博主自己学习,仅此记录,并方便学过c、已经配置好cuda的朋友交流学习。(我机子cuda9.0)
前面我们已经回顾了C语言,并在cuda工程里编了c的样例,今天开始了解cuda的简单知识。
gpu的优势
ok先借由nvidia官网(https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#introduction)展示一下为啥用gpu,而不利用gpu,下图是每秒的浮点计算。
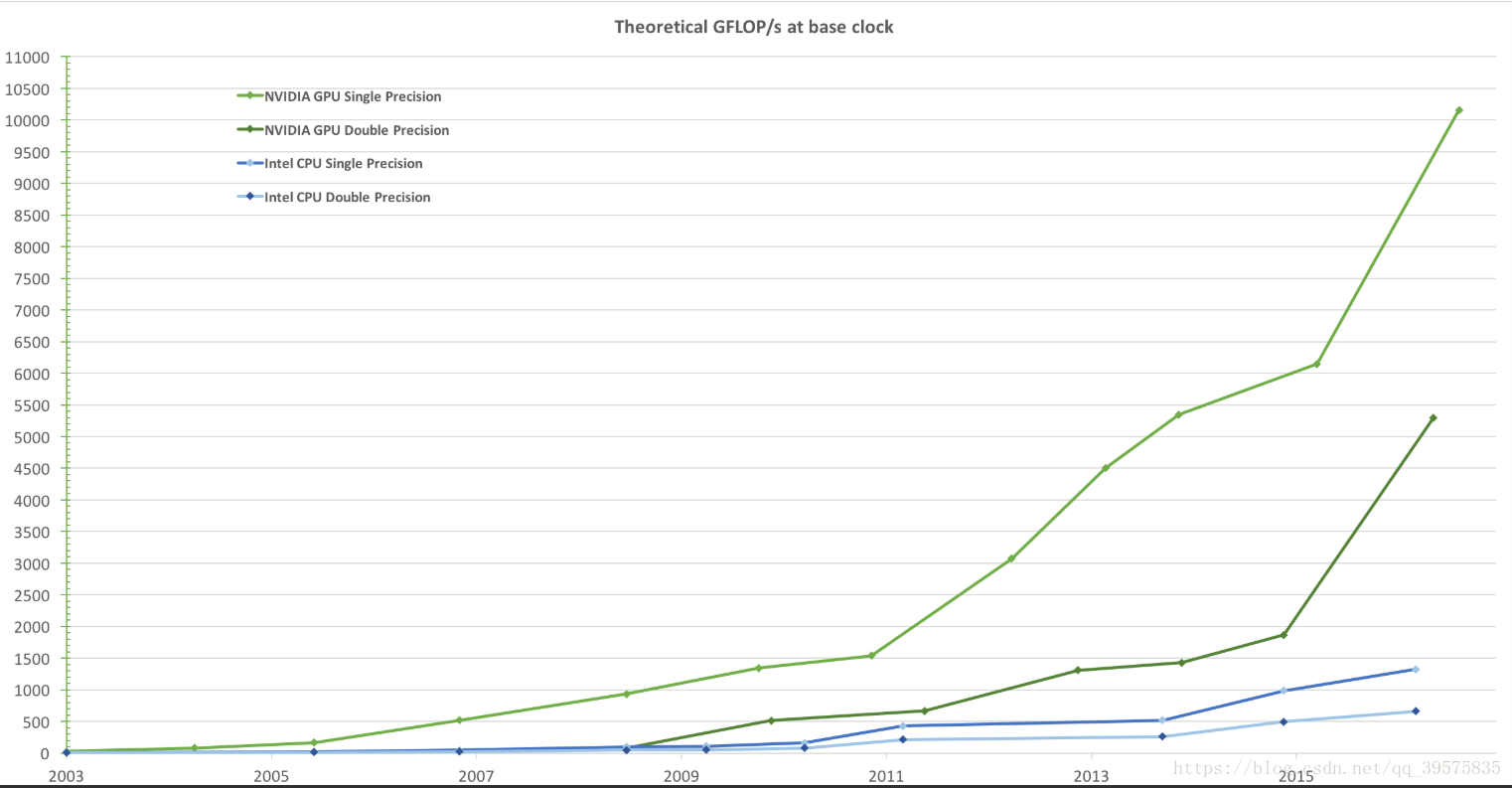
为啥gpu那么快?官网提到:
The reason behind the discrepancy in floating-point capability between the CPU and the GPU is that the GPU is specialized for compute-intensive, highly parallel computation - exactly what graphics rendering is about - and therefore designed such that more transistors are devoted to data processing rather than data caching and flow control, as schematically illustrated by Figure 3.
