一、基本原理
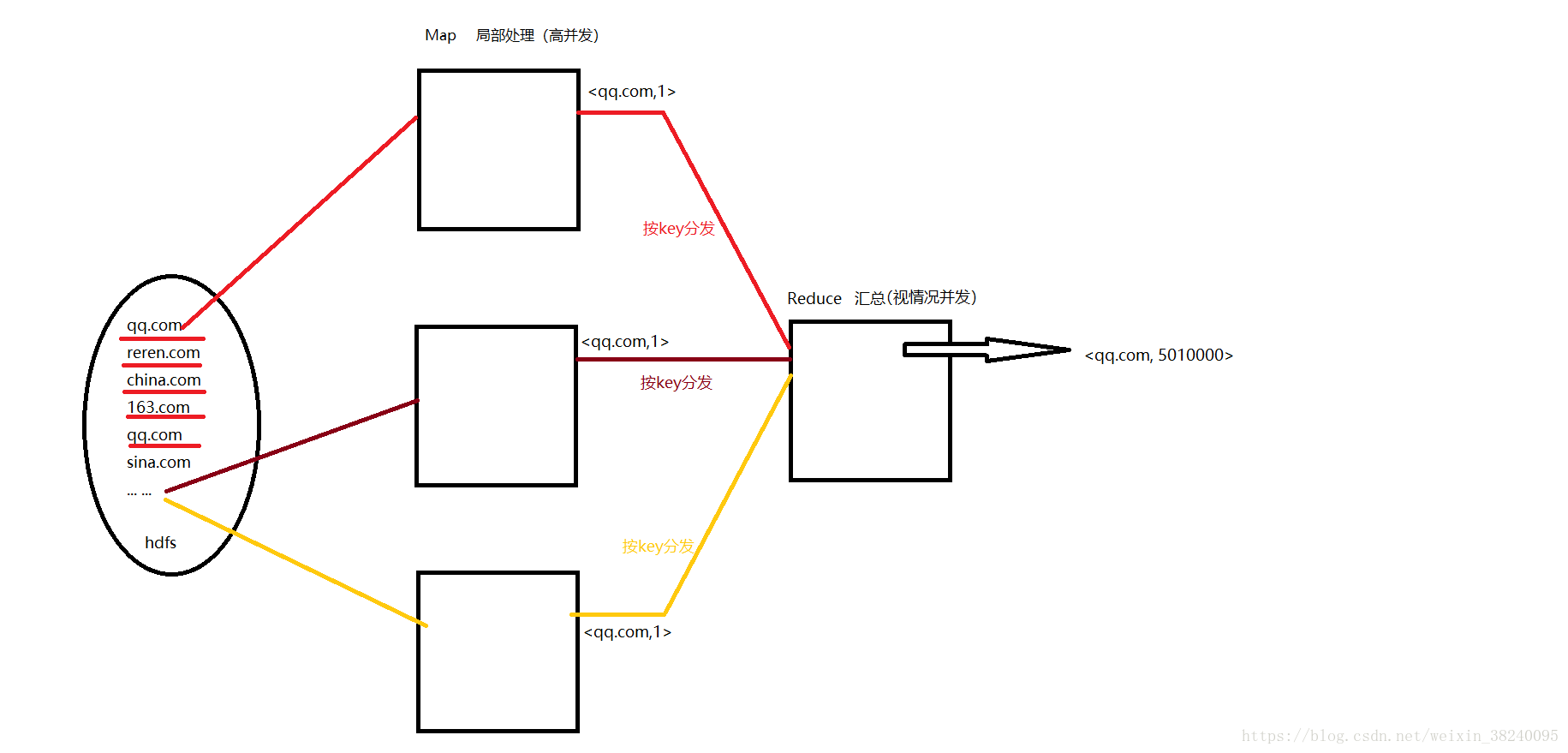
1.思想引入 : log count
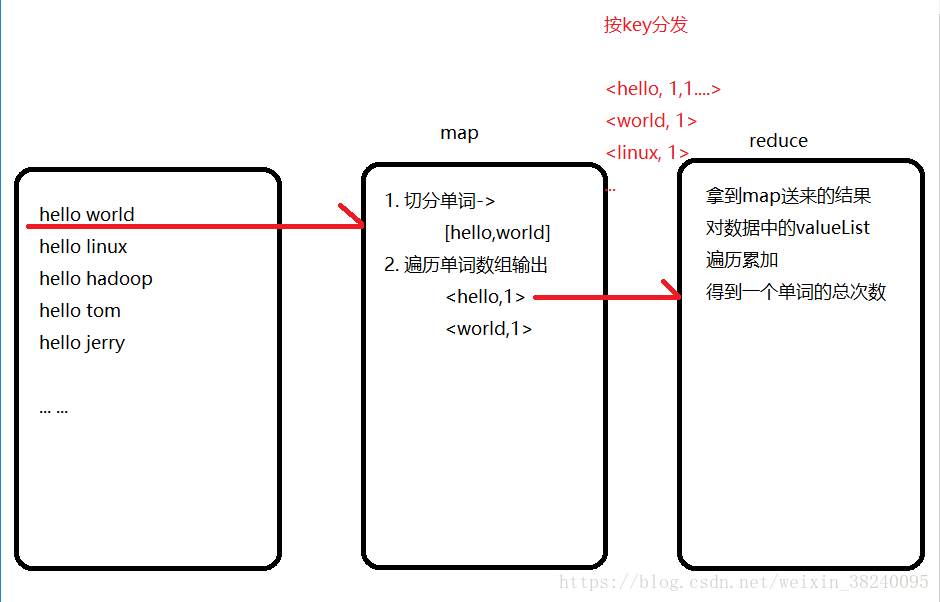
2.简单Demo : words count
二、使用细节
-
通用规范
数据通过网络在节点之间传输需要序列化,但JDK自带序列化冗余。为提高海量键值对的传输,Hadoop实现了精简序列化类型:LongWritable(Long), Text(String), NulWritable(Null NullWritable.get()),… -
Map规范
extends Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>,需要指定四个类型
默认情况下:
(1) mapper的输入输出都是以Entry<key,value>的形式封装
(2) KEYIN是要处理的文本中每一行的起始偏移量,VALUEIN是每一行的文本内容
(3)需要重写map(KEYIN,VALUEIN,Context),每读一行数据就自动调用一次该业务逻辑
-
Reduce规范
extends Reduce<KEYIN, VALUEIN, KEYOUT, VALUEOUT>,需要与map的输出类型相对应
需要重写reduce(KEYIN, Iterable<VALUEIN>, Context),在map阶段完成后,按key分组(group),传递给对应Reducer一个统计组<key,values{…}>后调用一次业务逻辑
-
描述MapReduce的作业Runner
注:如何将MapReduce作业提交至集群运行
hadoop jar {Runner全路径全限名}
jar[main()->job->{Mapper,Reducer,srcPath,resPath}]+配置描述分发到节点 -
MapReduce中传输自定义数据类型(Bean->setter+getter)
(1) 要在Hadoop的各个节点之间传输,就必须实现其序列化机制,实现 Writable接口 ,重写两个方法:
readFields(DataInput):将Bean序列化到传输流中
write(DataOutput):从传输流中还原为Bean(2) Hadoop的序列化机制与原生JDK不同,只传输Bean本身,而不传输继承结构信息,只要数据以减少冗余
(3)序列化还原时,底层使用反射->需要无参构造方法
(4)如果要实现自定义排序,则必须实现WritableComparable<T>接口。注:不能使用Writable+Comparable<T>组合,否则抛出initialization异常
-
分区(partition)
(1)在Map阶段作用,指定输出到特定Reduce的来源数据(即溢出文件分区块)规则
(2)MapReduce默认使用HashPartitioner,将key的HashCode与最大整型"按位与"&后"取模"%作为分区号public class HashPartitioner<K, V> extends Partitioner<K, V> { /** Use {@link Object#hashCode()} to partition. */ public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }(3)自定义分区,配合自定义数量的并发Reducer
extends Partitioner<KEY,VALUE>,重写getPartition(KEY,VALUE,int)方法返回整型分区码标识
(4)在Runner中,job.setPartitioner(xxxPartitioner.class)启动自定义分区 -
自定义Reducer的并发进程数,决定了最大分区数
在Runner中,job.setNumReduceTasks(int)
注:参数对应Partitioner中定义的分组数量(Partitioner.getPartition()的第三个参数numPartitions),默认是1,所有数据都会送给该Reducer,全写在part-r-000000 -
分组(group)
(1)在Reduce阶段作用,来源数据被 分组器 按"key"的 “比较逻辑” 区分为组,封装为Iterable<VALUE> 调用一次reduce(KEY,Iterable,Context)
(2)MapReduce默认按key的HashCode进行分组
(3)自定义分组,即定义key的区分规则
extends WritableComparator
(4)在Runner中,job.setGroupingComparator(xxxGroupComparator.class)启动自定义分组
注:通过自定义的GroupComparator进行分组后的同组“key”,与使用属性进行自定义equals()情况类似,仅是在自定义逻辑上的相等,并不是同一个对象的两个引用(即地址相等) -
排序(sort) --待整理
-
锦上添花——聚合(combine) --待整理




