概述
传统机器学习方法
分类问题一般的步骤可以分为特征提取、模型构建、算法寻优、交叉验证等。对于文本而言,如何进行特征提取是一个很重要也很有挑战性的问题。文本的特征是什么,如何量化为数学表达呢。
但是TF-IDF的文档表达只是考虑了词语频率信息,并未考虑词语的上下文结构信息以及词语隐含的主题信息。于是又发展了几种现阶段比较常用的分类特征:n-gram模型考虑上下文;主题模型LDA[2]通过无监督方法得到词语和文档在不同主题的分布情况;word2vec[1]用于得到词语之间的分布信息等。
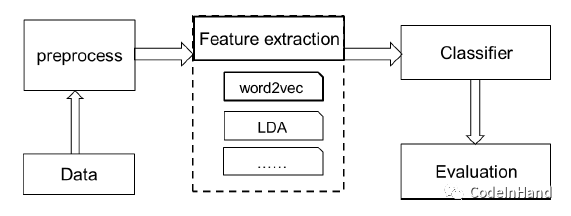
文本分类过程大概可以描述为如下图,具体包括数据预处理、特征提取、分类器构建、模型评价等。对于中文文本而言,数据预处理包括:中文分词、词性标注(如果分类需要词性特征)、去停用词(去掉一些没什么含义的词语,会对分类产生影响,例如:你、我、他、的…)等;特征提取,就是提取你想要用作分类的特征,具体包括TF-IDF计算、n-gram、word2vec、LDA等;特征提取之后还存在特征选择的过程,特征选择的过程,由于TF-IDF特征过于稀疏,需要对特征进行选择,找到对分类有效的特征,常用的方法有信息增益IG(判断增添该特征带来的信息增益)、CHI-square用于找到与类别信息强相关的特征等等;分类模型的选择,由于文本分类一般为多分类的模型,传统机器学习中一般采用Naïve-Bayes分类、KNN、SVM等分类方法,近年来使用随机森林和梯度增强算法用的比较多,Xgboost用于分类模型效率很高,有兴趣的童鞋可以进一步专研。LDA主题模型用于文本分类也越来越多,主要用于计算词语在主题的分布情况。

区别于传统机器学习方法,深度学习最大的优势就是避免了繁琐的特征提取过程,词语使用连续向量进行Embedding表示,可以使用pre-trained的word2vec进行初始化。通过Multi-Layer的DNN、CNN或RNN进行高维抽象特征提取,最后经过softmax进行多分类。
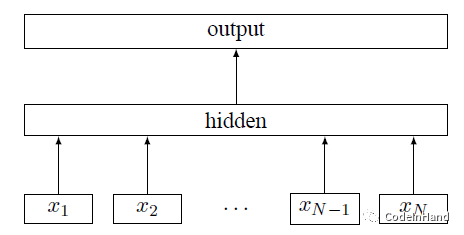
(2) DAN/ADAN文本分类
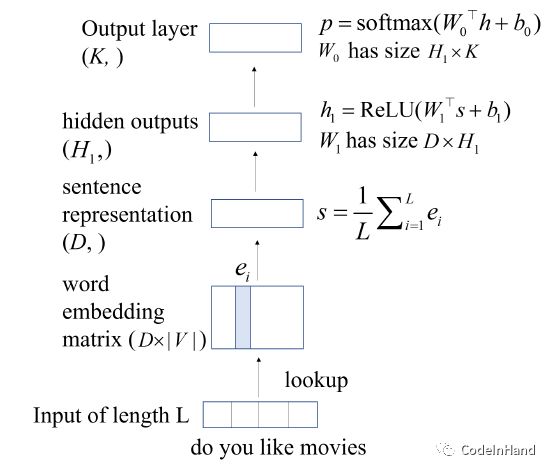
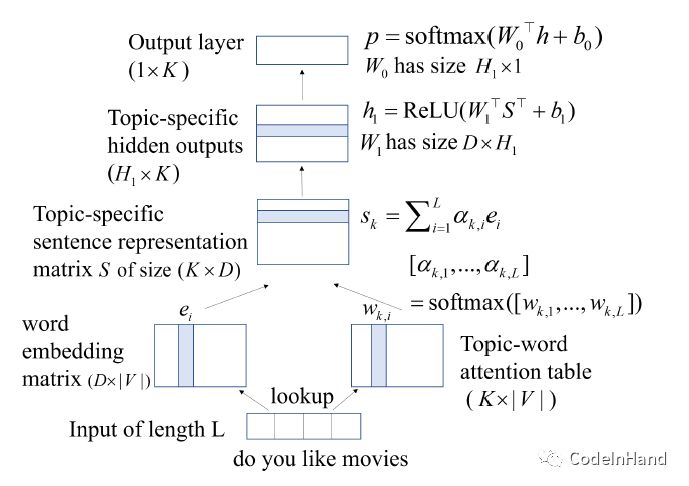
论文[4]中给出了DAN、ADAN的文本分类模型。DAN指的是Deep Average Network,主要是基于word2vec词向量特征,通过求文档中所有词语的word2vec向量的平均值来表示文本:Vector(Document) = Average(Vector(word))。
(3) CNN文本分类
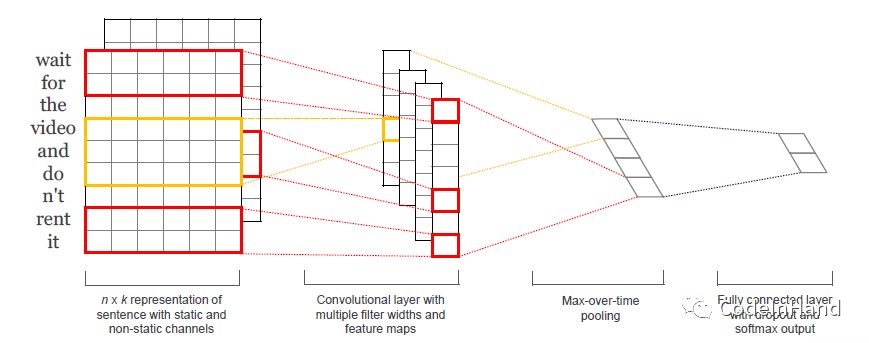
CNN文本分类模型目前在长文本分类过程中得到了广泛地使用,主要原因在于其算法的高度并行化。最早是由论文[7]给出的模型结构,具体如下图所示。模型使用多个channel(non-static, static),选择使用多个不同kernel size的卷积函数,使用Max-Pooling选择出最具影响力的高维分类特征,再使用带有Drop out的全连接层提取文本深度特征,最后接softmax进行分类。经笔者亲自验证CNN的效果要明显高于DAN的分类效果。
