自幼好文,尤喜古诗词。无奈生活所迫,弃文从IT至今好多年。最近和女儿一起看中国诗词大会,又激起了我对古诗词的兴趣。已经借助Spark用Scala对唐诗宋词做过中文分词统计,这次就想着能否做得更多一点,试试自动集句。
所谓集句,就是从现有的诗句中,按条件如藏头,步韵等等,按体裁格律要求,选择现成诗句,重新组合成一首新的诗作。
集句一直是古代文人的一种雅趣,许多人都曾有过集句的作品。如南宋文天祥,少年时期集杜甫诗句于一诗,以表达投笔从戎的志向:读书破万卷(《赠韦右丞》),许身一何愚(《自京赴奉先县咏怀五百字》)。赤骥顿长缨(《述古》),健儿胜腐儒(《草堂》)。这是集一个人的诗句,也可以集多人的诗句,如汤显祖《牡丹亭》的下场诗:《惊梦》 春望逍遥出画堂(张说),闲梅遮柳不胜芳(罗隐)。可知刘阮逢人处(许浑)?回首东从一断肠(韦庄)。集四个诗人各一句。
古人要做集句诗,作者只有博闻强记,才能集句成诗。而且要求对原诗句融会贯通,如出一体。这样集成的诗才能既无斧凿之气,意义又相连贯。 如今信息时代,电脑之强闻博记,超过人类多少倍不止,用电脑来自动集句,结果会怎么样?
去年开始学习Spark框架,Spark SQL是其中一个非常重要组件,我就想着用Spark SQL来做集句。想法很简单,实现上也看不出什么问题,但是做起来却是非常艰苦。断断续续竟然搞了10个月,今天总算大体完毕,虽然尚有不尽人意的地方,我还是觉得有写下来的必要,一个是个人阶段总结,一个是与同好分享。
整个工程建立在Spark1.6的框架之上,采用sqlite数据库,工程结构如下图所示:
整个工程分三个package:com.magicstudio.db存放的是和sqlite数据库交互的java代码,这一部分是直接从原来的java工程中复制过来的,借助于Scala和Java在JVM上的无缝融合特性,省去了不少工作量。
com.magicstudio.entity存放了数据库保存诗歌列表,诗歌内容和诗歌韵部的三张表的数据对象封装,实现从实体向数据库的ORM转换,也很简单,没什么可以说的。
工程的主要内容在com.magicstudio.spark这个包中:顾名思义,其中SparkPoetUI是界面显示,和用户交互的;SparkPoet是后台使用Spark SQL,进行诗歌浏览及自动集句功能实现的;而PoetComboBox是一个客制化的Scala下拉框组件,可以动态更新下拉框内容,修复了Scala Swing中下拉框组件不能动态更新内容的bug;PoetTableModel则是在table组件中列表显示诗歌浏览及集句结果的后台model;HiSpark是一个参考的调用Spark SQL的例子,与本工程无关,可以忽略。
工程运行后的界面如下:
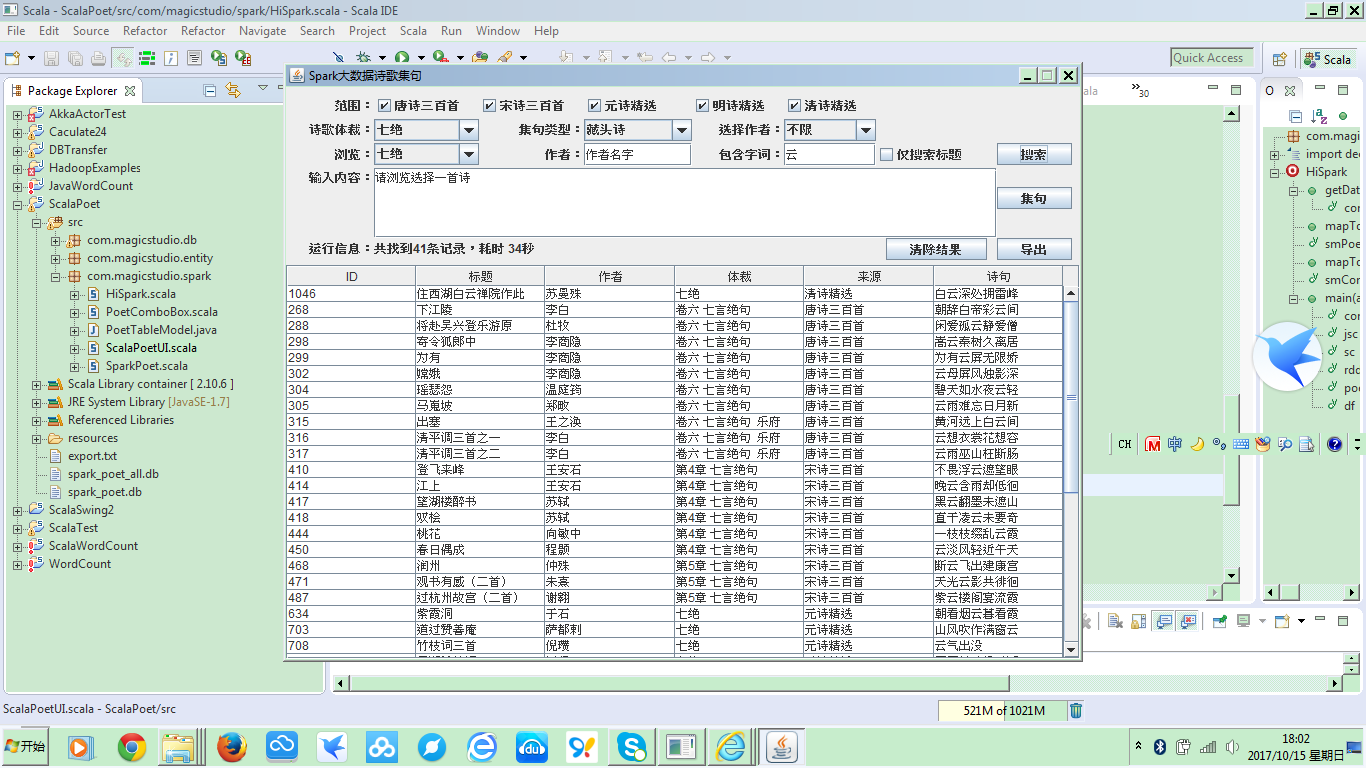
这里已经是显示了查询所有包含“云”字的诗句的查询结果。我在想,如果使用这个,玩中国诗词大会的飞花令,那岂不是要打遍天下无敌手???
和所有的电脑系统一样,整个系统都是由数据输入,数据处理和数据输出三部分组成。在BI或大数据应用,数据输入就是ETL,在这个工程里面就是把唐诗三百首,宋诗三百首等文本导入到sqlite数据库中,使之后续可以为Spark SQL可用。其主要的方法都写在DataManager这个类中:
