直接撸代码:
package com.ldp.test.util;
import java.util.LinkedList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class threadTetsUtils {
final static Random random = new Random();
private static List<Integer> l =null;
final static int count = 200000;
public static void poolThreadMethod(){
//System.currentTimeMillis()计算1970年1月1号 00:00:00 到现在的总毫秒数。
l = new LinkedList<Integer>();
long startTime = System.currentTimeMillis();
ThreadPoolExecutor tp = new ThreadPoolExecutor(1, 1, 60,
TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(count));
for(int i=0;i<count;i++){
tp.execute(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
l.add(random.nextInt());
}
});
}
tp.shutdown();
try {
tp.awaitTermination(1, TimeUnit.DAYS);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("线程池:"+String.valueOf(System.currentTimeMillis()-startTime)+"毫秒");
System.out.println(l.size());
}
public static void newThradMethod(){
//System.currentTimeMillis()计算1970年1月1号 00:00:00 到现在的总毫秒数。
l = new LinkedList<Integer>();
long startTime = System.currentTimeMillis();
for(int i=0;i<count;i++){
Thread thread = new Thread(){
public void run() {
l.add(random.nextInt());
}
};
thread.start();
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("线程:"+String.valueOf(System.currentTimeMillis()-startTime)+"毫秒");
System.out.println(l.size());
}
public static void main(String[] args) {
poolThreadMethod();
newThradMethod();
}
}以上看得懂的码农,请忽略以下内容,点击关闭上面那个叉叉+OO
-------------------------------------------------------------------------------------------------------------------------------
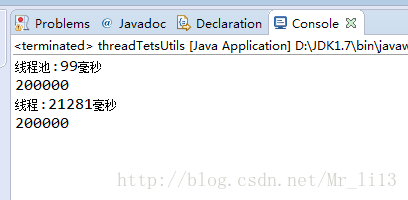
执行结果:
线程池官方构造方法:
ThreadPoolExecutor
(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory,RejectedExecutionHandler handler)别人There扣过来说明下哈
1.corePoolSize(线程池的基本大小):当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads方法,线程池会提前创建并启动所有基本线程。
2.workQueue任务队列):用于保存等待执行的任务的阻塞队列。可以选择以下几个阻塞队列。
ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序。
LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列
SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
3.maximumPoolSize(线程池最大大小):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是如果使用了无界的任务队列这个参数就没什么效果。
4.ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程做些更有意义的事情,比如设置daemon和优先级等等
5.RejectedExecutionHandler(饱和策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。以下是
JDK1.5提供的四种策略。
AbortPolicy:直接抛出异常。
CallerRunsPolicy:只用调用者所在线程来运行任务。
DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
DiscardPolicy:不处理,丢弃掉。也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化不能处理的任务。
6.keepAliveTime(线程活动保持时间):线程池的工作线程空闲后,保持存活的时间。所以如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。
7.TimeUnit(线程活动保持时间的单位):可选的单位有天(DAYS),小时(HOURS),分钟(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。
上面两种方式的差异在于线程池采用的是复用线程,而不用复用线程的另外一种方式则需要每次创建成,在同样执行200000次的任务,复用线程耗99毫秒,而创建线程的方式则耗时比较大了,尽然达到2万毫秒!!这还是只创建随机数这样的简单任务,若是有耗内存较大的任务时,差距就会更大。
除了上面ThreadPoolExecutor方式外,还有ScheduledThreadPoolExecutor定时任务线程池的方法, 不过需要注意的是Executors.newCachedThreadPool()这个返回的线程池是没有线程上限的,在使用的时候要 当心,因为没办法控制总体的线程量,可能导致内存占用过多,个人建议尽量选择有线程上限的线程方法来做需求。
详细说明线程池可借鉴: http://blog.csdn.net/a837199685/article/details/50619311