泛型:什么是泛型?
泛型指的就是在类定义的时候并不会设置类中的属性或方法中的参数和返回值的具体类型,而是在类使用的时候在进行定义。
那么,问题又来了,上篇文章已经说了,Object类可以接受任何数据类型。
那加入泛型的意义是什么呢?
看看下面的例子:
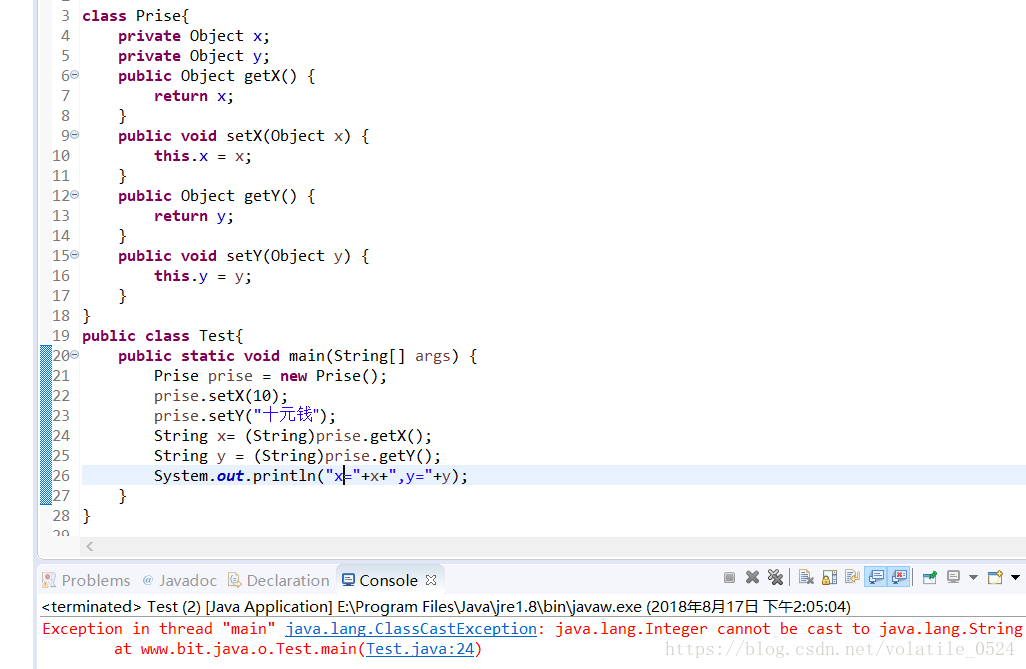
可以看到在24行出现了一个运行时错误,是因为在24行将一个Object类型的数据向下转型为String类型,而这个Object最 开始的时候接受的是一个Integer类型的数据。因此出现了报错,可是在编译时并没有报出任何错误,因此在开发中往往会 因为向下转型而出现错误,因此就引入了泛型的使用。
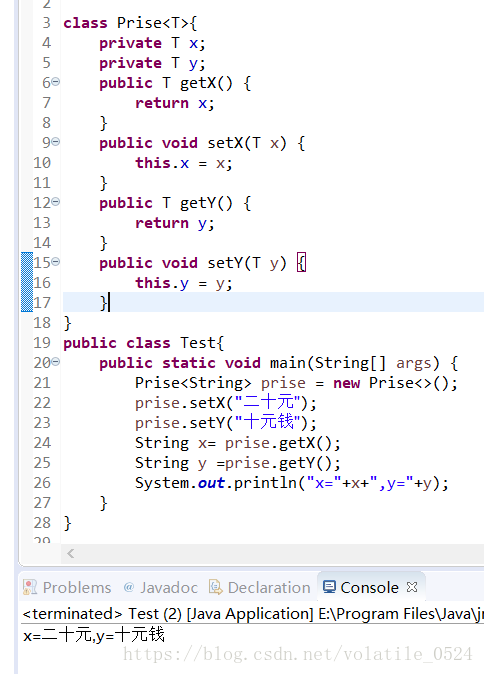
相比上面的例子,这份代码中避免了向下转型,那也就避免了向下转型带来的不安全性。
泛型类: 泛型类相对来说比较简单,例如上面的例子就是一个简单的泛型类。
泛型类:
class 类名<泛型标识符>
{
private 泛型标识符 变量名称;
public 泛型标识符 方法名1(){
return 返回值 /*返回值类型为泛型标识符标识的类型*/
}
public void 方法名2(泛型标识符 参数){
}
......