这一部分工作相对比较简单,从文本文件解析出诗歌内容,然后封装成后台实体对象,然后存入sqlite数据库。只是导入全唐诗已经全宋诗,非常费时,分成好多次,执行了好多天才把数据导入完毕。以后可能要想办法换数据库或者优化下导入的方法。
数据输出在BI或大数据要称作数据可视化,有很多炫酷的功能,在我们这里就是简单的一个列表显示。Table列表显示Scala Swing组件中的Table兼容javax swing中的table model的数据源,简单扩展后就可以使用,并且可以动态刷新数据内容;而Scala Swing中的ComboBox却始终无法实现动态刷新下拉框内容的功能。因为我想实现根据用户所选不同诗歌来源,如唐诗三百首,宋诗三百首等等,动态加载作者列表的功能(后来由于执行太过费时,而没有使用)。尝试了很久,都无法成功,后来上网搜索,才发现这是Scala Swing组件的一个Bug。不过还好,最终在网上找到了客制化ComboBox以Fix这个bug的代码,最终解决了这个问题。
整个应用主要有两个功能:一个是诗歌的浏览查询功能,一个是自动集句功能。
诗歌的浏览查询,可以选择范围,诗歌体裁,作者,诗句或诗题关键字,点击搜索按钮之后,后台会调用SparkPoet中的searchPoem方法,把前台选择的范围,诗歌体裁, 作者,关键字,是否只在诗题中查找传入,进行Spark SQL的查询。
当然,在查询之前,先要对SparkPoet执行initSpark方法:
//初始化spark
def initSpark(appName:String){
val conf = new SparkConf().setMaster("local").setAppName(appName)
jsc = new JavaSparkContext(conf)
//jsc.setLogLevel("ERROR");
sc = new SQLContext(jsc)
}
进行初始化,创建JavaSparkContext和SQLContext对象(实际上,initSpark是在SparkPoetUI的加载过程中执行的)。
开始查询后,首先执行:
@transient
val rdd = new JdbcRDD(
jsc,
() => {
Class.forName("org.sqlite.JDBC").newInstance()
DriverManager.getConnection("jdbc:sqlite:spark_poet.db")
},
"SELECT * FROM poem_list where id>=? and id <=?",
//1, 235281, 2,
1, 1052, 2,
r => mapToPoemRow(r)
)
把数据库中的所有诗歌都读入到JdbcRDD中。其中注释掉的235281是导入了全唐诗全宋诗后的诗歌总数,由于数据量过大,导致查询和集句非常缓慢,所以后来就使用了不包含全唐诗和全宋诗共计1052首诗的精简版本。工程 代码中spark_poet_all.db包含所有的数据,spark_poet.db是精简后的数据。其中mapToPoemRow方法从jdbc的resultset中创建一个JdbcRDD的row。
然后执行:
@transient
var df = sc.createDataFrame(rdd, smPoem)
创建出DataFrame.