CPU和GPU之间差异背后的原因在,浮点能力中,gpu是专门用于计算密集,高速并行计算,尤其图形渲染的,因此,设计更多的晶体管用于数据处理,而不是数据缓存和流控制(而cpu是),如图3示意图所示。所以gpu数据处理的单元更多如下图。
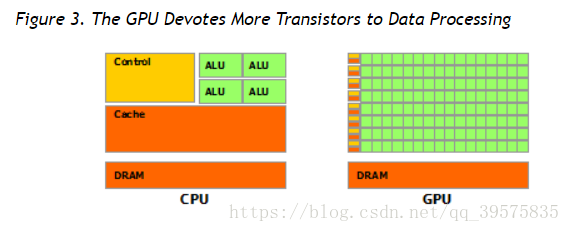
ok,现在应该知道了gpu的优势了,那我们开始学习gpu的一些结构,方便以后的开发。
Kernels
官方:
CUDA C extends C by allowing the programmer to define C functions, called kernels, that, when called, are executed N times in parallel by N different CUDA threads, as opposed to only once like regular C functions.
CUDA C通过允许程序员定义名为内核的C函数来扩展C语言,当被调用时,它会被N个不同的CUDA线程并行执行N次,而不是像常规的C函数那样。
A kernel is defined using the __global__ declaration specifier and the number of CUDA threads that execute that kernel for a given kernel call is specified using a new <<<...>>>execution configuration syntax (see C Language Extensions). Each thread that executes the kernel is given a unique thread ID that is accessible within the kernel through the built-in threadIdx variable.
内核是使用__global__说明符来定义的,并且使用新的执行配置语法(参见C语言扩展)。执行内核的每一个线程都有一个独一无二的线程ID(thread ID),它可以通过内置的threadIdx变量在内核中访问,(thradIdx 相当于指针索引thread id的感觉)
eg:
__global__ void VecAdd(float* A, float* B, float* C)
{...}
VecAdd<<<1, N>>>(A, B, C);
vecadd是一个kernel,通过__global__ 定义;- dg=1,代表网格中线程块数;
- db=N,代表线程块中的线程数目;
- A,B,C是threadIdx 索引,很明显,这个是三维的;
这里做一下说明:threadIDX可以是1-d,2-d,3-d。线程的索引及其线程ID以直接的方式相互关联:对于一维块,它们是相同的; 对于大小为二维的块(D x,D y),索引(x,y)的线程的线程ID 是(x + y D x) ; 对于大小为三维的块 (D x,D y,D z),索引(x,y,z)的线程的线程ID 是(x + y D x+ z D x D y)。
下图以二维的线程块作为实例:
a kernel can be executed by multiple equally-shaped thread blocks, so that the total number of threads is equal to the number of threads per block times the number of blocks.
内核可以由多个相等的线程块来执行(下图上半部分),这样线程的总数就等于每个块的线程数乘以块的数量。一个块又分为很多线程(二维时如下图)
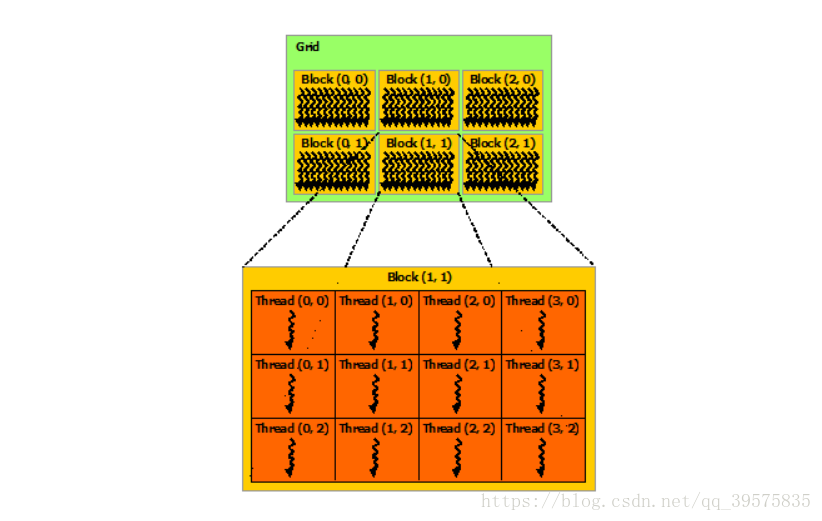
ok,至此为止,线程与线程块应该有比较基本的了解了。
参考:《cuda高性能并行计算》
nvidia:https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#introduction