版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lhanchao/article/details/82889400
CSDN的博客标题长度有限制,写不全,这篇论文是2016年的一篇名为Knowing when to look: Adaptive attention via a visual sentinel for image captioning的文章,这篇文章我认为创新点特别的好,用一个十分简单的方式较大程度上提升了Image Caption的效果。
首先介绍一下这篇论文解决的问题,在我们的语言中是由一些虚词和惯用词汇的,如英语的“the”和“of”以及“behind a red stop”后接“sign”,在Image Caption生成句子时,生成这些词并不需要很多的视觉信息,而更多的来源于我们的语言模型(Language Model)。在这篇论文,作者提出了一种模型让该模型自适应(adaptive)决定什么时候更依靠视觉信息,什么时候更依靠语言模型,即让网络学习到when to look。
提出了一种新的Spatial Attention的模型;
提出了Adaptive Attention,让网络自适应的去决定依靠视觉信息或语言模型。
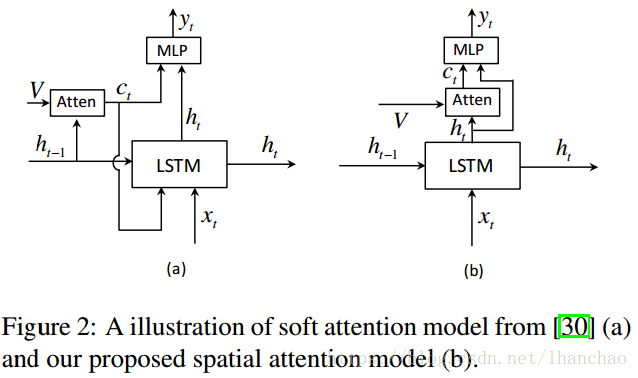
1. Spatial Attention Model 如图所示,新的Spatial Attention模型与Show, attend and tell一文中的Attention模型的差别如下:
这里的主要区别在于
c
t
c_t
c t
c
t
c_t
c t
h
t
−
1
h_{t-1}
h t − 1
h
t
h_t
h t
c
t
=
g
(
V
,
h
t
)
c_t = g(V, h_t)
c t = g ( V , h t )
g
g
g
V
=
[
v
1
,
.
.
.
,
v
k
]
V=[v_1,...,v_k]
V = [ v 1 , . . . , v k ]
v
i
∈
R
d
v_i\in\mathbb{R}^d
v i ∈ R d
v
i
=
R
e
L
U
(
W
a
a
i
)
,
a
i
v_i=ReLU(\bm{W}_a\bm{a}^i), a^i
v i = R e L U ( W a a i ) , a i
V
∈
R
d
×
y
V\in \mathbb{R}^{d \times y}
V ∈ R d × y
g
g
g
z
t
=
w
h
T
t
a
n
h
(
W
v
V
+
(
W
g
h
t
)
1
T
\bm{z_{t}} = \bm{w_{h}}^T tanh(\bm{W_vV}+(\bm{W_gh_t})\boldsymbol{1}^T
z t = w h T t a n h ( W v V + ( W g h t ) 1 T
α
t
=
s
o
f
t
m
a
x
(
z
t
)
\bm{\alpha_t}=softmax(\bm{z_t})
α t = s o f t m a x ( z t )
c
t
=
∑
i
=
1
k
α
t
i
v
t
i
\bm{c_t}=\sum_{i=1}^k\bm{\alpha_{ti}v_{ti}}
c t = i = 1 ∑ k α t i v t i
1
∈
R
k
\bm{1}\in \mathbb{R}^k
1 ∈ R k
W
v
,
W
g
∈
R
k
×
d
,
w
h
∈
R
k
,
α
∈
R
k
\bm{W_v},\bm{W_g}\in\mathbb{R}^{k\times d}, w_h\in\mathbb{R}^k, \bm{\alpha}\in \mathbb{R}^k
W v , W g ∈ R k × d , w h ∈ R k , α ∈ R k
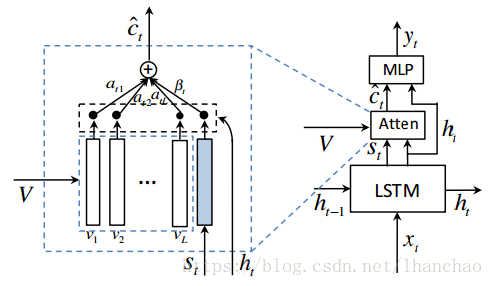
2. Adaptive Attention Model Adaptive attention的精髓在于语言信息和视觉信息权重
β
t
\beta_t
β t
β
t
\beta_t
β t
s
t
\bm{s_t}
s t
g
t
=
σ
(
W
x
x
t
+
W
h
h
t
−
1
)
\bm{g_t} = \sigma(\bm{W_xx_t}+\bm{W_hh_{t-1}})
g t = σ ( W x x t + W h h t − 1 )
b
m
s
t
=
g
t
⊙
t
a
n
h
(
m
t
)
bm{s_t}=\bm{g_t}\odot tanh(\bm{m_t})
b m s t = g t ⊙ t a n h ( m t )
m
t
\bm{m_t}
m t
⊙
\odot
⊙
x
t
\bm{x_t}
x t
x
t
=
[
w
t
;
v
g
]
,
v
g
=
R
e
L
U
(
W
b
a
g
)
,
a
g
=
1
k
∑
i
=
1
k
a
i
\bm{x_t}=[\bm{w}_t;\bm{v}^g], \bm{v}^g=ReLU(\bm{W}_b \bm{a}^g), \bm{a}^g=\frac{1}{k}\sum_{i=1}^{k}\bm{a}_i
x t = [ w t ; v g ] , v g = R e L U ( W b a g ) , a g = k 1 ∑ i = 1 k a i
β
t
\beta_t
β t
作者把
s
t
s_t
s t
α
t
\alpha_t
α t
α
^
t
=
s
o
f
t
m
a
x
(
[
z
t
;
w
h
T
t
a
n
h
(
W
s
s
t
+
(
W
g
h
t
)
)
]
)
\hat{\bm{\alpha}}_t=softmax([\bm{z}_t;\bm{w_h^T} tanh(\bm{W_ss_t}+(\bm{W_gh_t}))])
α ^ t = s o f t m a x ( [ z t ; w h T t a n h ( W s s t + ( W g h t ) ) ] )
α
^
t
\hat{\bm{\alpha}}_t
α ^ t
β
t
\beta_t
β t
c
^
t
=
β
t
s
t
+
(
1
−
β
t
)
c
t
\bm{\hat{c}}_t=\beta_t\bm{s}_t+(1-\beta_t)\bm{c_t}
c ^ t = β t s t + ( 1 − β t ) c t
p
t
=
s
o
f
t
m
a
x
(
W
p
(
c
^
t
+
h
t
)
)
\bm{p}_t=softmax(\bm{W}_p(\bm{\hat{c}}_t+h_t))
p t = s o f t m a x ( W p ( c ^ t + h t ) )