一 数据集的制作
我们经常用到的原始数据是图片文件,如jpg,jpeg,png,tif等格式的,而且有可能图片的大小还不一致,而在caffe中经常使用的数据类型是lmdb或leveldb。
1. 数据集的准备。手中有4万多张人脸照片,将人脸照片按照年龄分成6组:10~20岁,20~30岁,30~40岁,40~50岁,50~60岁和大于60岁的。其中选取4万张作为训练集,剩余的作为测试集。为了保证测试的精度,在训练集中选取少量的图像添加到测试集中。
2. 灰度图和图像尺寸统一。因为采集的数据集是彩色的,图像尺寸不统一,为了让图像符合训练网络的要求。需对图像进行尺寸变换。
# -*- coding:utf-8 -*-
import cv2
import os
import numpy
def Resize(pathFile,reSizeFile):
for files in os.listdir(pathFile):
imagePathFile=os.path.join(pathFile,files)
img=cv2.imread(imagePathFile,0)
imgResize=cv2.resize(img,(120,120),interpolation=cv2.INTER_CUBIC)
reSizeDir=os.path.join(reSizeFile,files)
cv2.imwrite(reSizeDir,imgResize)
print(imagePathFile+' 调整大小成功,存放路径在: '+reSizeFile)
Resize('E:/train/A1/r/ageFaceNormlization1/test/',
'E:/train/A1/r/ageFaceNormlization1/2/')3. 生成label文件。根据图像所属类别制作数据集的标签,格式为xxx.jpg label。
import os
def maketxtList(imageFile, pathFile):
fobj = open(pathFile, 'w')
lab=0
for files in os.listdir(imageFile):
label_str = os.path.splitext(files)[0]
label = label_str[-2:]
if(int(label)<0 and int(label)>100):
print ('error')
return
if(int(label)>10 and int(label)<20):
lab=0
if(int(label)>=20 and int(label)<30):
lab=1
if(int(label)>=30 and int(label)<40):
lab=2
if(int(label)>=40 and int(label)<50):
lab=3
if(int(label)>=50 and int(label)<60):
lab=4
if(int(label)>=60):
lab=5
fobj.write('\n' + files + ' ' + str(lab))
fobj.close()
maketxtList('E:/train/A1/r/ageFaceNormlization1/1/',
'E:\\untitled\\venv\\trainS.txt')
#maketxtList('E:\\train\\m22', 'E:\\untitled\\venv\\testLabel.txt')
print('OK!')
生成label文件如下:
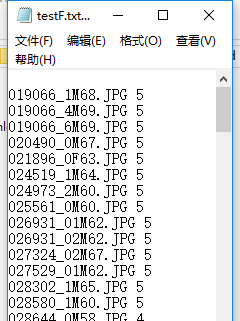
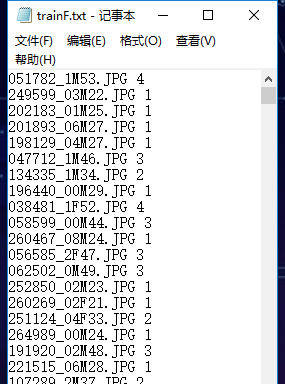
注意:label要从0开始?
