1、安装
依赖库是numpy和scipy,可以直接pip install numpy, pip install scipy 进行安装
然后安装scikit-learn:
Pip install scikit-learn
官网:http://scikit-learn.org/stable/
上面有很多教程
特点是:datasets很牛逼,可以广泛使用到其他各个模块中,比如tensorflow中。
2、Sklearn训练方法三部曲
通用训练方法:
- 准备数据,sklearn有非常多的datasets,可以现成的拿来用
import numpy as np
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
iris_X = iris.data ##150x4
iris_y = iris.target ##150, 3 kinds of targets, 0,1,2
##训练数据和测试数据拆分,同时打乱训练数据
X_train,X_test,y_train,y_test = train_test_split(iris_X,iris_y,test_size=0.3)
- 创建训练方法类并训练
##训练数据
knn = KNeighborsClassifier()
knn.fit(X_train,y_train)
- 采用训练好的类来预测数据
##输出结果
print(knn.predict(X_test))
print(y_test)
3、Sklearn中的datasets
可以直接load数据,也可以创建虚拟数据用来训练你设计好的model:
网址有:http://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
##loaded_data = datasets.load_boston()
##data_X = loaded_data.data
##data_y = loaded_data.target
X,y=datasets.make_regression(n_samples=100,n_features=1,n_targets=1,noise=1)
4、Sklearn的model中的属性和功能
#print(model.predict(data_X[:4,:])) ##预测结果
#print(data_y[:4])
#print(model.coef_) ##输出x的系数
#print(model.intercept_) ##输出y轴的截距
#print(model.get_params()) ##输出model的训练参数,如果没有设置那么是输出默认参数
print(model.score(data_X,data_y)) ##打分函数,针对不同的model有不同的打分模型
5、Sklearn中的各个model
(1)Perceptron模型
from sklearn.linear_model import Perceptron ###原始的感知器模型
##create model and train
ppn = Perceptron(n_iter=40,eta0=0.1,random_state=0)
ppn.fit(X_train_std,y_train)
(2)logisticRegression模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C=1000.0,random_state=0) ##这里C表示正则化参数
lr.fit(X_train_std,y_train)
>>> lr.predict_proba([X_test_std[0,:]])
array([[ 2.05743774e-11, 6.31620264e-02, 9.36837974e-01]])
(3)SVM
from sklearn.svm import SVC
svm = SVC(kernel='linear',C=1.0,random_state=0)
svm.fit(X_train_std,y_train)
y_pred = svm.predict(X_test_std)
(4)非线性的SVM,通过指定不同的kernel来实现
from sklearn.svm import SVC
svm = SVC(kernel='rbf',random_state=0,gamma=0.10,C=10.0)
svm.fit(X_xor,y_xor)
(5)决策树模型 decisionTree
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',max_depth=3,random_state=0)
tree.fit(X_train,y_train)
y_pred = tree.predict(X_test)
(6)随机森林算法 random forest
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(criterion='entropy',n_estimators=10,random_state=1,n_jobs=2)
forest.fit(X_train,y_train)
y_pred = forest.predict(X_test)
这里参数n_estimators指的是采用多少个决策树来执行,n_jobs=2表示采用2个处理器来并行处理。
(7)k-nearest neighbor classifier,KNN算法
###model6: k-nearest neighbor classifier(KNN)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5,p=2,metric='minkowski')
knn.fit(X_train_std,y_train)
y_pred = knn.predict(X_test_std)
6、数据预处理data preprocessing
(1)丢弃掉missing data中的某一行或者某一列
采用如下函数去判别是否具有无效的数据:
import pandas as pd
from io import StringIO
csv_data = '''A,B,C,D
1.0,2.0,3.0,4.0
5.0,6.0,,8.0
0.0,11.0,12.0,'''
df = pd.read_csv(StringIO(csv_data))
>>> df
A B C D
0 1.0 2.0 3.0 4.0
1 5.0 6.0 NaN 8.0
2 0.0 11.0 12.0 NaN
>>> df.isnull().sum()
A 0
B 0
C 1
D 1
dtype: int64
>>>
最简单的处理方式是丢弃掉包含无效数据的那一行或者那一列:
>>> df.dropna()
A B C D
0 1.0 2.0 3.0 4.0
>>> df.dropna(axis=1)
A B
0 1.0 2.0
1 5.0 6.0
2 0.0 11.0
>>>
# only drop rows where all columns are NaN
>>> df.dropna(how='all')
# drop rows that have not at least 4 non-NaN values
>>> df.dropna(thresh=4)
# only drop rows where NaN appear in specific columns (here: 'C')
>>> df.dropna(subset=['C'])
(2)利用插值技术补齐丢失的数据
from sklearn.preprocessing import Imputer
imr = Imputer(missing_values='NaN',strategy='mean',axis=0)
imr = imr.fit(df)
imputed_data = imr.transform(df.values)
>>> df
A B C D
0 1.0 2.0 3.0 4.0
1 5.0 6.0 NaN 8.0
2 10.0 11.0 12.0 NaN
>>> imputed_data
array([[ 1. , 2. , 3. , 4. ],
[ 5. , 6. , 7.5, 8. ],
[ 10. , 11. , 12. , 6. ]])
>>>
这里strategy表示插值的策略,可以是均值’mean’,中值’ median’,最频繁值’ most_frequent’。
(3)将字符串属性的特征转换为数字
df = pd.DataFrame([
['green','M',10.1,'class1'],
['red','L',13.5,'class2'],