对于MySql数据库,可以用:
val jdbcDF = sqlContext.load("jdbc",
Map("url" -> "jdbc:mysql://localhost:3306/your_databaseuser=your_user&password=your_password", "dbtable" -> "your_table"))
直接加载出DataFrame,但是sqlite数据库使用这种方法,却始终无法编译成功,更换了sqlite的jdbc驱动也没有用。
创建出DataFrame之后,就是根据条件进行过滤了:
df = df.filter("source in " + source.mkString("('", "','", "')"))
if ((format.equalsIgnoreCase("不限") == false) && (format.isEmpty() == false)){
df = df.filter("format like " + getFormatCondition(format))
}
if ((author.equalsIgnoreCase("作者名字") == false) && (author.isEmpty() == false)){
df = df.filter("author='" + author + "'")
}
Spark SQL提供的DataFrame的过滤功能使我们能像操作数据库表一样对数据进行条件过滤。
上面只是查出了诗歌的基本信息,诗歌的每一行诗句的内容都放在另一表poem_content中,所以,还需要把诗歌内容加载进来,和诗歌列表一样,加载成JdbcRDD:
@transient
val rddContent = new JdbcRDD(
jsc,
() => {
Class.forName("org.sqlite.JDBC").newInstance()
DriverManager.getConnection("jdbc:sqlite:spark_poet.db")
},
"SELECT * FROM poem_content where id>=? and id <=?",
//1, 2160694, 2,
1, 10561, 2,
r => mapToContentRow(r)
)
再创建成DataFrame:
val df2 = sc.createDataFrame(rddContent, smContent)
然后与诗歌DataFrame按poem_id进行join,就像两个table join一样:
df = df.join(df2, df("id") === df2("poem_id"))
这时再加上最后一个过滤条件:关键字
if ((keyword.equalsIgnoreCase("关键字词") == false) && (keyword.isEmpty() == false)){
if (onlyInTitle){
df = df.filter("title like '%" + keyword + "%'")
} else {
df = df.filter("content like '%" + keyword + "%'")
}
}
这时利用Scala的集合操作,调用 getDataframeAsList,对df中的每条诗句的数据都附加上整首诗的内容作为一个栏位:
val model = getDataframeAsList(df, df2)
//把搜索到的DataFrame转换为用于table显示的list
def getDataframeAsList(df:DataFrame, df2:DataFrame):List[java.util.List[String]] = {
val content: Array[java.util.List[String]] = for (row <- df.sort(df("poem_id").asc).select("poem_id","title","author","format","source","content").collect)