在使用SoftmaxLoss层作为损失函数层的单标签分类问题中,label要求从0开始,例如1000类的ImageNet分类任务,label的范围是0~999。这个限制来自于Caffe的一个实现机制,label会直接作为数组的下标使用,具体代码S
oftmaxLoss.cpp中133行和139行的实现代码。
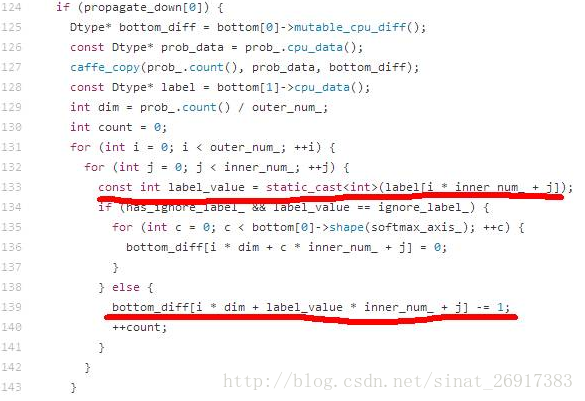
132行第一层for循环中的outer_num等于batch size,对于人脸识别和图像分类等单标签分类任务而言,inner_num等于1。如果label从1开始,会导致bottom_diff数组访问越界。
在标签正确的前提下,如果倒数第一个全连接层num_output > 实际的类别数,Caffe的训练是否会报错?答案:不会报错且无影响。
4. 转化为lmdb。新建一个creatlmdb.bat的脚本文件,使用caffe中的convert_imageset.exe工具转化图片数据为lmdb数据文件:
E:\caffe\caffe-master\Build\x64\Release\convert_imageset.exe E:/train/A1/r/ageFaceNormlization1/2/ E:/untitled/venv/testS.txt E:/testS_lmdb backend lmdb -shuffle -gray=true
pause
其中shuffle是在生成lmdb将数据打乱,shuffle是为了防止训练时训练批次内数据属于同类而出现过拟合现象;gray是将图像变为灰度图
分别生成train_lmdb和test_lmdb
5. 计算均值文件。图片减去均值后,再进行训练和测试,会提高速度和精度。Caffe提供了compute_image_mean.exe文件用于生成均值,compute_image_mean.exe带两个参数,第一个参数时lmdb训练数据位置,第二个参数设定均值文件的名字及保存路径。
E:\caffe\caffe-master\Build\x64\Release\compute_image_mean.exe E:/trainS_lmdb E:/mean.binaryproto
pause二 生成caffe网络
编写自己的caffe网络,例子如下:
首先搭建训练和测试网络:
def create_net(lmdb, batch_size, include_acc=False):
data, label = L.Data(source=lmdb, backend=P.Data.LMDB, batch_size=batch_size, ntop=2,
transform_param=dict(scale=0.00390625))
conv1 = L.Convolution(data, kernel_size=11, stride=1, num_output=64, weight_filler=dict(type='xavier'),
bias_filler=dict(type='constant'))
relu1 = L.ReLU(conv1, in_place=True)
norm1 = L.LRN(relu1, local_size=5, alpha=0.0001, beta=0.75)
pool1 = L.Pooling(norm1, pool=P.Pooling.MAX, kernel_size=2, stride=2)
conv2 = L.Convolution(pool1, kernel_size=6, stride=1, num_output=128, weight_filler=dict(type='xavier'),
bias_filler=dict(type='constant'))
relu2 = L.ReLU(conv2, in_place=True)
norm2 = L.LRN(relu2, local_size=5, alpha=0.0001, beta=0.75)
