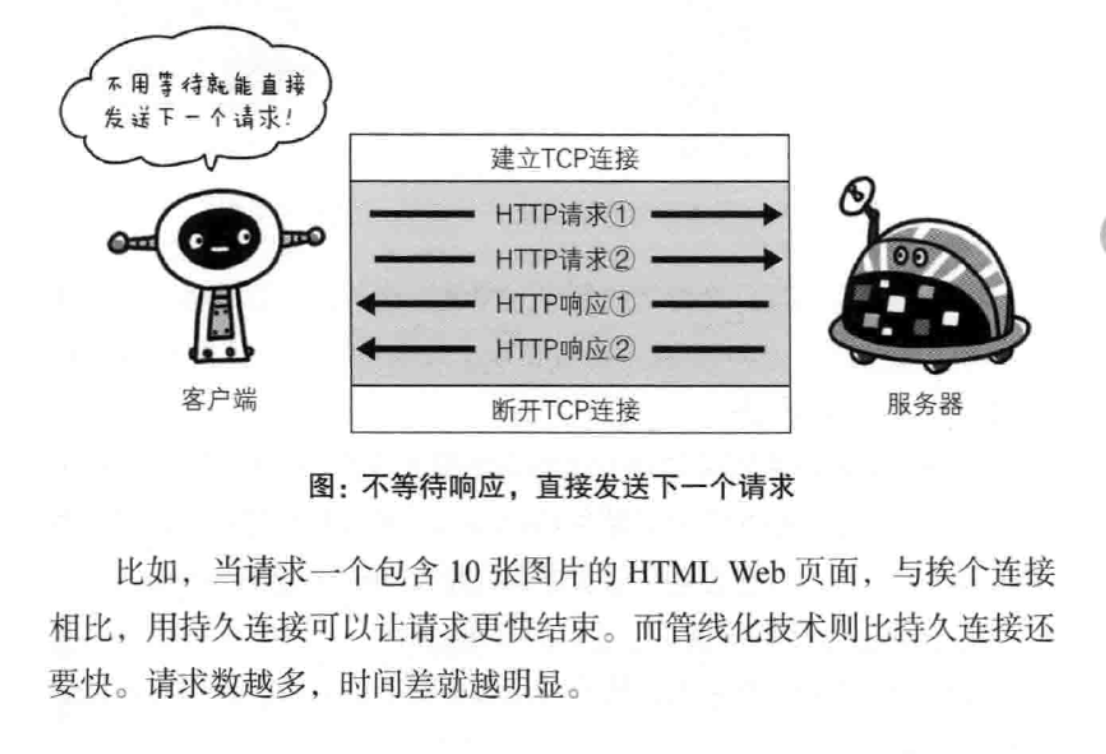
管线化
持久使得多数请求以管线话的方式发送成为可能。管线化技术出现后可以同时并行发送多个请求,而不需要一个接一个地等待响应。
cookie状态
http是无状态的,这样不利于保存用户登录信息,所以有了cookie,可以存储用户信息了。
小总结
从上面可以看出,一个http请求需要建立一个tpc连接,建立后才能进行通信,刚开始时只能一个请求一次然后断开再请求下一次.
有了keep-alive后可以只建立一个tpc,http请求多次,但是第二次请求需要等待第一次返回成功后才能接着往下请求.
有了pipelining后,可以第一个请求,第二个请求一起请求。
HTTP响应状态
HTTP响应也是由三个部分组成,分别是:状态行、消息报头、响应正文
1、状态行格式如下:
HTTP-Version Status-Code Reason-Phrase CRLF
其中,HTTP-Version表示服务器HTTP协议的版本;
Status-Code表示服务器发回的响应状态代码;
Reason-Phrase表示状态代码的文本描述.
