第十九天 – MongoDB – MapReduce操作Mysql、MongoDB
文章目录
一、MongoDB
简介
MongoDB是一个NoSQL数据库,是一个基于分布式文件存储的数据库
它的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
*面向集合存储,易存储对象类型的数据。
*模式自由。
*支持动态查询。
*支持完全索引,包含内部对象。
*支持查询。
*支持复制和故障恢复。
*使用高效的二进制数据存储,包括大型对象(如视频等)。
*自动处理碎片,以支持云计算层次的扩展性。
*支持多种语言。
*文件存储格式为BSON(一种JSON的扩展)。
*可通过网络访问
下载
可通过MongoDB官网下载tgz安装包,最新版本是4.0,我使用3.2.1版本。
安装
下载后通过Xftp上传至Linux,解压即可
tar -zxvf mongodb-linux-x86_64-3.2.1.tgz
配置环境变量
vi .bash_profile 添加以下三条
MONGODB_HOME=/home/bigdata/mongodb-linux-x86_64-3.2.1
PATH= MONGODB_HOME/bin
export MONGODB_HOME
重新加载环境变量文件 source .bash_profile
配置启动项
-
进入mongdb的安装目录
cd mongodb-linux-x86_64-3.2.1/
-
创建文件夹data
mkdir data
-
创建文件mongdb.log
touch mongdb.log
-
创建配置文件mongo.cfg并编辑内容
vi mongo.cfg
添加以下两条配置项
dbpath=/home/bigdata/mongodb-linux-x86_64-3.2.1/data/
logpath=/home/bigdata/mongodb-linux-x86_64-3.2.1/mongodb.log
启动mongodb服务
mongod -f ./mongo.cfg &
启动mongodb客户端
mongo -host localhost -port 27017
mongodb基本操作
use hadoop; 切换数据库,如果没有则创建切换,但并不一定创建(当库中有表有数据时才会真正创建)
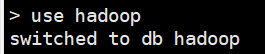
show dbs; / show databases;
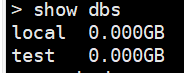
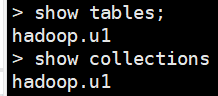
show tables; / show collections;
创建表(集合)db.hadoop.u1;
插入数据db.hadoop.u1.insert({“uname”:“zhangsan”,“age”:“16”})

db.hadoop.u1.insert({“uname”:“lisi”,“age”:“20”},{“uname”:“wangwu”,“age”:“18”})

db.hadoop.u1.find(); 查询全部

db.hadoop.u1.find({“uname”:“lisi”});

db.hadoop.u1.update({uname:{KaTeX parse error: Expected 'EOF', got '}' at position 10: eq:"lisi"}̲},{set:{age:18}});

db.hadoop.u1.updateMany({uname:{KaTeX parse error: Expected 'EOF', got '}' at position 10: eq:"lisi"}̲},{set:{age:33}});
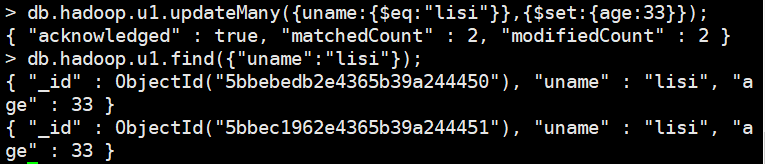
db.hadoop.u1.deleteOne({“uname”:“lisi”}); 删除单个
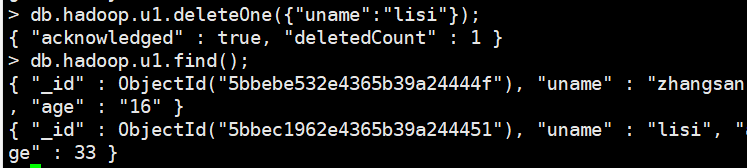
db.hadoop.u1.deleteMany({“uname”:“lisi”}); 删除匹配的多个
db.hadoop.u1.count() 查询该表的行数
二、通过MapReduce操作mysql表的复制
MysqlToMysql.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import java.io.IOException;
import java.net.URISyntaxException;
public class MysqlToMysql {
/**
* map阶段
* @author lyd
*
*/
public static class MyMapper extends Mapper<Object, UserInfo, UserInfo, Text>{
UserInfo ui = new UserInfo();
@Override
protected void map(Object key, UserInfo value,Context context)
throws IOException, InterruptedException {
//直接输出
ui.setId(value.getId());
ui.setAge(value.getAge());
context.write(ui, new Text(""));
}
}
/**
* reduce阶段
* @author lyd
*
*/
public static class MyReducer extends Reducer<Text, Text, UserInfo, Text>{
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
}
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
int counter = 0;
for (Text t : values) {
counter += Integer.parseInt(t.toString());
}
UserInfo ui = new UserInfo();
ui.setId(Integer.parseInt(key.toString()));
ui.setAge(Integer.parseInt(values.iterator().next().toString()));
context.write(ui, new Text(""));
}
@Override
protected void cleanup(Context context)
throws IOException, InterruptedException {
}
}
/**
* 驱动
* @param args
* @throws IOException
* @throws InterruptedException
* @throws ClassNotFoundException
* @throws URISyntaxException
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException {
Configuration conf = new Configuration();
//配置连接mysql的信息
DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://hadoop01:3306/test", "root", "root");
Job job = Job.getInstance(conf, "MysqlToMysql");
job.setJarByClass(MysqlToMysql.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(UserInfo.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(UserInfo.class);
job.setOutputValueClass(Text.class);
setArgs(job,args);
/* //设置jar包
job.addCacheFile(new URI("hdfs://qianfeng/db/mysql-connector-java-5.1.18.jar"));