三、切片
- Map并发进程数不是由Block的大小决定的,而是基于切片
- 切片Split是一个逻辑概念,从起始偏移量到结束偏移量之间的“段”,一个切片对应一个Map进程。
- 切片的具体大小可以根据所处理的文件大小调整。
例如:
一个文件块默认大小为128M,与一个切片对应就比较合适,独占一个map
若一个小文件只占10k,则一个切片与若干个对应就比较合适,共享一个map - FileInputFormat对split规划源码分析

四、全貌
FileInputFormat/FileOutputFormat 默认是 TextInputFormat/TextOutputFormat(只能处理文本文件)

五、Shuffle机制
说明:
1. 每个map进程都有一个环形内存缓冲区,用于暂存输出(输出记录结构由三部分组成:分区号,key,value)。默认大小100MB( 由io.sort.mb指定 ),一旦达到阈值α( 由io.sort.spill.percent指定 ),就由一个后台线程封锁α-缓冲区并将其内容写到磁盘指定目录( 由mapred.local.dir )下的一个新建溢出文件中。 此时,若有新的输出记录,就暂存至1-α-缓冲区中。
2. 写磁盘前,要作[聚合]、按分区划分、分区内排序的工作
3. 等最后一条记录写完,归并全部溢出文件为一个[聚合]、按分区划分、区内有序的文件