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
常见状态代码、状态描述、说明:
200 OK //客户端请求成功
204:请求被受理但没有资源可以返回
206:客户端只是请求资源的一部分,服务器只对请求的部分资源执行GET方法,相应报文中通过Content-Range指定范围的资源。
301:永久性重定向
302:临时重定向
303:与302状态码有相似功能,只是它希望客户端在请求一个URI的时候,能通过GET方法重定向到另一个URI上
304:发送附带条件的请求时,条件不满足时返回,与重定向无关
307:临时重定向,与302类似,只是强制要求使用POST方法
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
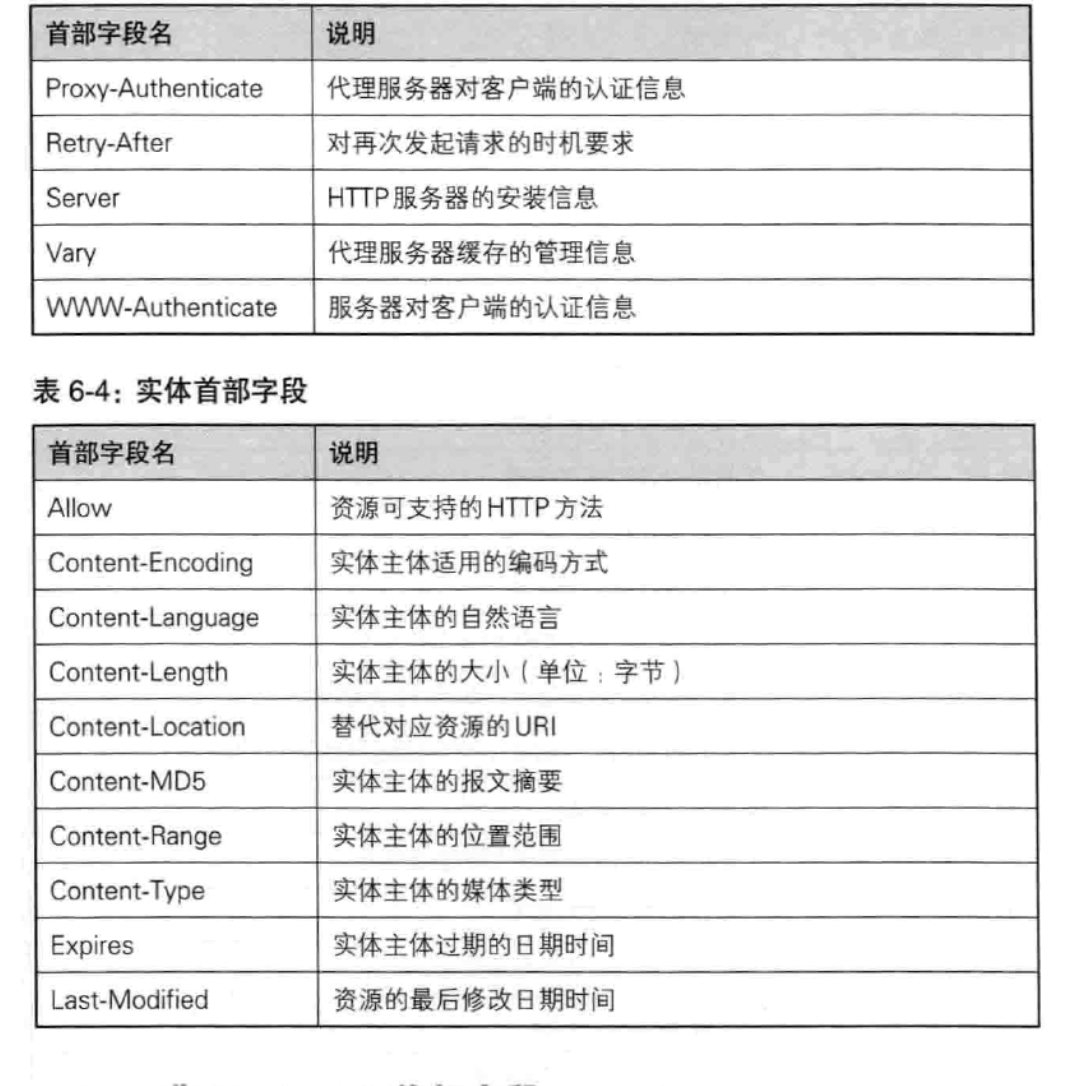
HTTP首部字段
http协议的请求和响应报文中必需包含http首部。
首部字段类型主要有4种:
通用首部字段(General Header Fields),
请求首部字段(Request Header Fields),
响应首部字段(Response Header Fields),
实体首部字段(Entity Header Fields).