*/
//设置DBInutFormat
String[] fields = {"id","age"};
DBInputFormat.setInput(job, UserInfo.class, "u1", null, null, fields);
//设置DBOutputFormat
// String[] fields1 = {"pid","counter"};
DBOutputFormat.setOutput(job, "u2", fields);
//提交作业
int issuccessed = job.waitForCompletion(true) ? 0 : 1;
//关闭job
System.exit(issuccessed);
}
/**
* 作业参数处理
* @param job
* @param args
*/
public static void setArgs(Job job , String[] args){
try {
if(args.length != 2){
System.out.println("argments size is not enough!!!");
System.out.println("Useage :yarn jar *.jar wordcount /inputdata /outputdata");
}
//设置输入文件路径
//FileInputFormat.addInputPath(job, new Path(args[0]));
job.setInputFormatClass(DBInputFormat.class);
//设置输出数据目录
//FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputFormatClass(DBOutputFormat.class);
} catch (Exception e) {
e.printStackTrace();
}
}
}
UserInfo.java
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
/**
* 自定义数据类型
* @author lyd
*
*/
public class UserInfo implements Writable,DBWritable{
int id;
int age;
public UserInfo(){
}
public UserInfo(int id, int age) {
this.id = id;
this.age = age;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(this.id);
dataOutput.writeInt(this.age);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.id = dataInput.readInt();
this.age = dataInput.readInt();
}
@Override
public void write(PreparedStatement ps) throws SQLException {
ps.setInt(1,this.id);
ps.setInt(2,this.age);
}
@Override
public void readFields(ResultSet rs) throws SQLException {
this.id = rs.getInt(1);
this.age = rs.getInt(2);
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "UserInfo{" +
"id=" + id +
", age=" + age +
'}';
}
}
三、通过MapReduce操作MongoDB表的复制
由于hadoop未提供直接操作MongoDB的接口,输入输出类、封装类等所以需要仿照hadoop提供的DBInputFormat等源码编写MongoDB的操作类
MongoDBInputFormat.java
import com.mongodb.MongoClient;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.*;
import org.bson.Document;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
*
* 自定义mongoDB的输入格式类
*/
public class MongoDBInputFormat<V extends MongoDBWritable> extends InputFormat<LongWritable,V> {
/**
* 默认的空的数据类型
*/
public static class NullMongoDBWritable implements MongoDBWritable, Writable{
@Override
public void write(MongoCollection collection) throws IOException {
}
@Override
public void readFields(Document document) throws IOException {
}
@Override
public void write(DataOutput out) throws IOException {
}
@Override
public void readFields(DataInput in) throws IOException {
}
}
@Override
public List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException {
// 获取mongoDB的库
MongoDatabase mongoDatabase = new MongoClient("SZ01", 27017).getDatabase("hadoop");
// 用户mongo的连接读取对应的表
MongoCollection mongoCollection = mongoDatabase.getCollection("persons");
// 获取mongoCollection的总行数
long count = mongoCollection.count();
int perSplitSize = 2; // 分片大小
long splitSize = count / perSplitSize; // 分片个数
List<InputSplit> splits = new ArrayList<>();
for(int i = 0; i < splitSize; i++){
if(i + 1 == splitSize){
splits.add(new MongoDBInputSplit(i * perSplitSize, count ));
}else{
splits.add(new MongoDBInputSplit(i * perSplitSize, i * perSplitSize + perSplitSize));
}
}
return splits;
}
/**
* 用于封装分片的信息
*/
public static class MongoDBInputSplit extends InputSplit implements Writable{
private long start = 0; // 分片的起始位置
private long end = 0; // 分片的结束位置
public long getStart() {
return start;
}
public void setStart(long start) {
this.start = start;
}
public long getEnd() {
return end;
}
public void setEnd(long end) {
this.end = end;
}
public MongoDBInputSplit(){
}
public MongoDBInputSplit(long start, long end) {
this.start = start;
this.end = end;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(this.start);