['blue','XL',15.3,'class1']])
df.columns =['color','size','price','classlabel']
>>> df
color size price classlabel
0 green M 10.1 class1
1 red L 13.5 class2
2 blue XL 15.3 class1
>>>
size_mapping={
'XL':3,
'L':2,
'M':1}
df['size']=df['size'].map(size_mapping)
>>> df
color size price classlabel
0 green 1 10.1 class1
1 red 2 13.5 class2
2 blue 3 15.3 class1
>>>
inv_size_mapping={v:k for k,v in size_mapping.items()}
df['size']=df['size'].map(inv_size_mapping)
>>> df
color size price classlabel
0 green M 10.1 class1
1 red L 13.5 class2
2 blue XL 15.3 class1
>>>
(4)将labels转换为数字
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y = class_le.fit_transform(df['classlabel'].values)
class_le.inverse_transform(y)
>>> y
array([0, 1, 0], dtype=int64)
>>> class_le.inverse_transform(y)
array(['class1', 'class2', 'class1'], dtype=object)
>>>
(5)拆分训练集为trainning set和test set
from sklearn.cross_validation import train_test_split
X,y=df_wine.iloc[:,1:].values,df_wine.iloc[:,0].values
X_train,X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=0)
(6)feature scaling
通常有两种feature scaling的方法,分别是normalization 和standardization,计算公式如下:
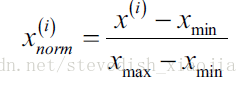
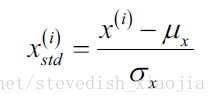
Sklearn的实现方法如下:
from sklearn.preprocessing import MinMaxScaler
mms=MinMaxScaler()
X_train_norm=mms.fit_transform(X_train)
X_test_norm = mms.fit_transform(X_test)
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_train_std = stdsc.fit_transform(X_train)
X_test_std = stdsc.fit_transform(X_test)
7、Demensionality reduction 降维技术
主要讨论3种技术,PCA,LDA,Kernel PCA
(1)PCA,decomposition模块中有PCA模块,可以直接使用
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
lr = LogisticRegression()
X_train_pca = pca.fit_transform(X_train_std)
X_test_pca = pca.fit_transform(X_test_std)
lr.fit(X_train_pca,y_train)
plot_decision_regions(X_train_pca,y_train,classifier=lr)
如果将PCA算法分布解析的话,应该是如下步骤:
##step2: splite train and test
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
X,y = df_wine.iloc[:,1:].values,df_wine.iloc[:,0].values
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
##step3: standarize trainning set
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.fit_transform(X_test)
##step4:obtain eigenpairs of cov matrix
import numpy as np
cov_mat = np.cov(X_train_std.T)
eigen_vals,eigen_vecs = np.linalg.eig(cov_mat)
eigen_pairs = [(np.abs(eigen_vals[i]),eigen_vecs[:,i]) for i in range(len(eigen_vals))]
eigen_pairs.sort(reverse=True)
##step5: genrate projection maxtri W
w= np.hstack((eigen_pairs[0][1][:,np.newaxis],
eigen_pairs[1][1][:,np.newaxis]))
##step6: do projection on X_train_std
X_train_pca = X_train_std.dot(w)
8、交叉验证
可以用来调试训练model的参数,可以调试X的属性,可以用来调试model,最终找到合适的参数。
方法1:
##自动将X和y分成5组train和test data
scores = cross_val_score(knn,X,y,cv=5,scoring='accuracy')
print(scores.mean())
##方法2: 生成model参数和score的曲线
from sklearn.cross_validation import cross_val_score
import matplotlib.pyplot as plt
k_range = range(1,31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn,X,y,cv=10,scoring='accuracy') #for classfication
#loss = -cross_val_score(knn,X,y,cv=10,scoring='mean_squared_error') ##for regression
k_scores.append(scores.mean())
plt.plot(k_range,k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
9、Sklearn的save
###演示如何保存sklearn中的model和参数
from sklearn import svm
from sklearn import datasets
clf = svm.SVC()
iris = datasets.load_iris()
X,y = iris.data,iris.target
clf.fit(X,y)
有两种方法:
##method 1: pickle
import pickle
##save
##with open('save/clf.pickle','wb') as f:
## pickle.dump(clf,f)
##restore
with open('save/clf.pickle','rb') as f:
clf2 = pickle.load(f)
print(clf2.predict(X[0:1]))
##method 2:joblib
from sklearn.externals import joblib
##save
joblib.dump(clf,'save/clf.pkl')
##restore
clf3 = joblib.load('save/clf.pkl')
print(clf3.predict(X[0:1]))