pool2 = L.Pooling(norm2, pool=P.Pooling.MAX, kernel_size=2, stride=2)
conv3 = L.Convolution(pool2, kernel_size=4, stride=1, num_output=128, weight_filler=dict(type='xavier'),
bias_filler=dict(type='constant'))
relu3 = L.ReLU(conv3, in_place=True)
norm3 = L.LRN(relu3, local_size=5, alpha=0.0001, beta=0.75)
pool3 = L.Pooling(norm3, pool=P.Pooling.MAX, kernel_size=2, stride=2)
fc4 = L.InnerProduct(pool3, num_output=500, weight_filler=dict(type='xavier'), bias_filler=dict(type='constant'))
relu4 = L.ReLU(fc4, in_place=True)
drop4 = L.Dropout(relu4, in_place=True)
fc5 = L.InnerProduct(drop4, num_output=700, weight_filler=dict(type='xavier'), bias_filler=dict(type='constant'))
relu5 = L.ReLU(fc5, in_place=True)
drop5 = L.Dropout(relu5, in_place=True)
fc6 = L.InnerProduct(drop5, num_output=6, weight_filler=dict(type='xavier'), bias_filler=dict(type='constant'))
loss = L.SoftmaxWithLoss(fc6, label)
if include_acc:
acc = L.Accuracy(fc6, label)
return to_proto(loss, acc)
else:
return to_proto(loss)Solver.prototxt文件配置:
sp = {}
sp['train_net'] = '"AS/trainS_python.prototxt"' # 训练配置文件
sp['test_net'] = '"AS/testS_python.prototxt"' # 测试配置文件
sp['test_iter'] = '100' # 测试迭代次数
sp['test_interval'] = '500' # 测试间隔
sp['base_lr'] = '0.01' # 基础学习率
sp['display'] = '100' # 屏幕日志显示间隔
sp['max_iter'] = '40000' # 最大迭代次数
sp['lr_policy'] = '"inv"' # 学习率变化规律
sp['gamma'] = '0.0001' # 学习率变化指数
sp['momentum'] = '0.9' # 动量
sp['weight_decay'] = '0.0005' # 权值衰减
sp['power'] = '0.75'
sp['snapshot'] = '500' # 保存model间隔
sp['snapshot_prefix'] = '"AS/ACCNsS"' # 保存的model前缀
sp['solver_mode'] = 'CPU'Solver.prototxt文件超参数设置规则:
1) batchsize:每迭代一次,网络训练图片的数量,例如:如果你的batchsize=256,则你的网络每迭代一次,训练256张图片;则,如果你的总图片张数为1280000张,则要想将你所有的图片通过网络训练一次,则需要1280000/256=5000次迭代。