实体首部字段,补充了资源内容更新时间等与实体相关的信息。
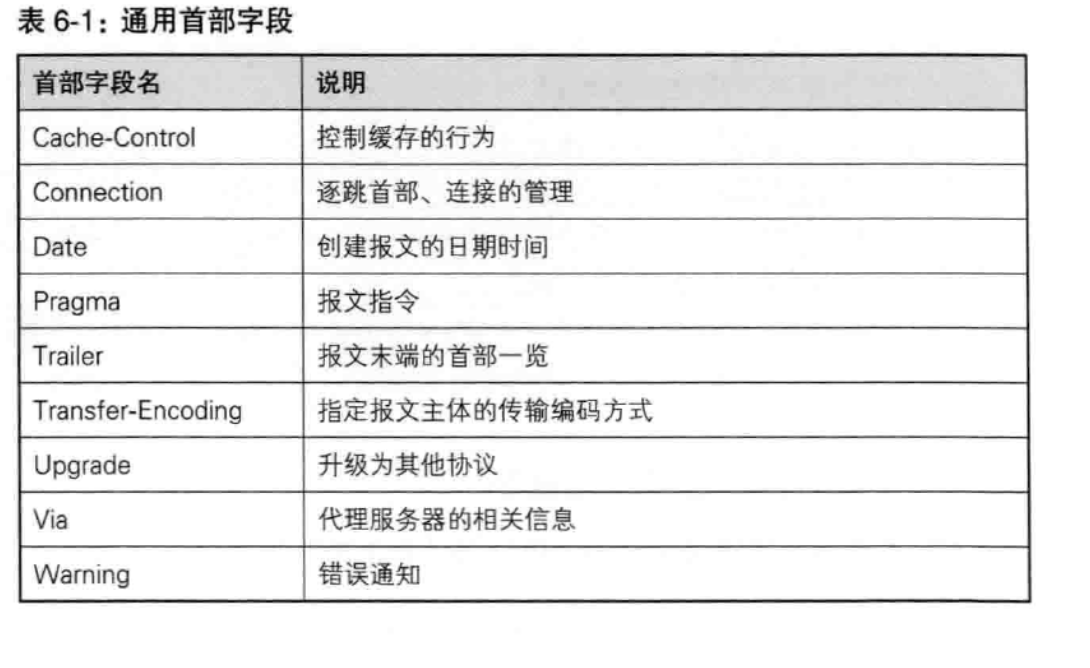