yield List(row.getString(0),row.getString(1),row.getString(2),row.getString(3),
row.getString(4), row.getString(5),
getDataframeAsString(df2.filter("poem_id=" + row.getString(0)))).asJava
content.toList
}
其中,getDataframeAsString定义如下:
//把一首诗的诗句连在一起
def getDataframeAsString(df:DataFrame):String = {
val content: Array[String] = for (row <- df.select("content").collect)
yield row.getString(0)
content.toList.mkString("", ",", "")
}
最后,把整个model的数据转换成java list,返回给前台:
model.distinct.asJava
前台把data model赋值给table:
val startDate = new java.util.Date()
action = "searching"
val poems = poet.searchPoem(selectedSource, cboFormat2.selection.item,
txtAuthor.text.trim(), txtKeyword.text.trim(), chkTitle.selected)
lblMessage.peer.setText("共找到" + poems.size() + "条记录,耗时 " +
(((new java.util.Date()).getTime - startDate.getTime) / 1000) + "秒")
table.peer.setModel(new PoetTableModel())
table.model = new PoetTableModel(poems)
最后显示出查询结果如图所示:
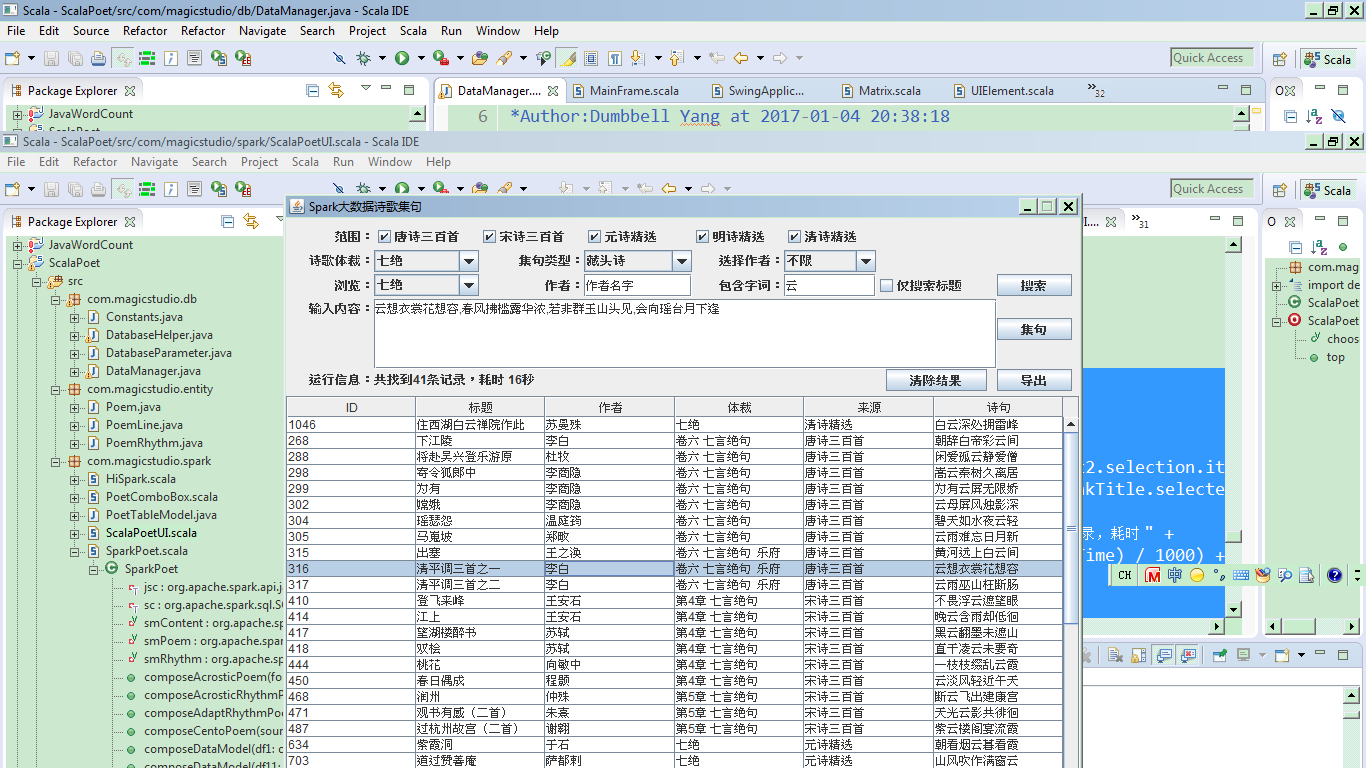
单击某行诗句,会在输入内容中显示整首诗的内容。例如我们选择了李白的清平调三首之一,输入框中就会显示整首诗的内容,我们可以选择诗歌体裁,七绝,五绝还是七律,五律,集句类型,藏头诗,步韵诗还是藏头步韵诗,也可以选择作者,然后根据这首诗的内容进行自动集句。由于性能限制,总共只有1052首诗,容量不够大,所以集句效果不佳。
单击集句按钮,首先会各项检查:
//至少选择一个来源
if (selectedSource.isEmpty){
Dialog.showMessage(parent = null,
title = "提示",
message = "请选择集句的范围")
selectPanel.requestFocus()
} else
//参考的诗不能为空
if (inputPane.text.isEmpty() || inputPane.text == "请浏览选择一首诗"){
Dialog.showMessage(parent = null,
title = "提示",
message = "请输入或浏览选择一首集句的参考诗")
inputPane.requestFocus()
} else
if (checkInputAndFormat(inputPane.text, cboFormat.selection.item) == false){
Dialog.showMessage(parent = null,
title = "提示",
message = "输入的参考诗或文字要和所选体裁相匹配!")
