定义 : 线性回归属于监督学习,目的是在包含正确答案的数据集通过预测找到某种映射关系 x→y。
线性回归的一般形式
对于一般形式解释一下:
1.假设函数可以简单理解为拟合曲线的大致形状,如一次函数y = θx+b 二次y=θ1x^2+θ2x+θ3,然后我们通过minJ(θ)去找最合适θ值(比如梯度下降,正规方程)
2.损失函数顾名思义,就是将每个特征的预测值-实际值的和全部加起来,1/2m
的意义是尽量的减少平均误差。
3.我们的目的是尽可能的使J(θ)变小,所以我们最合适θ值
个人认为,求解最小J(θ)的方法中,重点关注梯度下降,正规方程简单了解即可。
理论知识储备:吴恩达教授的视频给出了非常容易理解且详细的理论知识(推导+详细讲解),受益匪浅。下面的代码是将视频中的知识代码化。
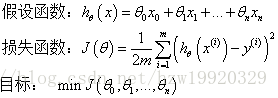
手撕代码系列:
最小二乘法
# -*-coding:utf-8-*-
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
# 采样
x = np.array([1, 2, 3,4, 5, 6])
y = np.array([15, 19, 22, 27, 30, 31])
# 画出散点图
plt.scatter(x,y)
# 假设函数
def func_least(p,x):
k,b =p
y = k*x+b
return y
# 代价函数
def cost_func(p,x,y):
return func_least(p,x)-y
# 假设参数值
p = [100,50]
# 最小二乘法
pa = leastsq(cost_func,p,args=(x,y))
k,b =pa[0]
x= np.linspace(1,6,100)
y = k*x+b
plt.scatter(x,y,color ="red")
print k,b
# 3.3714285712178196 12.199999999917608
plt.show()
然后梯度下降
#-*-coding:utf-8-*-
# x[i]特征
import numpy as np
x = np.array([1, 2, 3,4, 5, 6])
y = np.array([15, 19, 22, 27, 30, 31])
print len(x), len(y)
epsilon = 0.0001
alpha = 0.001
max_itor = 100000
diff = [0, 0]
error_one = 0
error_two = 0
m = len(x)
# 记录迭代次数
cont = 0
# 初始化参数
theta0 = 0
theta1 = 0
def model_fun(theta0, theta1, x0):
h = theta0 + theta1*x0
return h
while cont < max_itor:
cont += 1
for i in range(m):
diff[0] = model_fun(theta0, theta1, x[i]) - y[i]
theta0 -= alpha * diff[0]
theta1 -= alpha * diff[0] * x[i]
error_one = 0
for i in range(m):
error_one += (model_fun(theta0, theta1, x[i]) - y[i]) ** 2 / 2 * m
if abs(error_one - error_two) < epsilon:
break
error_two = error_one
print theta0, theta1
print theta0, theta1
# 12.0961685897 3.39114086225
print("迭代次数为%s"%cont)
两种算法的θ几乎一样,说明梯度下降算法正确。 正规方程代码实现比较简单,就不做演示了。
从梯度下降的代码中可知,alpha 的取值是非常关键的,alpha 取小了迭代次数非常多,alpha 或许就收敛不了,这就应该考虑特征值缩放的问题。θ的更新一定要保证同时更新(关键中的关键)
本文中没有做太多的理论分析,最后再强烈推荐一下吴恩达教授的视频,怎一个棒字了得!
附一张梯度下降笔记