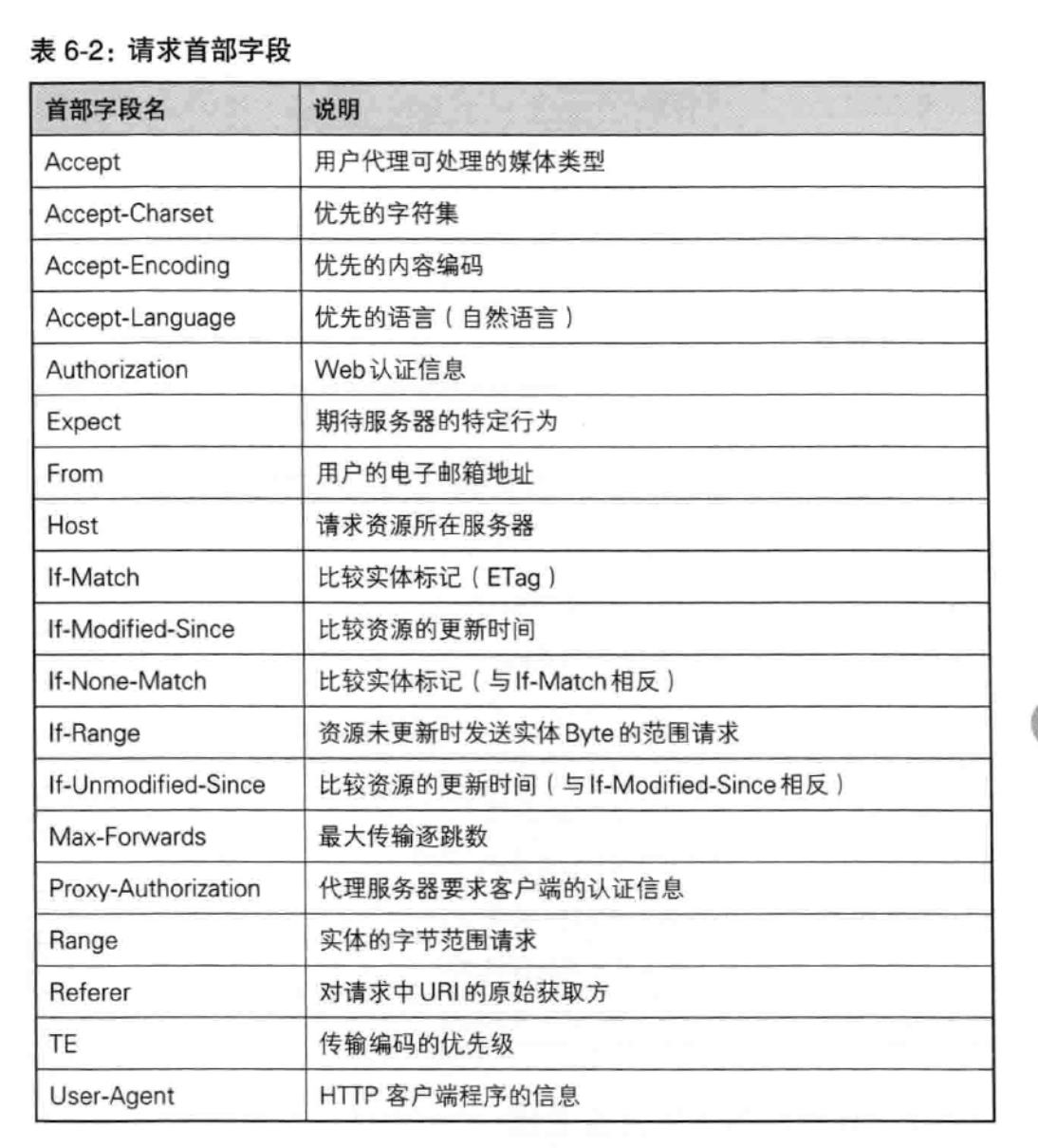

header首部字段详解
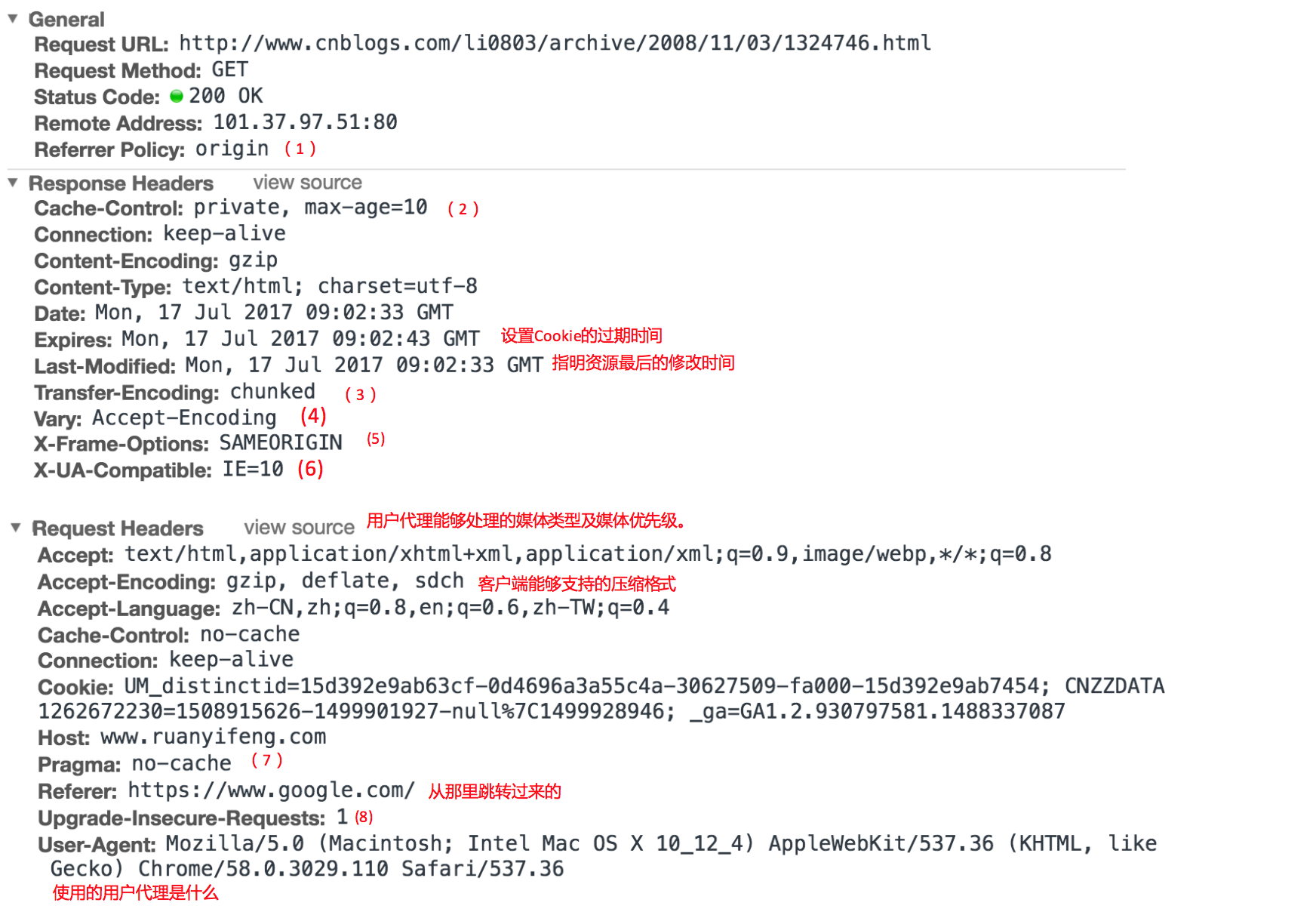
Referrer Policy(1)
用来设置引用页面的时候做一些设置的事情。
- no-referrer:整个 Referer 首部会被移除。访问来源信息不随着请求一起发送.