}其中<>内的泛型标识可以任意写,但通常将其规定为大写字母。上面的例子中只列举了一种类型,也可以设置多种类型,
<泛型标识符1,泛型标识符2>只需在中括号内继续追加,然后用逗号隔开就可追加。
而且泛型很好理解,只是将属性类型或方法的返回值或方法的参数类型替换成泛型标识符。
然而在使用的时候,要表明其具体的类型;
类名<具体的数据类型> 变量 = new 类名<具体数据类型>();
当然,泛型只能接收类,这里的“具体的数据类型”,必须是包装类;
上面的一套为泛型类的基本语法规则,以及基本的使用规则,结合上面的例子会更加透彻。
泛型接口:
泛型除了可以定义在类中,依然可以定义在接口中,这样的接口称为泛型接口;
interface 接口名<泛型标识符>{
public abstract 泛型标识符 方法名();
public abstract void 方法名1(泛型标识符 参数名);
}定义时的语法几乎同泛型类一样,只是不可以定义属性,因为接口中的属性都是全局常量,不允许其类型未知。
接口必须要实现,所以就有了两种实现方式:
1.在实现类实现接口时依旧是使用泛型标识符:
interface IMassage<T>{
public abstract void print(T t);
}
class MessageImpl<T>implements IMassage<T>{
public void print(T t) {
System.out.println(t);
}
}
public class Test{
public static void main(String[] args) {
IMassage<String> str = new MessageImpl<>();
str.print("Hello");
}
}
2.在实现类实现接口时给出了具体的数据类型:
interface IMassage<T>{
public abstract void print(T t);
}
class MessageImpl implements IMassage<String>{
public void print(String t) {
System.out.println(t);
}
}
public class Test{
public static void main(String[] args) {
IMassage<String> str = new MessageImpl();
str.print("Hello");
}
}
3.泛型方法:
泛型方法相比泛型类,泛型接口要更为复杂一些;
根据上面的经验,现在我们现在大可以推测,所谓泛型方法就是在方法上使用泛型,但并不是说带有泛型标识符的就是泛 型;
泛型方法是在进行方法调用时才确定类型的方法;
例如:
public <T> void 方法名(T t);
public <T> T 方法名1();
上面两个为泛型方法,在调用时才确定返回值类型或参数类型。
public T 方法名(){};
public void 方法名1(T t){};
这上面两种只是泛型类中的普通方法。
要使用泛型方法要将泛型参数列表置于返回值前。
当泛型方法在泛型类中时,泛型方法始终以自己定义的类型参数为准。
例如:
class Massage<T>{
public<T> void print(T t) //泛型方法,带有<>,以自己的类型为准
{
System.out.println(t+t.getClass().getName());
}
public void print(T t1,T t2) //泛型类中的普通方法,以泛型类中传入的参数为准
{
System.out.println(t1+".t1使用泛型类的类型:"+t1.getClass().getName());
System.out.println(t2+".t2使用泛型类的类型:"+t2.getClass().getName());
}
}
public class Test{