out.writeLong(this.end);
}
@Override
public void readFields(DataInput in) throws IOException {
this.start = in.readLong();
this.end = in.readLong();
}
@Override
public long getLength() throws IOException, InterruptedException {
return this.end - this.start;
}
@Override
public String[] getLocations() throws IOException, InterruptedException {
return new String[0];
}
}
@Override
public RecordReader<LongWritable, V> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
return new MongoDBRecordReader(split, context);
}
}
MongoDBRecordReader.java
import com.mongodb.MongoClient;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.util.ReflectionUtils;
import org.bson.Document;
import java.io.IOException;
/**
* 用于封装读出记录的信息
* @param <V>
*/
public class MongoDBRecordReader<V extends MongoDBWritable> extends RecordReader<LongWritable, V> {
private Configuration conf;
private MongoDBInputFormat.MongoDBInputSplit splits; // 分片
private LongWritable key;
private V value; // value
private int index; // 索引
private MongoCursor mongoCursor; // 数据游标
public MongoDBRecordReader(){
}
public MongoDBRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
initialize(split, context);
}
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
this.splits = (MongoDBInputFormat.MongoDBInputSplit)split;
key = new LongWritable();
// 初始化value
Class className = context.getConfiguration().getClass("mapreduce.mongoDB.input.format.class", MongoDBWritable.class);
value = (V)ReflectionUtils.newInstance(className, context.getConfiguration());
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if(mongoCursor == null){
// 获取mongoDB的库
MongoDatabase mongoDatabase = new MongoClient("SZ01", 27017).getDatabase("hadoop");
// 用户mongo的连接读取对应的表
MongoCollection mongoCollection = mongoDatabase.getCollection("persons");
// 获取Cursor
mongoCursor = mongoCollection.find().skip((int)this.splits.getStart()).limit((int)this.splits.getLength()).iterator();
}
// 保证Cursor一定不为空
boolean isNext = mongoCursor.hasNext(); // 是否有下一个元素
if(isNext){
Document document = (Document)mongoCursor.next();
// 下一个key
this.key.set(this.splits.getStart() + index);
this.index ++;
// 下一个value
this.value.readFields(document);
}
return isNext;
}
@Override
public LongWritable getCurrentKey() throws IOException, InterruptedException {
return this.key;
}
@Override
public V getCurrentValue() throws IOException, InterruptedException {
return this.value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
@Override
public void close() throws IOException {
mongoCursor.close();
}
}
MongoDBOutputFormat.java
import com.mongodb.MongoClient;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 自定义mongoDB的输出格式类
*/
public class MongoDBOutputFormat<V extends MongoDBWritable> extends OutputFormat<NullWritable, V> {
@Override
public RecordWriter<NullWritable, V> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
return new MongoDBRecordWriter<>(context);
}
/**
* 用于封装写的记录信息
* @param <V>
*/
public static class MongoDBRecordWriter<V extends MongoDBWritable> extends RecordWriter<NullWritable, V>{
MongoCollection mongoCollection = null;
public MongoDBRecordWriter(TaskAttemptContext context){
MongoDatabase mongoDatabase = new MongoClient("SZ01", 27017).getDatabase("hadoop");
// 用户mongo的连接读取对应的表
mongoCollection = mongoDatabase.getCollection("result");
}
@Override
public void write(NullWritable key, V value) throws IOException, InterruptedException {
// 写到mongoDB
value.write(mongoCollection);
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
}
}
/**
* 检测输出空间
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
public void checkOutputSpecs(JobContext context) throws IOException, InterruptedException {
}