2) epoch:表示将所有图片在你的网络中训练一次所需要的迭代次数,假定训练集总量为N,训练批次为M,那么。如上面的例子:95次,我们称之为 一代。所以如果你想要你的网络训练100代时,则你的总的迭代次数为max_iteration=95*100=9500次。
3) max_iteration:网络的最大迭代次数如上面的30000次;同理,如果max_iteration=3000,则该网络被训练30000/95=316代。
4) test_iter:表示测试的次数;比如,你的test阶段的batchsize=100,而你的测试数据为10000张图片,则你的测试次数为10000/100=100次;即,你的test_iter=100。要求你的test_iter*batchsize大于等于你的测试集
5) test_interval:表示你的网络迭代多少次才进行一次测试,你可以设置为网络训练完一代,就进行一次测试,比如前面的一代为5000次迭代时,你就可以设置test_interval=5000。要求test_interval*训练批次大于等于你的训练集。
6) base_lr:表示基础学习率,在参数梯度下降优化的过程中,学习率会有所调整,而调整的策略就可通过lr_policy这个参数进行设置。
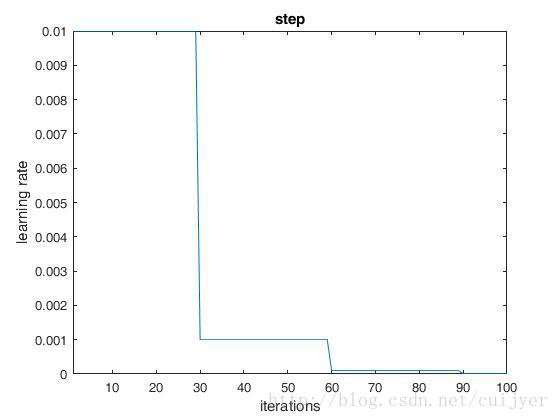
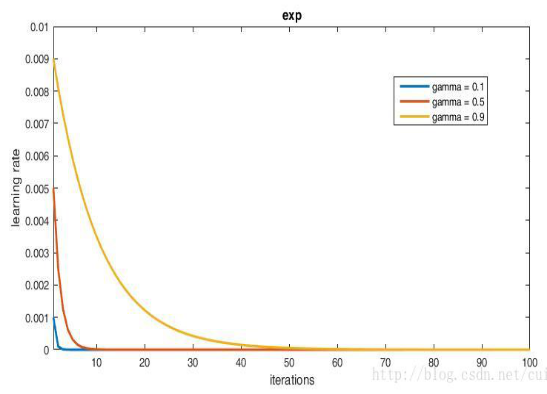
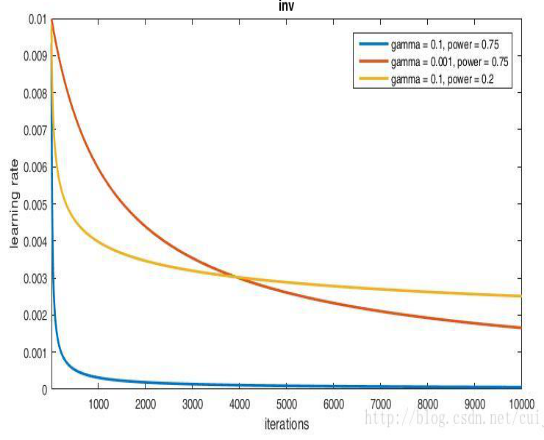
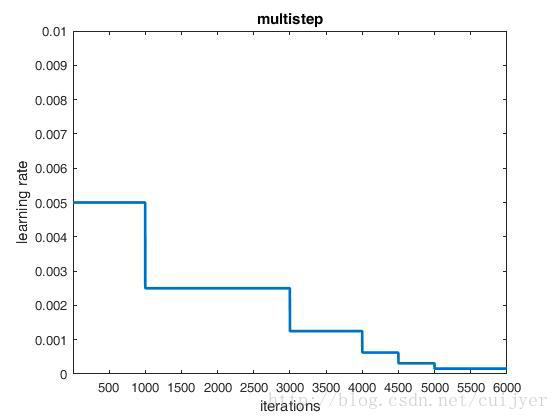
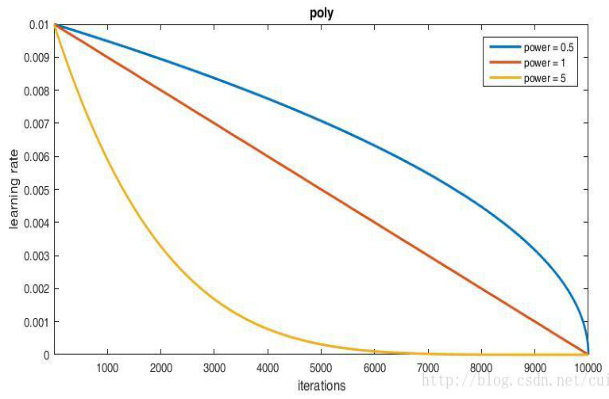
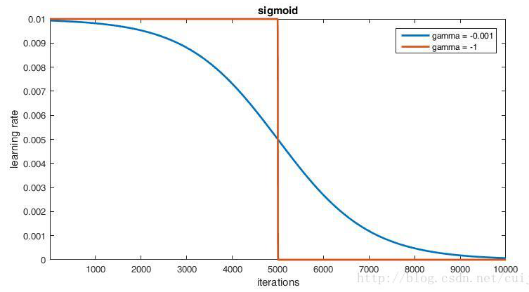
7) lr_policy:学习率的调整策略:
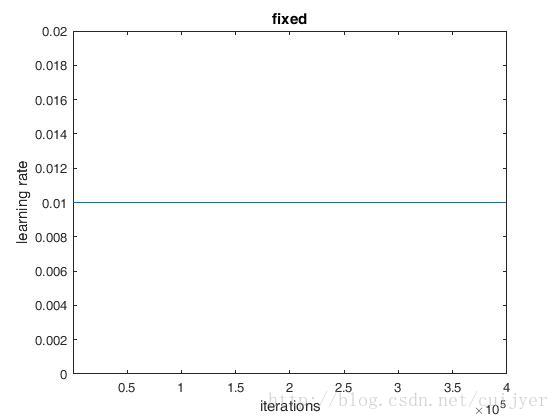
1. fixed:保持base_lr不变;
2. step:如果lr_police设置为step,还需要设置一个参数stepsize,那么实际的学习率为
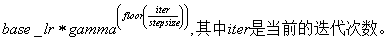
3. exp:返回
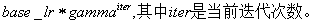
4. inv:如果lr_policy设置为inv,还需要设置一个参数power,返回
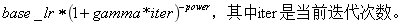
5. multistep:如果lr_policy设置为multistep,还需要设置一个参数stepvalue。这个参数和stepsize相似,step是均匀等间隔变化,而multistep由参数 stepsize 与 stepvalue 决定; 它不是每时第刻都去计算 学习率,而是达到我们设定的stepvalue的时候,才去计算然后更新学习率; stepvalue 可以设置多个。
6. poly:多项式衰减,返回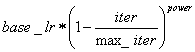
7. sigmoid:学习率进行sigmoid衰减,返回
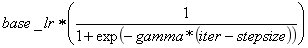
8)momentum :上一次梯度更新的权重
9)weight_decay:权重衰减项,防止过拟合的参数
10)Snapshot:快照。将训练出来的model和solver状态进行保存,snapshot用于设置训练多少次后进行保存,默认为0,不保存。
11)snapshot_prefix:设置快照保存路径。
12)solver_mode:设置运行模式。默认为GPU,如果你没有GPU,则需要改成CPU,否则会出错。
三 训练网络
