目录
01 Kafka的创建背景及其定义
Kafka是一个消息系统,原本开发自LinkedIn,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。现在它已被多家不同类型的公司 作为多种类型的数据管道和消息系统使用。Kafka作为时下最流行的开源消息系统,被广泛地应用在数据缓冲、异步通信、汇集日志、系统解耦等方面.
二、Kafka的定义
Kafka是由Scala编写,运行在JVM上面。
以前官网上面给Kafka的定义是:A distributed publish-subscribe messaging system(一个分布式发布-订阅消息传递系统),现在官网上面给出的Kafka的定义是:Apache Kafka is a distributed streaming platform(ApacheKafka是一个分布式流媒体平台)。
消息队列的类型 |
优缺点 |
RabbitMQ |
Erlang编写的一个开源的消息队列,本身支持多种协议,使的它变的非常重量级,更适合于企业级的开发。对路由(Routing),负载均衡(Load balance)或者数据持久化都有很好的支持 |
ZeroMQ |
号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZeroMQ具有一个独特的非中间件的模式,你不需要安装和运行一个消息服务器或中间件,因为你的应用程序将扮演了这个服务角色。没有持久化功能。 |
ActiveMQ |
对于Spring和Ajax的支持,支持通过JDBC提供高速的消息持久化 |
Kafka |
以时间复杂度为O(1)的方式提供消息持久化能力,并保证即使对TB级以上数据也能保证常数时间的访问性能;即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输;支持Kafka Server间的消息分区,及分布式消息消费,同时保证每个partition内的消息顺序传输;支持离线数据处理和实时数据处理 |
Redis |
数据小于10K时,Redis的入队的性能要高于RabbitMQ,Redis在出队时表现出非常好的性能,无关数据的大小。 |
名称 |
解释 |
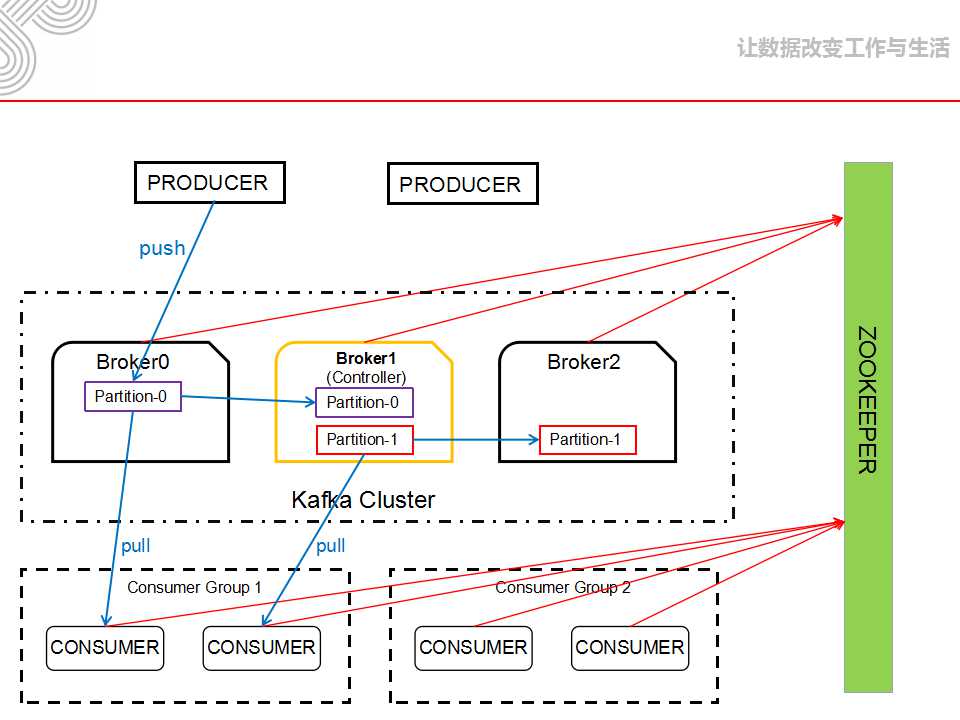
Broker |
消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
Topic |
Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
Producer |
消息生产者,向Broker发送消息的客户端 |
Consumer |
消息消费者,从Broker读取消息的客户端 |
ConsumerGroup |
每个Consumer属于一个特定的Consumer Group,一条消息可以发送到多个不同的Consumer Group,但是一个Consumer Group中只能有一个Consumer能够消费该消息 |
Partition |
物理上的概念,一个topic可以分为多个partition,每个partition内部是有序的 |
关键字 |
解释说明 |
offset |
在parition(分区)内的每条消息都有一个有序的id号,这个id号被称为偏移(offset),它可以唯一确定每条消息在parition(分区)内的位置。即offset表示partiion的第多少message |
message size |
message大小 |
CRC32 |
用crc32校验message |
magic |
表示本次发布Kafka服务程序协议版本号 |
attributes |
表示为独立版本、或标识压缩类型、或编码类型。 |
key length |
表示key的长度,当key为-1时,K byte key字段不填 |
key |
可选 |
payload |
表示实际消息数据。 |
假如我们要找offset是170418的消息(在数据存储结构图片的基础上面看更清晰一点),首先找到170410.index的文件发现offset比他大但是小于下一个index文件的文件名,所以该offset就在此index文件对应的log文件中,紧接着在index文件中查找第8(170418-170410)条信息对应的指针位置,根据该位置到对应的log文件中就可以查询到Message170418。
AR(Assigned Replicas) : 所有的副本。 AR=ISR+OSR。
ISR(In-Sync Replicas) : 副本同步队列。
OSR(Outof-Sync Replicas) : 不同步的副本队列。
阈值 :延迟时间replica.lag.time.max.ms
延迟条数replica.lag.max.messages (0.10.x开始废弃这个参数)
LEO : LogEndOffset的缩写,表示每个partition的log最后一条Message的位置。
在ISR中至少有一个follower时,Kafka可以确保已经commit的数据不丢失,但如果某一个partition的所有replica都挂了,就无法保证数据不丢失了。这种情况下有两种可行的方案:
(1)、等待ISR中任意一个replica“活”过来,并且选它作为leader
(2)、选择第一个“活”过来的replica(并不一定是在ISR中)作为leader
1(默认):这意味着producer在ISR中的leader已成功收到数据并得到确认。如果leader宕机了,则会丢失数据。
0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
-1:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是这样也不能保证数据不丢失,比如当ISR中只有leader时(前面ISR那一节讲到,ISR中的成员由于某些情况会增加也会减少,最少就只剩一个leader),这样就变成了acks=1的情况。
Kafka的发送模式由producer端的配置参数producer.type来设置,这个参数指定了在后台线程中消息的发送方式是同步的还是异步的,默认是同步的方式。
