都说这里很巧妙,那么巧妙在哪里呢?从需求出发,来分析为什么要这么做。
队列介绍:
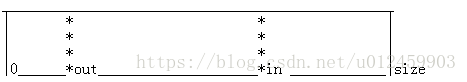
1.0 为了确保 环形队列的size = in - out 始终计算正确.
如果每次增加in和out后都对in 和 out 取模,即in = in%size; 以确保 0<in<size 0<out<size
那么在一种情况下:当in因为超出而被取模给截短了,size的计算就不对了。(假设size =100)
in = size +5; out= 10+5;再取模, in=5;out=15, in -out = -15
所以让in 和 out只增加,不取模,就不会出现 in < out,但是还有一个数据类型溢出的问题。如果in无限增加溢出数据类型了,怎么办?
有一个规律,当溢出后的数据 in 小于 out, 那么unsigned (in -out) 和当in没有溢出时的结果,是一样的。有证明https://blog.csdn.net/jiangfuqiang/article/details/16979847,所以满足了这个条件,也就自然规避了数据类型溢出所带来的问题了。为满足这个条件,在入队了和出队列,让in out 增加之前,都有对增加的量进行判断限制。函数里面有 min取最小值的操作部分
小实验:
#include<stdlib.h>
#include<stdio.h>
int main()
{
unsigned int in= -1;
unsigned int out = 0;
in +=5;
out +=5; //确保数据a<b,这是一个前提
unsigned int c = in -out;
printf("a:%#x b:%#x c:%#x\n\n",in,out,c);
}所以出于这个原因用两个 unsing in 一直增长,溢出也无关系
2.0 简化取模运算提高效率
因为in 和 out自增长,肯定会大于size,所以为了获取in 和 out 在队列中对应的位置,
还是要用到取模 in_postion = in%size; out_postion = out%postion. 这个postion只是一个临时用来获取相对位置的。上面这两个取模没法避免,但是有一种方法可以提高效率:
如果 size=2^n , 那么:in%size = in&(size -1)
将取模运算改为位运算,为了利用这点,就要求队列的size都为2的n次方
3.0 怎么确保 size为2的幂?
先要判断是不是2的幂:
判断n是否是2的幂,这里又秀了一把,不是用普通的循环%2方法来判断
若n为2的次幂, 则 n & (n-1) == 0,也就是n和n-1的各个位都不相同。例如 8(1000)和7(0111)
若n不是2的次幂, 则 n & (n-1) != 0,也就是n和n-1的各个位肯定有相同的,例如7(0111)和6(0110)
static inline bool is_power_of_2(uint32_t n)
{
return (n != 0 && ((n & (n - 1)) == 0));
}若不是2的幂,向上取整为2的幂:
如果设定的缓冲区大小不是2的次幂,则向上取整为2的次幂,例如:设定为5,则向上取为8。上面提到整数n是2的次幂,则其二进制模式为100...,故如果正数k不是n的次幂,只需找到其最高的有效位1所在的位置(从1开始计数)pos,然后1 << pos即可将k向上取整为2的次幂。实现如下:
static inline uint32_t roundup_power_of_2(uint32_t a)
{
if (a == 0)
return 0;
uint32_t position = 0;
for (int i = a; i != 0; i >>= 1)
position++;
return static_cast<uint32_t>(1 << position);
}4.0读写屏障强制内存访问次序 (这个就是无锁的单线程生产者消费者模式),作用于编译器
https://blog.csdn.net/ctthuangcheng/article/details/8893579
贴上部分源码。这个是在2.6内核中的代码,看ubuntu3.2的内核,竟然没找到kfifo.c........
1: struct kfifo {
2: unsigned char *buffer; /* the buffer holding the data */ //要读或写的数据指针
3: unsigned int size; /* the size of the allocated buffer */ //要读或写的数据长度
4: unsigned int in; /* data is added at offset (in % size) */
5: unsigned int out; /* data is extracted from off. (out % size) */
6: spinlock_t *lock; /* protects concurrent modifications */
7: };
unsigned int __kfifo_put(struct kfifo *fifo,
2: const unsigned char *buffer, unsigned int len)
3: {
4: unsigned int l;
5:
6: len = min(len, fifo->size - fifo->in + fifo->out);
7:
8: /*
9: * Ensure that we sample the fifo->out index -before- we
10: * start putting bytes into the kfifo.
11: */
12:
13: smp_mb();
14:
15: /* first put the data starting from fifo->in to buffer end */
16: l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
17: memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
18:
19: /* then put the rest (if any) at the beginning of the buffer */
20: memcpy(fifo->buffer, buffer + l, len - l);
21:
22: /*
23: * Ensure that we add the bytes to the kfifo -before-
24: * we update the fifo->in index.
25: */
26:
27: smp_wmb();
28:
29: fifo->in += len;
30:
31: return len;
32: }
unsigned int __kfifo_get(struct kfifo *fifo,
2: unsigned char *buffer, unsigned int len)
3: {
4: unsigned int l;
5:
6: len = min(len, fifo->in - fifo->out);
7:
8: /*
9: * Ensure that we sample the fifo->in index -before- we
10: * start removing bytes from the kfifo.
11: */
12:
13: smp_rmb();
14:
15: /* first get the data from fifo->out until the end of the buffer */
16: l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
17: memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
18:
19: /* then get the rest (if any) from the beginning of the buffer */
20: memcpy(buffer + l, fifo->buffer, len - l);
21:
22: /*
23: * Ensure that we remove the bytes from the kfifo -before-
24: * we update the fifo->out index.
25: */
26:
27: smp_mb();
28:
29: fifo->out += len;
30:
31: return len;
32: }