def training(solver_protro):
caffe.set_mode_cpu()
solver = caffe.SGDSolver(solver_proto)
solver.solve()其中caffe.set_device()是设置使用第几块GPU,默认是0;caffe.set_model_gpu()是设置使用GPU训练,如果没有GPU则改为caffe.set_model_cpu()。Caffe.SGDSolver()是使用随机梯度下降发法训练网络,训练神经网络采用的反向传播方法还有 “AdaDelta”——一种”鲁棒的学习率方法“,是基于梯度的优化方法。“AdaGrad”——自适应梯度方法。“Adam”——一种基于梯度的优化方法。“Nesterov”——Nesterov的加速梯度法,作为凸优化中最理想的方法,其收敛速度非常快。 “RMSProp”——一种基于梯度的优化方法。
其中SGD方法是目前caffe网络训练是效果最理想的方法,softmax计算公式,其中k对应的是label。它的损失计算公式为,其中log是以e为底,y是label,若类别数为N,则y为N维。对于单label情况,N维中只有一维为1,其他为零,计算loss时仅需考虑label中非零那一维即可,此时(PS小技巧:假定网络分类为6类,那么开始训练是的损失在左右时代表网络结构和超参数设置合理)。
训练中出现了loss=87.33原因以及解决方案如下:loss的最大值由FLT_MIN(最小的正浮点数)得到,FLT_MIN定义为1.17549435E-38F,这个数字的自然对数正好就是 -87.3356,算loss时需要取负值,结果就成了87.3356。这说明softmax计算得到概率值出现了零(由于float类型所能表示的最小数值是,比这个值还小的无法表示,只能是零) 。而softmax是用指数函数计算的,指数函数的值都是大于零的。因此,我们有理由相信,计算过程中出现了float溢出等异常,出现了inf,nan等异常数值导致softmax输出为零 。最后我们发现,当softmax之前的feature值过大时,由于softmax先求指数,会超出float数据范围,成为inf。inf与其他任何数值的和都是inf,softmax在做除法时任何正常范围的数值除以inf都会变为0。然后求loss时log一下就出现了87.3356这样的值。解决方案:①观察数据中是否有异常样本或异常label导致数据读取异常 (label要从0开始);②调小初始化权重,以便使softmax输入的feature尽可能变小;③降低学习率,这样就能减小权重参数的波动范围,从而减小权重变大的可能性;④如果有BN(batch normalization)层,finetune时最好不要冻结BN的参数,否则数据分布不一致时很容易使输出值变得很大。
在训练网络过程中往往是需要经过大量的训练,通过不断对超参数调整来达到最理想的训练效果,那么调整超参数往往是根据训练日志中的train loss、test loss、accuracy以及学习率的变化规律来进行的,其中最主要的是train loss、test loss、accuracy的变化规律。下面是train loss、test loss、accuracy随这迭代次数的变化规律曲线绘制方法:
niter = 46400
display_iter = 20
test_iter = 120
test_interval = 464
# train loss
train_loss = zeros(ceil(niter * 1.0 / display_iter))
# test loss
test_loss = zeros(ceil(niter * 1.0 / test_interval))
# test accuracy
test_acc = zeros(ceil(niter * 1.0 / test_interval))
# iteration 0,不计入
solver.step(1)
