最近项目原因需要我完成一个在树莓派上的离线语音识别,忙活了近一周,起初用了开源的PocketSphinx,但是不得不说,识别率低的惊人,甚至可以说有些字词根本没法识别,除非你自己制作声学模型,不然这玩意儿就是个摆设。
更新(2016-12-25):
百度目前对像树莓派这种设备只支持在线识别,不能用。
最后,万幸,科大讯飞提供了离线版本,而且还免费,还支持树莓派!
--------------------------------------------------------
以上两句话现在失效了,科大讯飞改版,我的离线授权貌似也过期了,只能在线。
更多关于SDK方面的信息请参考[讯飞开放平台](http://www.xfyun.cn/)
有想做语音交互的朋友请参考科大讯飞的[麦克风阵列](http://www.xfyun.cn/doccenter/mic_services)
我提供的SDK只能作为学术研究之用,每天的识别次数目前还受到了限制,有特殊需求的朋友请联系科大讯飞解决。
更新(2017-03-01):
鉴于一直有朋友询问这方面的问题,我去官方又看了一下:
1. 科大讯飞官方应该是收回了树莓派的支持库,不让免费试用了,所以我的这个资源估计是绝版了。
2. APPID是你的唯一性标识,和SDK绑定,无法替换。所以我提供的SDK是我的APPID,不过对大家的使用没有什么影响,我只能看到每天识别次数的统计等信息。
3. 这个SDK只能用作学习和调试,每天500次识别上限,商用需要联系官方。
4. 我的搭建环境是树莓派2,3没有测试过,可能会有不兼容的问题,需要树莓派3上的SDK请联系官方索要。
5. 这个SDK名称是语音听写
6. 只要你用的是树莓派2,能联网,买一个兼容的麦克风,完全照着我的博客做,肯定是不会出BUG的,所以请别私信让我帮你调BUG了。。。
7. 遇到问题多看官方的指导文档,我的水平也有限,无法一一解答。接下来,根据我的摸索,教大家如何在树莓派上搭建语音识别模块。
首先,前往讯飞开放平台下载SDK,平台选择Linux。你需要注册相关信息,最后你所下载的SDK中会自动填入你的key。
因为科大讯飞官方在新版本SDK移除了树莓派的支持,我把以前的版本上传了,供大家使用:
http://download.csdn.net/detail/yanghuan313/9616763
解压后如图
进入目录,里面有如下的文件:

我们这里直接选择进入官方所给的例子进行运行:

关键点,因为这个是Linux系统的版本,和树莓派不一样,我们需要修改一下库文件的引用路径:
首先,编辑32bit_make.sh:
sudo vim 32bit_make.sh,将内容修改为以下:

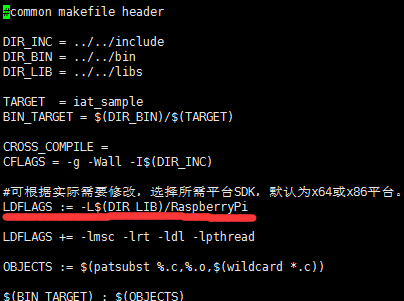
保存退出后,继续,sudo vim Makefile,修改下面划红线的位置为如图:
好了,接下来执行source 32bit_make.sh
有可能会出现权限相关的问题,建议直接从主文件递归给权限:
sudo chmod -R 774 Linux_voice_1.109
如果出现下面的内容,那就说明没什么问题了
接着,在Linux_voice_1.109/bin目录下会生成一个可执行文件:

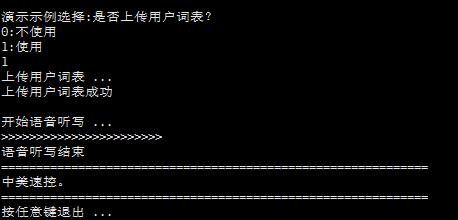
我们执行它,./iat_sample 正常情况下会显示
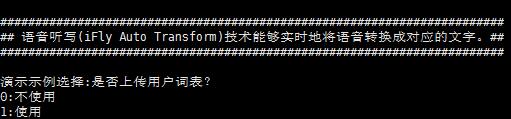
这里选0会直接识别,识别的语音为官方所给的测试语音文件,保存在当前目录的wav文件夹下,识别结果为中美数控。选1则会使用用户词表,文件为当前目录下的userwords.txt,识别结果为中美速控,原因大家自己思考。
好了,现在识别解决了,我们来解决录音的问题
我试过很多在linux下的录音软件,不是不能设置详细的参数,就是无法控制录音时间。比如sox,这个软件很好,但是我看了帮助文档发现,要停止录音必须手动Ctrl+C!
不过问题还是被我解决了:
sudo apt-get install alsa-oss
安装完以后,执行:
arecord -d 3 -r 16000 -c 1 -t wav -f S16_LE test.wav
-d : 录音时间(s)
-r : 频率
-c : 音轨
-t : 文件类型
-f : 格式
因为科大讯飞要求单音轨,16000HZ,16bit的采样,支持wav或者pcm
录音结束后,文件保存在当前目录,将它移动到bin/wav/下,并且修改文件名替换掉以前的文件。
或者你直接可以在sample/iat_sample/下修改C文件源代码,改变音频文件位置和文件名(很简单的,打开C文件,找到传路径的地方,改一下就好,改完记得重新编译)。
我们再次执行bin/iat_sample,成功识别。
在这里我只是讲述了如何实现语音识别的功能,更多的改善大家可以自己解决。
有错误的地方还望大家指正。