- no-referrer-when-downgrade (默认值)
在没有指定任何策略的情况下用户代理的默认行为。在同等安全级别的情况下,引用页面的地址会被发送(HTTPS->HTTPS),但是在降级的情况下不会被发送 (HTTPS->HTTP)。 - origin:在任何情况下,仅发送文件的源作为引用地址。例如 https://example.com/page.html 会将 https://example.com/ 作为引用地址。
- origin-when-cross-origin:对于同源的请求,会发送完整的URL作为引用地址,但是对于非同源请求仅发送文件的源。
- same-origin:对于同源的请求会发送引用地址,但是对于非同源请求则不发送引用地址信息。
- strict-origin:在同等安全级别的情况下,发送文件的源作为引用地址(HTTPS->HTTPS),但是在降级的情况下不会发送 (HTTPS->HTTP)。
- strict-origin-when-cross-origin:对于同源的请求,会发送完整的URL作为引用地址;在同等安全级别的情况下,发送文件的源作为引用地址(HTTPS->HTTPS);在降级的情况下不发送此首部 (HTTPS->HTTP)。
- unsafe-url:无论是同源请求还是非同源请求,都发送完整的 URL(移除参数信息之后)作为引用地址。
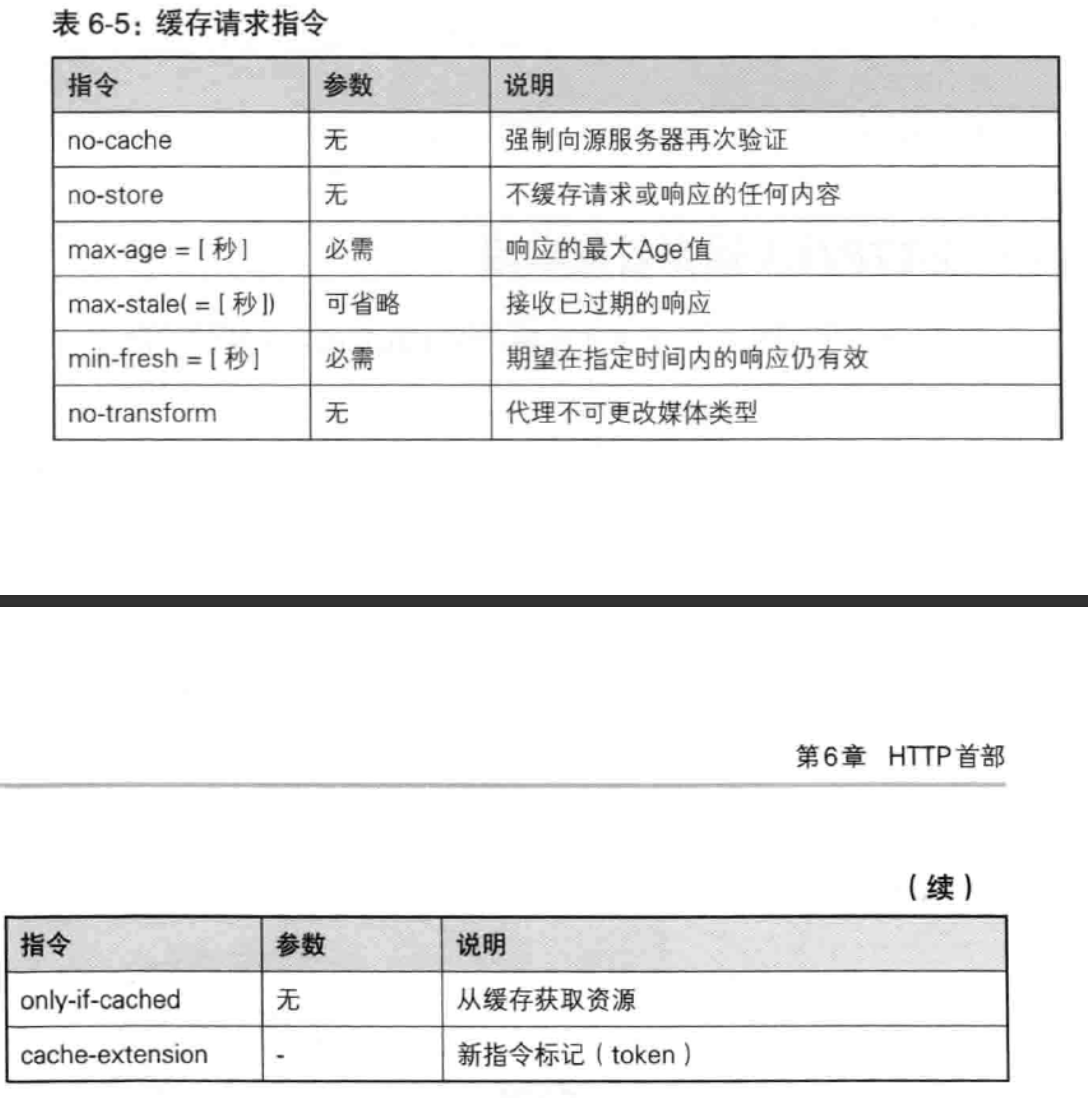
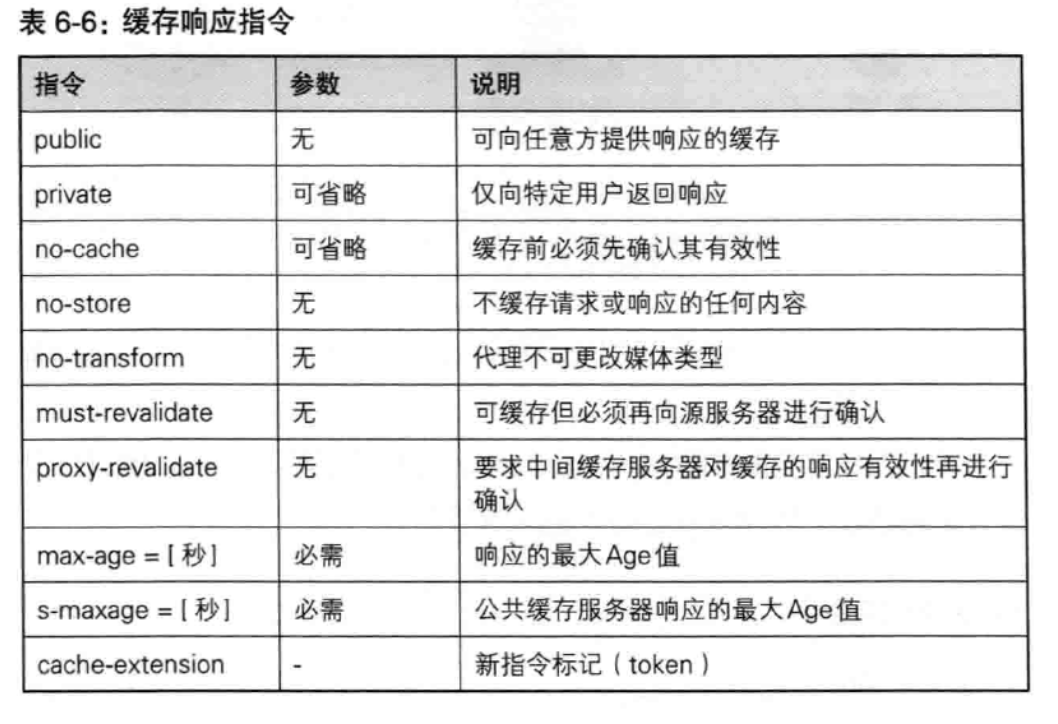
Cache-Control指令(2)
客户端缓存相关
transfer-encoding(3)
内容传输相关
transfer-encoding的可选值有:chunked,identity;从字面意义可以理解,前者指把要发送传输的数据切割成一系列的块数据传输,后者指传输时不做任何处理,自身的本质数据形式传输。举个例子,如果我们要传输一本“红楼梦”小说到服务器,chunked方式就会先把这本小说分成一章一章的,然后逐个章节上传,而identity方式则是从小说的第一个字按顺序传输到最后一个字结束。