# 辅助变量
_train_loss = 0
_test_loss = 0
_accuracy = 0
# 进行解算
for it in range(niter):
# 进行一次解算
solver.step(1)
# 计算train loss
_train_loss += solver.net.blobs['loss'].data
if it % display_iter == 0:
# 计算平均train loss
train_loss[it // display_iter] = _train_loss / display_iter
_train_loss = 0
if it % test_interval == 0:
for test_it in range(test_iter):
# 进行一次测试
solver.test_nets[0].forward()
# 计算test loss
_test_loss += solver.test_nets[0].blobs['loss'].data
# 计算test accuracy
_accuracy += solver.test_nets[0].blobs['accuracy'].data
# 计算平均test loss
test_loss[it / test_interval] = _test_loss / test_iter
# 计算平均test accuracy
test_acc[it / test_interval] = _accuracy / test_iter
_test_loss = 0
_accuracy = 0
# 绘制train loss、test loss和accuracy曲线
print '\nplot the train loss and test accuracy\n'
ax1 = plt.subplots()
ax2 = ax1.twinx()
# train loss -> 绿色
ax1.plot(display_iter * arange(len(train_loss)), train_loss, 'g')
# test loss -> 黄色
ax1.plot(test_interval * arange(len(test_loss)), test_loss, 'y')
# test accuracy -> 红色
ax2.plot(test_interval * arange(len(test_acc)), test_acc, 'r')
ax1.set_xlabel('iteration')
ax1.set_ylabel('loss')
ax2.set_ylabel('accuracy')
plt.show()分析绘制出的曲线图适当调整参数,对train loss 和 test loss分析奉行一下规则:
Train和Test损失曲线
(1)train loss不断下降,test loss不断下降,说明网络仍然在学习。
(2)train loss不断下降,test loss趋于不变,说明网络过拟合。
(3)train loss趋于不变,test loss趋于不变,说明学习遇到瓶颈,需减小学习速率或批量数据尺寸。
(4)train loss趋于不变,test loss不断下降,说明数据集100%有问题。
(5)train loss不断上升,test loss不断上升(最终变为NaN),可能是网络结构设计不当、训练超参数设置不当、程序bug等某个问题引起的,需要进一步定位。testloss 上升可能是过拟合引起的.
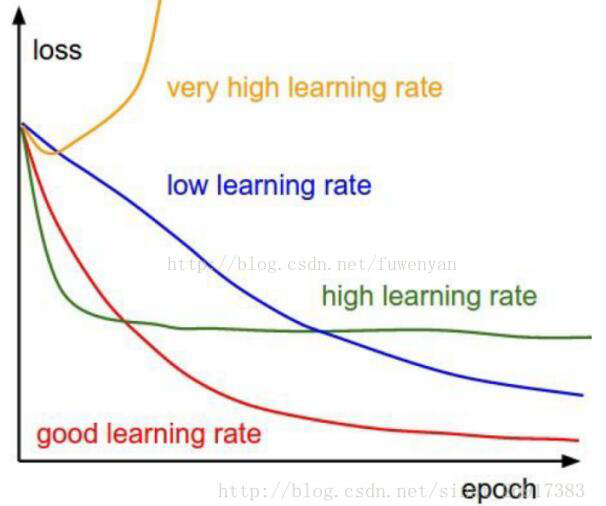
1. 当使用caffe训练网络,loss不收敛,解决方法:1》检查label是否从0开始;2》降低学习率,base_lr这个参数在自己训练新网络时,可以从0.1开始尝试,如果loss不下降的意思,那就降低,除以10,用0.01尝试,一般来说0.01会收敛,不行的话就用0.001.