1.sync : 逐条发送(新版本已经取缔)。
2.async : 以batch的形式push数据,这样会极大的提高broker的性能,但是这样会增加丢失数据的风险。
---------------------------------------------------------------
Kafka的三种传输保障(delivery guarantee):
At most once: 消息可能会丢,但绝不会重复传输;
At least once:消息绝不会丢,但可能会重复传输;
Exactly once:每条消息肯定会被传输一次且仅传输一次。
注释:Kafka的消息传输保障机制非常直观。当producer向broker发送消息时,一旦这条消息被commit,由于副本机制(replication)的存在,它就不会丢失。但是如果producer发送数据给broker后,遇到的网络问题而造成通信中断,那producer就无法判断该条消息是否已经提交(commit)。虽然Kafka无法确定网络故障期间发生了什么,但是producer可以retry多次,确保消息已经正确传输到broker中,所以目前Kafka实现的是at least once。
consumer从broker中读取消息后,可以选择commit,该操作会在Zookeeper中存下该consumer在该partition下读取的消息的offset。该consumer下一次再读该partition时会从下一条开始读取。如未commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。
当然也可以将consumer设置为autocommit,即consumer一旦读取到数据立即自动commit。如果只讨论这一读取消息的过程,那Kafka是确保了exactly once, 但是如果由于前面producer与broker之间的某种原因导致消息的重复,那么这里就是at least once。
Producer端,需要自己创造多线程并发环境才能提高客户端的出口吞吐量。
二、Consumer的并发
任意Partition在某一个时刻只能被一个Consumer Group内的一个Consumer消费(反过来一个Consumer则可以同时消费多个Partition),Kafka非常简洁的Offset机制最小化了Broker和Consumer之间的交互,这使Kafka并不会像同类其他消息队列一样,随着下游Consumer数目的增加而成比例的降低性能。此外,如果多个Consumer恰巧都是消费时间序上很相近的数据,可以达到很高的PageCache命中率,因而Kafka可以非常高效的支持高并发读操作,实践中基本可以达到单机网卡上限。
consumers |
[consumer-group] |
ids |
[consumer_id] |
consumer ID |
offsets |
topic/partition_id |
用来跟踪每个consumer group目前所消费的partition中最大的offset |
||
owners |
topic/[partition_id] |
用来标记partition被哪个consumer消费,为临时节点 |
||
admin |
重新分配分区,副本的选举,删除的主题 |
|||
config |
topics的配置 |
|||
controller |
存储center controller(中央控制器)所在kafka broker的信息。 |
|||
brokers |
ids |
[0...N] |
{ "jmx_port": -1, //JMX的端口号 "timestamp": "1460082147315",//broker启动的时间戳 "host": "xx.xxx.xxx.xxx",//host "version": 1,//默认的版本 "port": 9092 //broker进程的对外监听的端口号} |
|
topics |
[topic]/partitions/[0...N] |
{"controller_epoch": 17,//中央控制器的总的选举次数 "leader": 0, //此partition的broker leader的id "version": 1, //默认版本号 "leader_epoch": 1,//此partition的leader选举的次数 "isr": [0] //同步副本组brokerId顺序列表} |
||
controller_epoch |
此值为一个数字,kafka集群中第一个broker第一次启动时为1,以后只要集群中center controller(中央控制器)所在broker变更或挂掉,就会重新选举新的center controller,每次center controller变更controller_epoch值就会 + 1; |
|||
只做Sequence I/O,规避了磁盘访问速度低下对性能可能造成的影响。Kafka重度依赖底层操作系统提供的PageCache功能,避免在JVM内部缓存数据。
2.消息的获取
一个持久化的队列可以构建在对一个文件的读和追加上,所有的操作都是常数时间,并且读写之间不会相互阻塞。这种设计具有极大的性能优势:最终系统性能和数据大小完全无关,服务器可以充分利用廉价的硬盘来提供高效的消息服务。 事实上还有一点,磁盘空间的无限增大而不影响性能这点,意味着我们可以提供一般消息系统无法提供的特性。比如说,消息被消费后不是立马被删除,我们可以将这些消息保留一段相对比较长的时间(比如一个星期)。
为了减少大量小I/O操作的问题,kafka的协议是围绕消息集合构建的。Producer一次网络请求可以发送一个消息集合,而不是每一次只发一条消息。在server端是以消息块的形式追加消息到log中的,consumer在查询的时候也是一次查询大量的线性数据块。
持久化log 块的网络传输。流行的unix操作系统提供了一种非常高效的途径来实现页面缓存和socket之间的数据传递。在Linux操作系统中,这种方式被称作:sendfile system call