inputPane.requestFocus()
} else {
检查通过后,执行SparkPoet的composeCentoPoem方法,进行自动集句:
val startDate = new java.util.Date()
action = "collecting"
val sentences = poet.composeCentoPoem(selectedSource,
cboFormat.selection.item,
cboMethod.selection.item, cboPoet.item,
inputPane.text.trim(), selectedPoemId)
lblMessage.peer.setText("共找到" + sentences.size() + "条诗句,耗时 " +
(((new java.util.Date()).getTime - startDate.getTime) / 1000) + "秒")
table.peer.setModel(new PoetTableModel())
table.model = new PoetTableModel(List("ID", "标题", "作者", "来源", "诗句", "叶韵", "句式").asJava,sentences)
返回数据时,由于列表栏位已有变化,所以,需要调用PoetTableModel的重载方法,重新赋值栏位名称和数据。
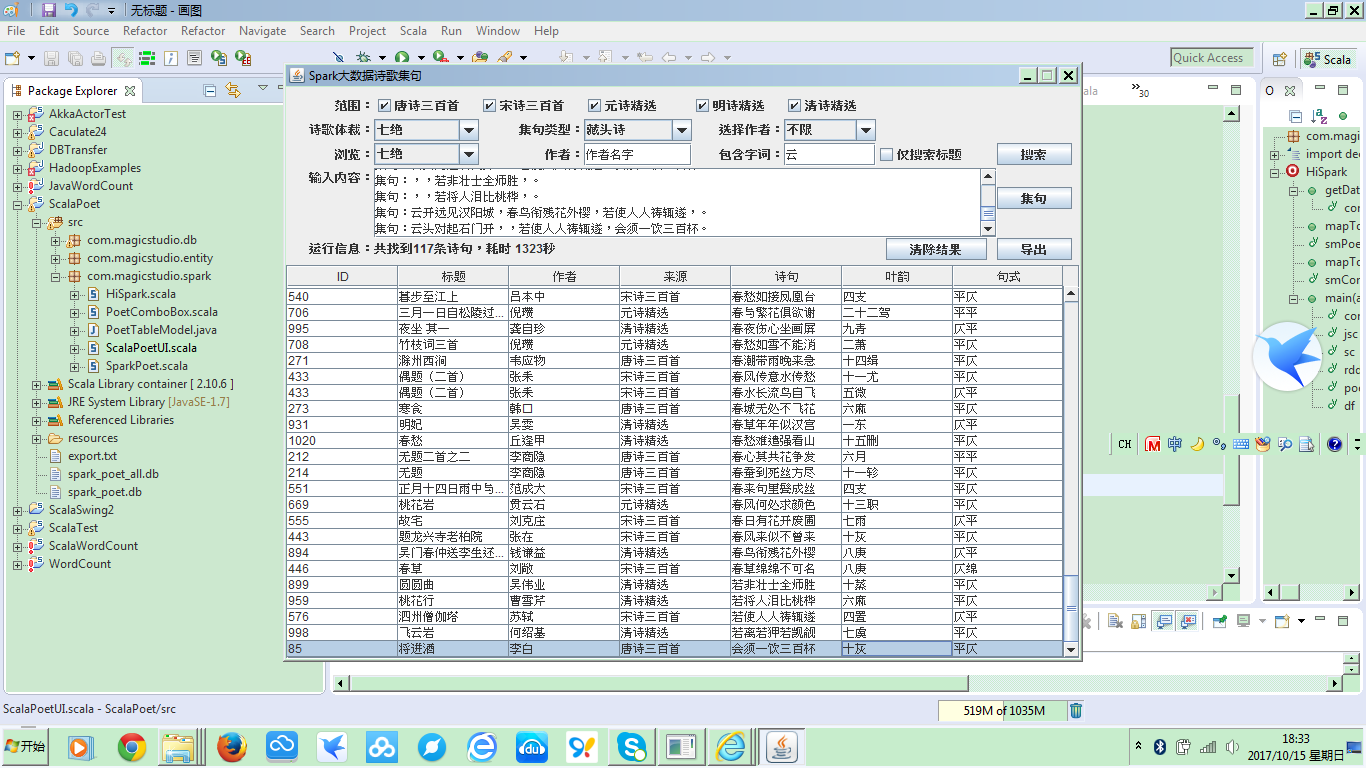
最终的集句结果如下图:
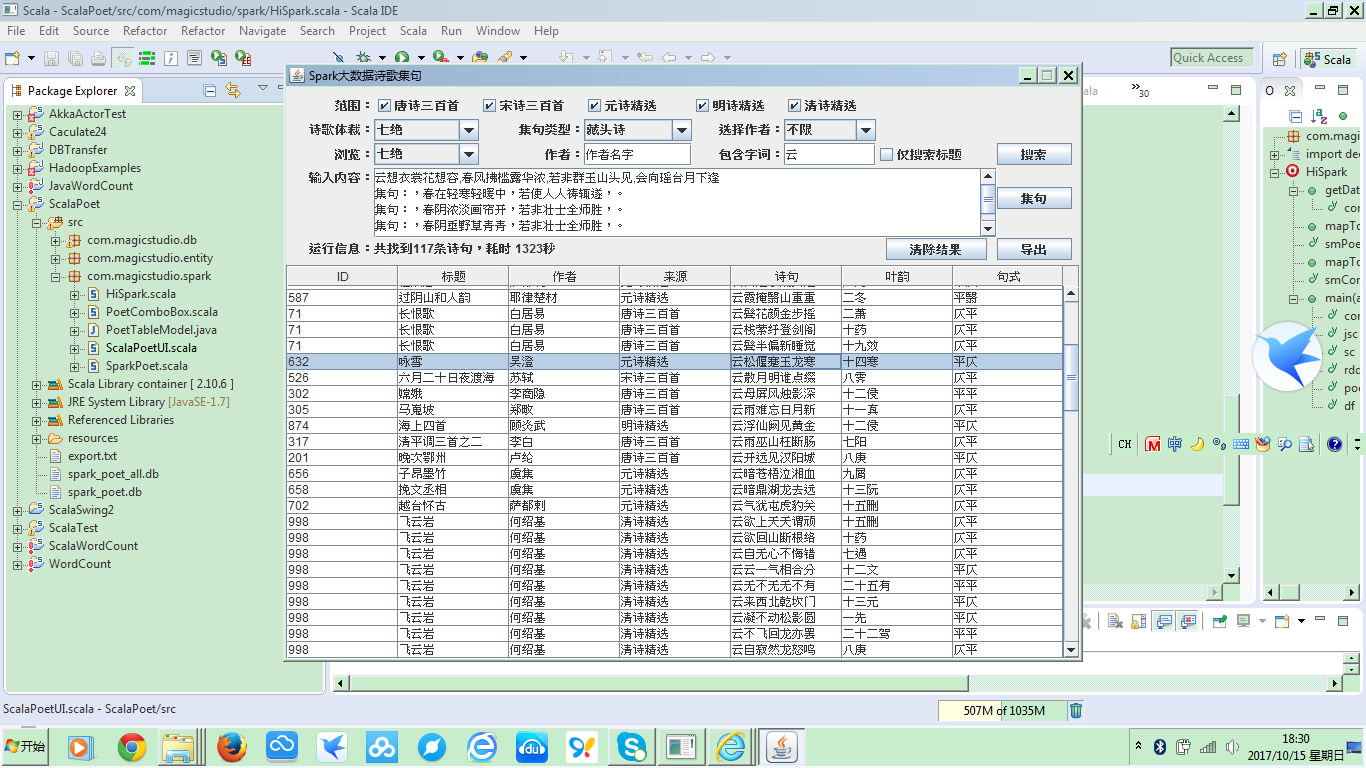
列表会显示出备选诗句的叶韵和句式,单击诗句会显示出集句的结果。由于诗歌总数不够,所以导致无法集句出完整的七绝。只能集到两句或三句,有的甚至只有一句:
集句的后台逻辑处理,首先获取诗韵,转换成DataFrame:
//集句
def composeCentoPoem(source:List[String], format:String, method:String, author:String,
originPoem:String, selectedPoemId:String):java.util.List[java.util.List[String]]={
//获取诗韵
@transient
val rddRhythm = new JdbcRDD(
jsc,
() => {
Class.forName("org.sqlite.JDBC").newInstance()
DriverManager.getConnection("jdbc:sqlite:spark_poet.db")
},
"SELECT * FROM poem_rhythm where id>=? and id <=? and type='平水韵'",
1, 163, 2,
r => mapToRhythmRow(r)
)
//转换为dataframe
@transient
val dfRhythm = sc.createDataFrame(rddRhythm, smRhythm)
然后获取诗歌列表,同样转换为DataFrame,并进行来源和作者的条件过滤,同时,过滤掉当前选择的诗歌:
//获取诗歌列表
@transient
val rddPoem = new JdbcRDD(
jsc,
() => {
Class.forName("org.sqlite.JDBC").newInstance()
DriverManager.getConnection("jdbc:sqlite:spark_poet.db")
},
"SELECT * FROM poem_list where id>=? and id <=?",
1, 1052, 2,
r => mapToPoemRow(r)
)
//转换为dataframe并过滤
@transient
var dfPoem = sc.createDataFrame(rddPoem, smPoem)
//来源过滤
dfPoem = dfPoem.filter("source in " + source.mkString("('", "','", "')"))
//作者过滤
if ((author.equalsIgnoreCase("不限") == false) && (author.isEmpty() == false)){
dfPoem = dfPoem.filter("author='" + author + "'")
}
//过滤掉当前选择的诗
dfPoem = dfPoem.filter("id != " + selectedPoemId);
然后,加载诗歌内容,转换为DataFrame并与诗歌DataFrame join:
//获取诗句列表
@transient
val rddContent = new JdbcRDD(
jsc,
() => {
Class.forName("org.sqlite.JDBC").newInstance()
DriverManager.getConnection("jdbc:sqlite:spark_poet.db")
},
"SELECT * FROM poem_content where id>=? and id <=?",
1, 10561, 2,
r => mapToContentRow(r)
)
//转换为dataframe并与诗歌列表关联
