版权声明:本文为博主原创文章,未经博主允许欢迎转载,但请注明出处。 https://blog.csdn.net/liumiaocn/article/details/82924245
这篇文章来看一下,使用加入正态分布的噪声之后产生的数据进行训练,看是否能够得到期待的结果。

事前准备
训练数据使用如下方式生成:
xdata = np.linspace(0,1,100)
ydata = 2 * xdata + 1 + np.random.normal(20,6,xdata.shape)*0.2
示例代码
liumiaocn:tensorflow liumiao$ cat basic-operation-13.py
import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
xdata = np.linspace(0,1,100)
ydata = 2 * xdata + 1 + np.random.normal(20,6,xdata.shape)*0.2
print("init modole ...")
X = tf.placeholder("float",name="X")
Y = tf.placeholder("float",name="Y")
W = tf.Variable(-3., name="W")
B = tf.Variable(3., name="B")
linearmodel = tf.add(tf.multiply(X,W),B)
lossfunc = (tf.pow(Y - linearmodel, 2))
learningrate = 0.01
print("set Optimizer")
trainoperation = tf.train.GradientDescentOptimizer(learningrate).minimize(lossfunc)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
index = 1
print("caculation begins ...")
for j in range(100):
for i in range(100):
sess.run(trainoperation, feed_dict={X: xdata[i], Y:ydata[i]})
if j % 10 == 0:
print("j = %s index = %s" %(j,index))
plt.subplot(2,5,index)
plt.scatter(xdata,ydata)
labelinfo="iteration: " + str(j)
plt.plot(xdata,B.eval(session=sess)+W.eval(session=sess)*xdata,'b',label=labelinfo)
plt.plot(xdata,2*xdata + 1,'r',label='expected')
plt.legend()
index = index + 1
print("caculation ends ...")
print("##After Caculation: ")
print(" B: " + str(B.eval(session=sess)) + ", W : " + str(W.eval(session=sess)))
plt.show()
liumiaocn:tensorflow liumiao$
结果确认
100次迭代之后的,线性模型如下:

##After Caculation:
B: 1.46369, W : 2.0256715
没有噪声的学习过程, 收敛的如下:
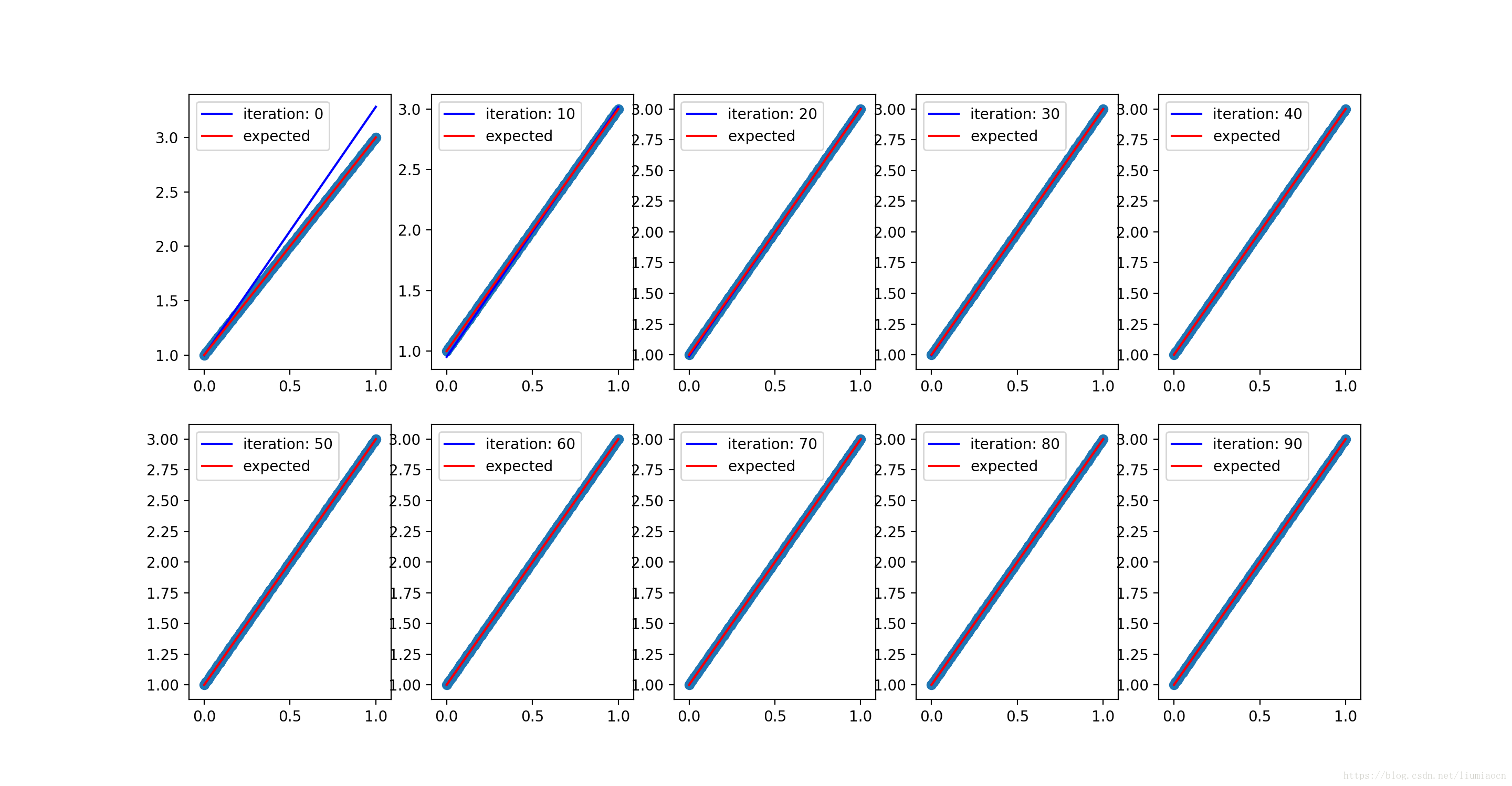
调整参数
可以看到噪声添加之后,数据产生了一个较大的偏移量,将参数进行调整
ydata = 2 * xdata + 1 + np.random.normal(20,6,xdata.shape)*0.02