@Override
public OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {
//return new FileOutputCommitter(null, context);
return new FileOutputCommitter(FileOutputFormat.getOutputPath(context), context);
}
}
接口MongoDBWritable.java
import com.mongodb.client.MongoCollection;
import org.bson.Document;
import java.io.IOException;
public interface MongoDBWritable {
/**
* 将数据写入到mango中
* @param collection
* @throws Exception
*
*/
public void write(MongoCollection collection) throws IOException;
/**
* 将mongo中的数据读出
* @param document
* @throws Exception
*
*/
public void readFields(Document document) throws IOException;
}
MyMongoDBWritable.java
import com.mongodb.client.MongoCollection;
import org.apache.hadoop.io.Writable;
import org.bson.Document;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class MyMongoDBWritable implements Writable, MongoDBWritable{
private String uname;
private Integer age;
private String sex = "";
private int counter = 1;
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.uname);
if(this.age == null){
out.writeBoolean(false);
}else {
out.writeBoolean(true);
out.writeInt(this.age);
}
out.writeUTF(this.sex);
out.writeInt(this.counter);
}
@Override
public void readFields(DataInput in) throws IOException {
this.uname = in.readUTF();
if(in.readBoolean()){
this.age = in.readInt();
}else{
this.age = null;
}
this.sex = in.readUTF();
this.counter = in.readInt();
}
/**
* 写最终结果到mongo中
*/
@Override
public void write(MongoCollection collection) throws IOException {
// 获取Object
Document document = new Document("title","count")
.append("age",this.age)
.append("counter", this.counter);
collection.insertOne(document);
}
/**
* 从mongo中读取数据
* @param document
* @throws IOException
*/
@Override
public void readFields(Document document) throws IOException {
this.uname = document.get("name").toString();
if(document.get("age") == null){
this.age = null;
}else {
this.age = Double.valueOf(document.get("age").toString()).intValue();
}
}
public String getUname() {
return uname;
}
public void setUname(String uname) {
this.uname = uname;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public int getCounter() {
return counter;
}
public void setCounter(int counter) {
this.counter = counter;
}
}
测试类MongoDBTest.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MongoDBMRTest {
public static class MyMapper extends Mapper<LongWritable,MyMongoDBWritable, IntWritable,IntWritable>{
@Override
protected void map(LongWritable key, MyMongoDBWritable value, Context context) throws IOException, InterruptedException {
// 获取value中的年龄
if(value.getAge() == null){
System.out.println("uname:"+value.getUname());
return;
}
context.write(new IntWritable(value.getAge()), new IntWritable(1));
}
}
public static class MyReducer extends Reducer<IntWritable,IntWritable, NullWritable, MyMongoDBWritable> {
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable v : values){
count += v.get();
}
MyMongoDBWritable myMongoDBWritable = new MyMongoDBWritable();
myMongoDBWritable.setAge(key.get());
myMongoDBWritable.setCounter(count);
context.write(null, myMongoDBWritable);
}
}
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
//设置conf中到的参数
conf.setClass("mapreduce.mongoDB.input.format.class",MyMongoDBWritable.class
,MongoDBWritable.class);
Job job = Job.getInstance(conf, "mongoDemo");
job.setJarByClass(MongoDBMRTest.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(MyMongoDBWritable.class);
//设置输入输出格式类
job.setInputFormatClass(MongoDBInputFormat.class);
job.setOutputFormatClass(MongoDBOutputFormat.class);
//提交作业
int issuccessed = job.waitForCompletion(true) ? 0 : 1;
//关闭job
System.exit(issuccessed);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}