val dfContent = sc.createDataFrame(rddContent, smContent)
val df = dfPoem.join(dfContent, dfPoem("id") === dfContent("poem_id"))
接下来,对选择的用于集句的原诗进行处理,提取出每个诗句的首字(藏头诗要用)和尾字(步韵诗要用),以及原诗的韵部(当以不押韵的诗句进行集句时要用):
val arrOrigin = originPoem.split(",")
val headWords = for (i <- 0 to arrOrigin.length - 1) yield arrOrigin(i).charAt(0)
val tailWords = for (i <- 0 to arrOrigin.length - 1) yield arrOrigin(i).charAt(arrOrigin(i).size - 1)
//获取原诗的韵脚,后面集句时,如果以未叶韵的诗句作为开始,则采用原诗的韵脚
//先看第二句
val word2 = tailWords(1).toString()
var rhythm = getWordRhythm(word2, dfRhythm)
if (word2 == rhythm){ //如果韵脚就是韵字本身,说明未找到,再看第四句
val word4 = tailWords(3).toString()
rhythm = getWordRhythm(word4, dfRhythm)
}
最后,根据用户选择不同的集句方式,分别进行处理:
method match{
case "藏头诗" => composeAcrosticPoem(format, headWords, df, dfRhythm, rhythm)
case "步韵诗" => composeAdaptRhythmPoem(format, originPoem, df, dfRhythm, rhythm)
case "藏头步韵诗" => composeAcrosticRhythmPoem(format, originPoem, df, dfRhythm, rhythm)
}
在这里,我们只分析下藏头诗自动集句的流程和代码,步韵诗和藏头步韵诗的流程和代码基本都是相同的。
在composeAcrosticPoem方法中,先根据传入的format,获取诗句的长度,然后去诗歌内容的DataFrame中查找出首字与原诗各句首字相同的诗句DataFrame,如果是绝句,会有4个DataFrame,律诗,则有8个DataFrame:
//藏头诗
def composeAcrosticPoem(format:String, headWords:IndexedSeq[Char], contentDF:DataFrame,
rhythmDF:DataFrame, originRhythm:String):
java.util.List[java.util.List[String]]={
//val arrOrigin = originPoem.split(",")
val len = format match {
case "五绝" => 5
case "七绝" => 7
case "五律" => 5
case "七律" => 7
}
if (format.endsWith("绝")){
//val df1 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) in " + headWords.mkString("('","','","')"))
//分别取得四个字为首的诗句集合
val df1 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(0) + "'")
val df2 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(1) + "'")
val df3 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(2) + "'")
val df4 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(3) + "'")
composeDataModel(df1, df2, df3, df4, rhythmDF, originRhythm)
} else {
val df11 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(0) + "'")
val df12 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(1) + "'")
val df21 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(2) + "'")
val df22 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(3) + "'")
val df31 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(4) + "'")
val df32 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(5) + "'")