可以看到数据的分布范围已经较好的收窄,但是偏差仍然存在:
##After Caculation:
B: 1.4173651, W : 1.9516094
可以直接纠偏,线性的只需要减一个常数即可,但是这个纠偏值的算出,可以有很多的方式,这里可以使用最简单的方式,比如使用均值的差
纠偏:
baisadjust=np.mean(ydata) - np.mean(B.eval(session=sess)+W.eval(session=sess)*xdata)
代码示例
liumiaocn:tensorflow liumiao$ cat basic-operation-13.py
import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
xdata = np.linspace(0,1,100)
ydata = 2 * xdata + 1 + np.random.normal(20,6,xdata.shape)*0.02
print("init modole ...")
X = tf.placeholder("float",name="X")
Y = tf.placeholder("float",name="Y")
W = tf.Variable(-3., name="W")
B = tf.Variable(3., name="B")
linearmodel = tf.add(tf.multiply(X,W),B)
lossfunc = (tf.pow(Y - linearmodel, 2))
learningrate = 0.01
print("set Optimizer")
trainoperation = tf.train.GradientDescentOptimizer(learningrate).minimize(lossfunc)
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
index = 1
print("caculation begins ...")
for j in range(100):
for i in range(100):
sess.run(trainoperation, feed_dict={X: xdata[i], Y:ydata[i]})
if j % 10 == 0:
print("j = %s index = %s" %(j,index))
plt.subplot(2,5,index)
plt.scatter(xdata,ydata)
labelinfo="iteration: " + str(j)
plt.plot(xdata,B.eval(session=sess)+W.eval(session=sess)*xdata,'b',label=labelinfo)
plt.plot(xdata,2*xdata + 1,'r',label='expected')
baisadjust=np.mean(ydata) - np.mean(B.eval(session=sess)+W.eval(session=sess)*xdata)
plt.plot(xdata,2*xdata + 1 + baisadjust, 'y', label='adjusted')
plt.legend()
index = index + 1
print("caculation ends ...")
print("##After Caculation: ")
print(" B: " + str(B.eval(session=sess)) + ", W : " + str(W.eval(session=sess)))
plt.show()
liumiaocn:tensorflow liumiao$
简单地纠偏之后,结果如下所示:

总结
这篇文章引入了另外一个概念,数据的纠偏,有噪声,自然就有去噪的方式,也可以称为纠偏。仔细思考之后会发现,如何获取噪声数据和实际期待数据之间的差值往往是实际场景中最为重要的,这篇文章引入这个概念的目的在于说明学习的过程中结果对数据的完全拟合并不一定是最好的,那个前提是数据本身就是完美数据的情况。