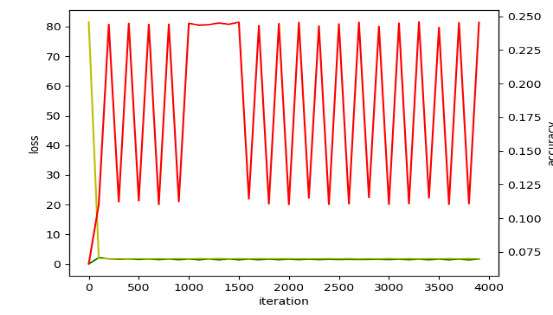
如图1是学习率对loss曲线的影响。3》网络设计不合理。如果做很复杂的分类任务,却只用了很浅的网络,可能会导致训练难以收敛。
2. 当使用caffe训练网络,loss震荡,如图2。原因:训练的batch_size太小;:数据输入不对。解决方法:1》训练batch_size的调整策略:1)当数据量足够大的时候由于数据量太大,内存不够可以适当的减小batch_size。但盲目减少会导致无法收敛,batch_size=1时为在线学习。2)batch的选择,首先决定的是下降方向,如果数据集比较小,则完全可以采用全数据集的形式。这样做的好处有两点:全数据集的方向能够更好的代表样本总体,确定其极值所在;由于不同训练数据的梯度值差别巨大,因此选取一个全局的学习率很困难。3)增大batchsize的好处有三点:①内存的利用率提高了,大矩阵乘法的并行化效率提高。②跑完一次epoch(全数据集)所需迭代次数减少,对于相同的数据量的处理速度进一步加快。
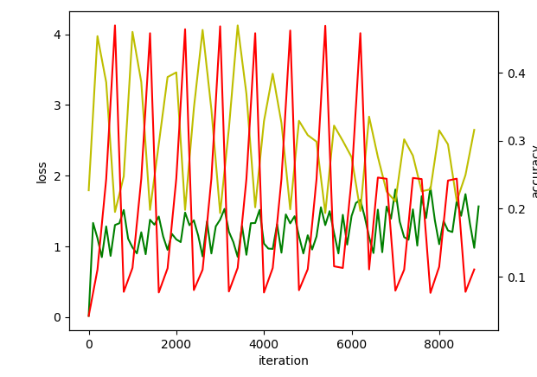
③一定范围内,batchsize越大,其确定的下降方向就越准,引起训练震荡越小。4) 盲目增大的坏处:①当数据集太大时,内存撑不住。②batchsize增大到一定的程度,其确定的下降方向已经基本不再变化。综上所述:1)batch数太小,而类别又比较多的时候,可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。2)随着batchsize增大,处理相同的数据量的速度越快。3)随着batchsize增大,达到相同精度所需要的epoch数量越来越多。4)由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。5)过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。 6)具体的batch size的选取和训练集的样本数目相关。2》数据输入不对包括数据的格式不是网络模型指定的格式,导致训练的时候网络学习的数据不是想要的; 此时会出现loss曲线震荡;需要检查数据输入格式,数据输入的路径。
3. 当使用caffe训练网络时,accuracy曲线震荡,如图3。解决方案:1)一般说法是学习率太大,可以结合lr_policy降低base_lr或更改lr_policy;2)solver里的test interval* train batch size 应该>=train image 总数,保证全部图片循环一轮之后再测试,est iter * test batch size应该>=test image 总数;3)检查label标签是否从0开始;4)使用小的数值初始化网络。
★权重初始化方法:文件 filler.hpp提供了7种权值初始化的方法,分别为:常量初始化(constant)、高斯分布初始化(gaussian)、positive_unitball初始化、均匀分布初始化(uniform)、xavier初始化、msra初始化、双线性初始化(bilinear)。
1)constant初始化方法:它就是把权值或着偏置初始化为一个常数,具体是什么常数,自己可以定义,默认为0。
2)Gaussian 初始化方法:给定高斯函数的均值与标准差生成高斯分布。
3)XavierFiller初始化方法:对于这个初始化的方法,是有理论的。它来自这篇论文《Understanding the difficulty of training deep feedforward neural networks》。在推导过程中,我们认为处于 tanh激活函数的线性区,所以呢,对于ReLU激活函数来说,XavierFiller初始化也是很适合。对于权值的分布:是一个让均值为0,方差为1 / 输入的个数 的 均匀分布