val df41 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(6) + "'")
val df42 = contentDF.filter("length(content) = " + len).filter("substr(content,1,1) = '" + headWords(7) + "'")
composeDataModel(df11, df12, df21, df22, df31, df32, df41, df42, rhythmDF, originRhythm)
}
}
然后调用composeDataModel方法,对各个DataFrame进行处理,完成集句功能。绝句的集句和律诗的集句在处理上基本是一样的,这里我们只分析绝句的集句处理。
//组装绝句的table model数据
def composeDataModel(df1:DataFrame, df2:DataFrame, df3:DataFrame, df4:DataFrame,
rhythmDF:DataFrame, originRhythm:String):
java.util.List[java.util.List[String]]={
val s1 = getPoemLineData(1, df1, df2, df3, df4, rhythmDF, originRhythm)
val s2 = getPoemLineData(2, df1, df2, df3, df4, rhythmDF, originRhythm)
val s3 = getPoemLineData(3, df1, df2, df3, df4, rhythmDF, originRhythm)
val s4 = getPoemLineData(4, df1, df2, df3, df4, rhythmDF, originRhythm)
//val model = getComposePoemAsList(df1.unionAll(df2.unionAll(df3.unionAll(df4))))
//model.distinct.asJava
s1.union(s2.union(s3.union(s4))).toList.asJava
}
在composeDataModel方法中,调用getPoemLineData方法,分别按四句诗DataFrame中的每一句作为种子,去其他各句的DataFrame中去找符合集句要求的诗句,组成集句的结果最后union起来,转换为java list,传回前台table model显示数据。
getPoemLineData方法利用Scala的集合操作运算,对每条诗句,附加了一个调用getCollectPoem方法获得的集句结果的栏位:
//获取每行诗句绝句格式的集句结果用于table显示
def getPoemLineData(order:Int, df1:DataFrame, df2:DataFrame, df3:DataFrame,
df4:DataFrame, rf:DataFrame, originRhythm:String):Array[java.util.List[String]]={
var mdf = df1
order match{
case 1 => mdf = df1
case 2 => mdf = df2
case 3 => mdf = df3
case 4 => mdf = df4
}
for (row <- mdf.select("poem_id","title","author","source","content").collect)
yield List(row.getString(0),row.getString(1),row.getString(2),
row.getString(3), row.getString(4),
getPoemLineRhythm(row.getString(4), rf),
getPoemLineMode(row.getString(4), rf),
getCollectPoem(order, row.getString(4), originRhythm, rf,
df1 , df2 , df3, df4)).asJava
}
在getCollectPoem方法中,首先获取当前处理诗句的韵部和平仄句式,然后根据当前处理的诗句顺序,如果是第一句,就去集符合格式和韵律要求的第二,第三和第四句;如果是第二句,就去集第一句,第三句和第四句;绝句的第三句不要求押韵,所以,集 第三句时,不需要韵律的条件;如果当前处理的诗句是第三句,韵部就要用传入的原诗的韵部:
def getCollectPoem(order:Int, poemLine : String, originRhythm:String, rf:DataFrame,
df1 : DataFrame, df2 : DataFrame, df3:DataFrame, df4:DataFrame):String={
val rhythm = getPoemLineRhythm(poemLine, rf)
val mode = getPoemLineMode(poemLine, rf)
mode match {
case "平仄" => {
order match{
case 1 => List(poemLine,
getPoemLine(rhythm, "仄平", df2, rf),
getPoemLine("仄平", df3, rf),