vary信息(4)
请求时缓存策略相关
流行的缓存代理服务器,像squid,通常会根据请求的URI和vary response header的内容产生一个hash值。当缓存服务器接收到一个请求的时候,它会根据输入产生一个hash,之后检查缓存看是否已经有这个资源在硬盘上或者在内存中匹配这个hash值。缓存服务器以此来判断命中与否。
而vary response header告诉缓存服务器使用什么判断一个请求的资源是新的客户端来源还是老的客户端来源的。
Vary: Accept-Encoding
Vary: Accept-Encoding,User-Agent
Vary: X-Some-Custom-Header,Host
Vary: *
vary的意义在于告诉代理服务器/缓存/CDN,如何判断请求是否一样,vary中的组合就是服务器/缓存/CDN判断的依据,比如Vary中有User-Agent,那么即使相同的请求,如果用户使用IE打开了一个页面,再用Firefox打开这个页面的时候,CDN/代理会认为是不同的页面,如果Vary中没有User-Agent,那么CDN/代理会认为是相同的页面,直接给用户返回缓存的页面,而不会再去web服务器请求相应的页面。
如:Vary: Accept-Encoding,User-Agent,这个的意思是告诉缓存服务器,判读是否是同一个请求需要使用”客户端编码+代理“相等才表示同一个网页请求。如果使用不同浏览器(不同代理)一个Firefox,一个ie打开同一个网页,那么“客户端编码+代理”是一定不相等的,他们的代理不同。
X-Frame-Options(5)
Iframe安全相关
X-Frame-Options HTTP 响应头是用来给浏览器指示允许一个页面可否在 \
X-UA-Compatible(6)
浏览器兼容问题相关
为什么要用X-UA-Compatible?