(4) HAN文本分类
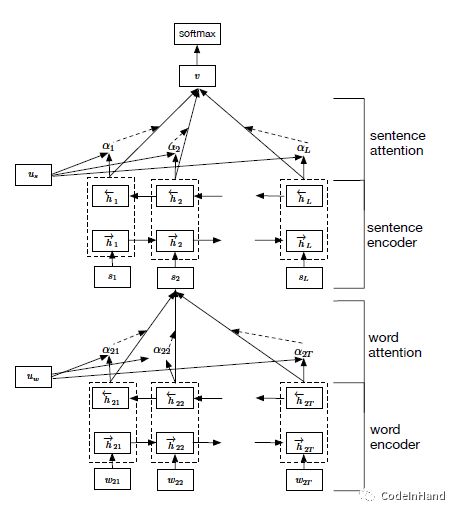
HAN的分类模型[3]是一个非常有意思的长文本分类模型,通过对文本结构进行分层:词语、句子、文档三个层面。先将文档进行分句,得到多个句子,每个句子又由多个词语进行构成。然后分层引入Attention机制,实质是关注特定的句子、关注句子中特定的词语。模型结构如下图所示,虽然HAN运行时间会明显长于CNN,但模型的分类效率确实比CNN效果好。模型结构如下图所示,简单描述为词语层面Embedding输入加上Bi-LSTM得到句子表达,再加入Attention关注特定的词,再接Bi-LSTM得到文本表达,进一步使用Attention关注特定的句子。
参考文献
[1] Tomas Mikolov, IlyaSutskever, Kai Chen, Greg Corrado, and Jeffrey Dean.Distributed Representations of Words and Phrases andtheirCompositionality. In Proceedings of NIPS, 2013.
[2] D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichletallocation,”theJournal of machine Learning research, vol. 3, pp. 993–1022, 2003.
[3] Yang Z, Yang D, Dyer C, et al. Hierarchical attention networks for document classification[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016: 1480-1489.
[4] Guo F, Metallinou A, Khatri C, et al. Topic-based Evaluation for Conversational Bots[J]. arXiv preprint arXiv:1801.03622, 2018.
[5] Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[J]. arXiv preprint arXiv:1607.01759, 2016.
[6] Ren F, Li C. Hybrid Chinese text classification approach using general knowledge from Baidu Baike[J]. IEEJ Transactions on Electrical and Electronic Engineering, 2016, 11(4): 488-498.