getPoemLine(rhythm, "平仄", df4, rf)).mkString("集句:",",","。")
case 2 => List(getPoemLine(rhythm, "仄平", df1, rf),
poemLine,
getPoemLine("平仄", df3, rf),
getPoemLine(rhythm, "仄平", df4, rf)).mkString("集句:",",","。")
//第三句没有韵脚,采用原诗的诗韵
case 3 => List(getPoemLine(originRhythm, "仄平", df1, rf),
getPoemLine(originRhythm, "平仄", df2, rf),
poemLine,
getPoemLine(originRhythm, "仄平", df4, rf)).mkString("集句:",",","。")
case 4 => List(getPoemLine(rhythm, "平仄", df1, rf),
getPoemLine(rhythm, "仄平", df2, rf),
getPoemLine("仄平", df3, rf),
poemLine).mkString("集句:",",","。")
}
}
case "仄平" => {
order match{
case 1 => List(poemLine,
getPoemLine(rhythm, "平仄", df2, rf),
getPoemLine("平仄", df3, rf),
getPoemLine(rhythm, "仄平", df4, rf)).mkString("集句:",",","。")
case 2 => List(getPoemLine(rhythm, "平仄", df1, rf),
poemLine,
getPoemLine("仄平", df3, rf),
getPoemLine(rhythm, "平仄", df4, rf)).mkString("集句:",",","。")
//第三句没有韵脚,采用原诗的诗韵
case 3 => List(getPoemLine(originRhythm, "平仄", df1, rf),
getPoemLine(originRhythm,"仄平", df2, rf),
poemLine,
getPoemLine(originRhythm, "平仄", df4, rf)).mkString("集句:",",","。")
case 4 => List(getPoemLine(rhythm, "仄平", df1, rf),
getPoemLine(rhythm, "平仄", df2, rf),
getPoemLine("平仄", df3, rf),
poemLine).mkString("集句:",",","。")
}
}
case _ => "" //无法确定句式,返回空
}
}
获取诗句韵脚调用getPoemLineRhythm根据诗句的尾字,在传入的韵部DataFrame中查找即可。
获取诗句的句式,调用getPoemLineMode,根据诗句的第二字和第四字,分别在传入的韵部DataFrame中查找,如果该字出现在平声韵部中,则为平声,否则为仄声,从而决定诗句的平仄格式。绝句的诗句格式一般五言为平仄或仄平,七言为平仄平或者仄平仄,有所谓一三五不论,二四六分明的说法。所以上面判断句式,取第二字和第四字即可。
集句调用getPoemLine方法:
//从诗句集合中获取满足条件的诗句, 带韵脚
def getPoemLine(rhythm:String, mode:String, df:DataFrame, rf:DataFrame):String = {
val s = getPoemLineRhythmAndMode(df,rf).filter { x => x.get(1) == rhythm && x.get(2) == mode }
if (s.size > 0){
s.head.get(0)
} else {
""
}
}
//从诗句集合中获取满足条件的诗句, 不带韵脚
def getPoemLine(mode:String, df:DataFrame, rf:DataFrame):String = {
val s = getPoemLineRhythmAndMode(df,rf).filter { x => x.get(2) == mode }
if (s.size > 0){
s.head.get(0)
} else {
""
}
}
获取首条符合记录的诗句,与原有的诗句组成一个List,并使用mkString方法,把集成的四句诗组成一个字符串,作为原有诗句的集句结果栏位附加到原有的诗句列表中,最终返回到前台界面显示。
至此,利用Spark SQL进行诗歌查询及自动集句的功能基本实现了,诗歌查询基本可用,但自动集句则由于性能问题导致数据集过小,从而无法获得有效的集句结果。而且由于对Scala语法不熟悉,每一步功能实现都是尝试多次,历时许久才能完成,从而导致整个工程从一月开始,到十月完成,期间Spark版本已经从1.6升级到了2.2.。后续如果有时间的话,我会尝试使用Spark2.2,结合MySql数据库,导入全唐诗和全宋诗,对自动集句的功能进行优化和改进。
本工程的全部代码包含数据库文件都已上传到CSDN,下载链接为:http://download.csdn.net/download/yangdanbo1975/10022729