在IE8刚推出的时候,很多网页由于重构的问题,无法适应较高级的浏览器,所以使用X-UA-Compatible标签强制IE8采用低版本方式渲染。
使用下面这段代码后,开发者无需考虑网页是否兼容IE8浏览器,只要确保网页在IE6、IE7下的表现就可以了。
建议使用下面的X-UA-Compatible标签:
IE=edge告诉IE使用最新的引擎渲染网页,chrome=1则可以激活Chrome Frame。
IE=edge告诉IE,如果是IE8就用ie8,如果是IE6就用IE6.
Pragma (7)
页面缓存相关
作用: 防止页面被缓存, 在HTTP/1.1版本中,它和Cache-Control:no-cache作用一模一样
Pargma只有一个用法, 例如: Pragma: no-cache
注意: 在HTTP/1.0版本中,只实现了Pragema:no-cache, 没有实现Cache-Control。
Pargma与cache-control的区别:
Cache-Control: no-cache:这个很容易让人产生误解,使人误以为是响应不被缓存。实际上Cache-Control: no-cache是会被缓存的,只不过每次在向客户端(浏览器)提供响应数据时,缓存都要向服务器评估缓存响应的有效性。
Pragma: no-cache可以应用到http 1.0 和http 1.1,而Cache-Control: no-cache只能应用于http 1.1.
Cache-Control: no-cache是http 1.1提供的。
Upgrade-Insecure-Requests
https请求相关
只有在https下才会出现的一个头部:Upgrade-Insecure-Requests:1
该指令用于让浏览器自动升级请求从http到https,用于大量包含http资源的http网页直接升级到https而不会报错.简洁的来讲,就相当于在http和https之间起的一个过渡作用.
举例: \ 在https中该资源会被理解为
在https中该资源会被理解为
\ 而不会报错
而不会报错
Upgrade-Insecure-Requests:1。则是告诉服务器,自己支持这种操作,也就是我能读懂你服务器发过来的上面这条信息,并且在以后发请求的时候不用http而用https。
age,ETag
Age:源服务器在多久前创建了响应,单位秒。如果有缓存,则表示缓存后再次发起认证到认证完成的时间。Age:600。
ETag:资源被缓存时,就会被分配唯一性标识。
访问谷歌英文版和中文版http://google.com返回的ETag是不一样的,所以仅凭URI指定缓存的资源是相当困难的。
Location重定向
Location:http://baidu.com
使用首部字段Location可以将响应接收方引导至某个与请求URI位置不同的资源,说白了就是访问网页后重定向。
Ranges,Content-Length(断点续传,与多线程下载)
服务器返回:Content-Length:20668,表示客户端请求的服务器资源大小为20668字节。
客户端请求:Ranges:0-100,表示客户端向服务器请求资源,只需要返回资源大小的0-100个字节。
这两个组合起来就可以编写断点续传或多线程现在一个很大的文件了。
先发起一个请求,服务端返回总的资源大小,然后客户段在分段请求就OK了。