4)uniform初始化方法:它的作用就是把权值与偏置进行 均匀分布的初始化。用min 与 max 来控制它们的的上下限,默认为(0,1)。
5)Bilinear:它是基于《Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification》来推导的,并且呢,它是基于激活函数为 ReLU函数。对于权值的分布,是基于均值为0,方差为 2 /输入的个数 的高斯分布,这也是和上面的Xavier Filler不同的地方;它特别适合激活函数为 ReLU函数。
权重的初始化在深度神经网络中起着比较大的重要,算是一个技巧,但在实际应用上确是个大杀器。
如果一开始把网络中的权重初始化为0,会发生什么?因为权重初始为0, 由于网络中的神经元的更新机制完全相同,由于网络的对称性,会产生各个layer中产生相同的梯度更新,导致所有的权重最后值相同,收敛会出现问题。 (首先介绍一下我们不应该做的事情(即初始化为0)。需要注意的是我们并不知道在训练神经网络中每一个权重最后的值,但是如果进行了恰当的数据归一化后,我们可以有理由认为有一半的权重是正的,另一半是负的。令所有权重都初始化为0这个一个听起来还蛮合理的想法也许是一个我们假设中最好的一个假设了。但结果正确是一个错误(的想法),因为如果神经网络计算出来的输出值都一个样,那么反向传播算法计算出来的梯度值一样,并且参数更新值也一样()。更一般地说,如果权重初始化为同一个值,网络就不可能不对称(即是对称的)。随机初始化的目的是使对称失效。
那么网络 为什么不能是对称的?以一个三层网络为例,首先看下结构图4。
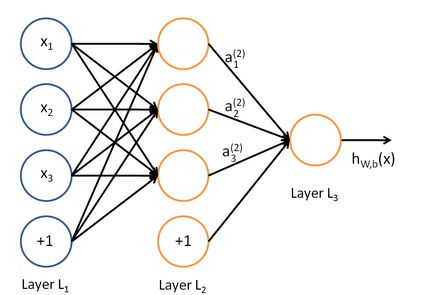
它的表达式为:
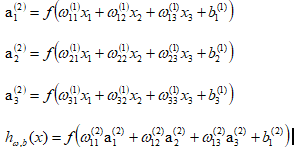
如果每个权重都一样,那么在多层网络中,从第二层开始,每一层的输入值都是相同的了也就是,既然都一样,就相当于一个输入了。如果是反向传递算法,其中的偏置项和权重项的迭代的偏导数计算公式

可以看出所得到的梯度下降法的偏导相同,不停的迭代,不停的相同,不停的迭代,不停的相同......,最后就得到了相同的值(权重和截距)。
4. 当使用caffe训练网络时,若出现accuracy急速变化后趋于稳定,但accuracy值不高。解决方案:1>调节base_lr。当accuracy不高或loss值不下降,可能造成原因是因为学习率太大,导致梯度到达某一区域内不在下降,造成寻到的最优值震荡,如图5.可以适当降低base_lr。
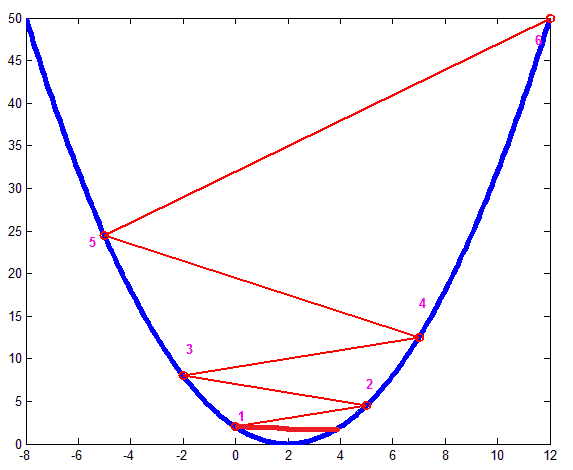
2>若调节base_lr效果不理想,可能的原因是原有的lr_policy对学习率的改变无法跳过局最
小值,如图6.我们可以通过改变lr_policy来改变训练过程部中学习率的变规律。上面我们具体介绍了不同的lr_policy对学习率的影响,那么建议从’step’作为第一个学习率调整策略,它的优点是我们可以从accuracy曲线变化中找到最佳的学习率。虽然’step’会是网络跳过局部最小值,但它也仅仅是是在前期训练起到明显得作用,当迭代次数超过一半时,学习率会急速变小,无法在跳过后续的局部最小值。而且’step’是一个过平均的过程,而loss和accuracy的变化又是一个不平均的过程,而且手动调节stepsize比较麻烦,有时在训练一些网络时,’step’并不是那么有效。将lr_policy更改为’fixed’,当base_lr设置较大时,它会很好的跳过所有的局部最小值,但是无法达到全局最优;当base_lr设置较小时,它无法跳过一些‘坑’很深的局部最小值,所以’fixed’对base_lr的要求极为苛刻。