public static void main(String[] args) {
Massage<Integer> massage = new Massage<Integer>();
massage.print(1, 2);
massage.print("我是使用自己的类型");
}
}
然后运行起来我们就可以看到下面的结果:
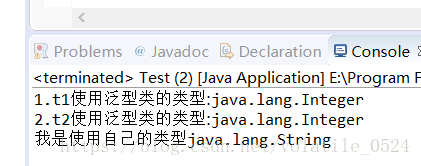
由此可以得知,就算泛型方法中的泛型标识符与泛型类中的一样,泛型方法始终以自己的类型为准。
4.通配符
当我们在使用泛型的时候,可能会遇到下面的状况:
class Massage<T>{
private T str;
public T getStr() {
return str;
}
public void setStr(T str) {
this.str = str;
}
}
public class Test{
public static void main(String[] args) {
Massage<String> massage = new Massage<String>();
massage.setStr("hello");
fun(massage);
}
public static void fun(Massage<String> temp) {
System.out.println(temp.getStr());
}
}此时,我们就可以看到一个弊端,下面的 fun(),把上面的Message<T>的类型规定死了,也就是说,如果 <T>中的T代表的不再是String类型,那么如果再使用fun()的话,就会出现错误。因此,泛型在上述的fun()就失去了它原本的意义了。
因此,引入了通配符的概念 “?”,通配符“?”描述的是它可以接受任何类型,而又不会被用户修改。

所谓的不可以被用户修改呢,就像是上面的例子,当fun()中的参数未知的时候,不可给其具体类型加以修改,这时候编译都会有问题。
然而在通配符的“?”概念上又引出了泛型下限和泛型上限的概念:
?super 类型
? extends 类型;
什么意思呢,在我的理解里,? super 类型,此时,这个代表的就是“类型”的父类或“类型”自身的类型;
?extends 类型,此时,这就代表的是“类型”的子类或“类型”本身的类型;
举个例子:
?super String:这就代表的是,String及其父类;
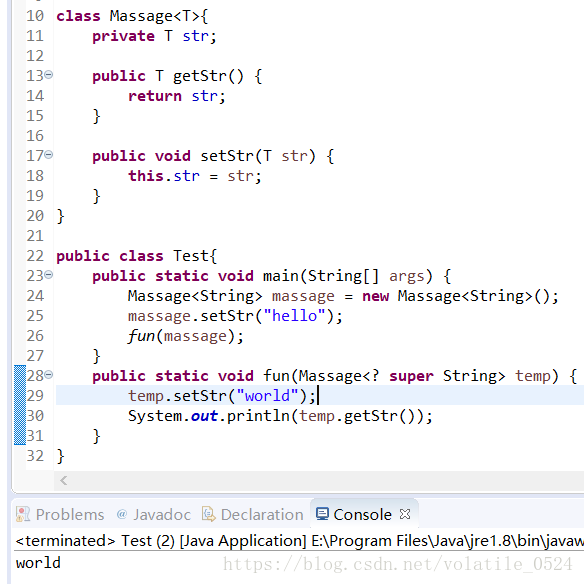
此时fun()接受的就为String类型及String类型的父类Object类的数据,因此,fun()接收的参数类型就比较清楚了,因此就可以修改数据了。
?extends Number:代表的是 Number下的子类,以及Number类型;

此时,fun()接收的参数类型就为Number以及Number的子类(Integer、Short、Long、Double、Float、Byte),此时,fun()接收的参数就不清楚了。因为,不可能在main方法中 的setStr()传入了一个Double类型的参数,而后,在fun()中又在setStr()中传入了一个Integer类型的参数。所以此时在想修改数据就会出现编译问题。
因此,总结 通配符、泛型上限不可以修改数据;而泛型下限可以修改数据。
5.泛型擦除
泛型信息只存在于代码编译阶段,在进入JVM之前,与泛型相关的信息会被擦除掉,这就叫做泛型擦除。
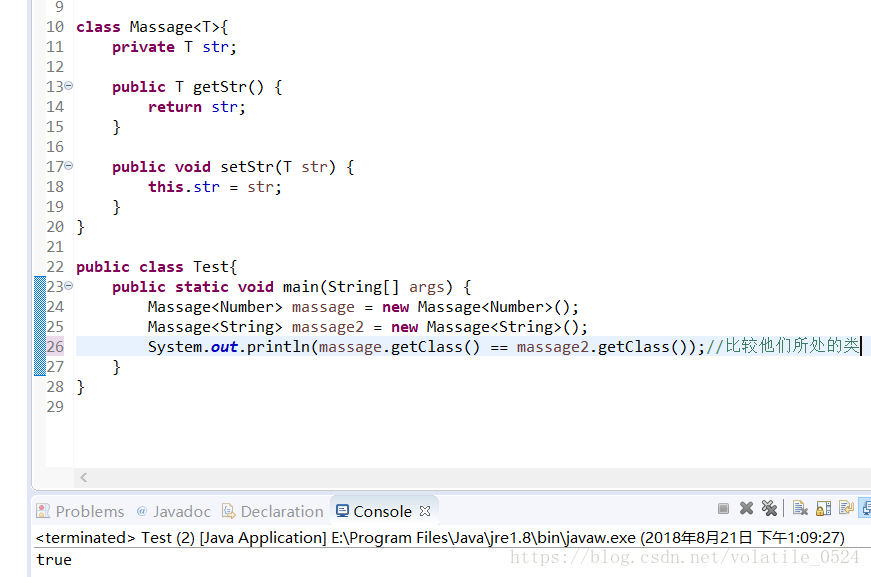
由上面的比较结果可以看出来,根本没有在意泛型的类型,因为这两个实例化对象都是Massage的实例化对象,也是因为将其泛型类型擦出了的原因。
当然在泛型擦出的时候,如果指定类型指定了上限,<T extends String>,则类型就会被替换成类型上限(String),如果没有指定,就会被替换成Object类型。
这就是我对泛型的一点看法,如果文章有不足的地方,欢迎留言指出!
好了,不说了,抓紧时间敲代码咯!!!