##目的:对网易新闻app进行自媒体号进行数据采集
工具: fiddler4,IDEA
前置技能点:
- Java基础,基本语法,文件操作,Date类应用,maven的配置等
- fiddler抓包
- 生产者 消费者模型的Java实现
- Java httpclient包的基本运用
- JSONObject类的运用
##流程:
###1. 用fiddler对网易新闻app进行抓包研究(此处最为复杂,又难以归纳出通用的法则)
下面给出几个关键的url
简介获取网址: http://c.m.163.com/nc/subscribe/abstract/自媒体id.html
以T1436178714849这个自媒体id为例
以get方式对该url进行请求,获取到下列返回数据,经过观察,我们可以发现该串json数据中的desc键描述了该自媒体的简介信息
{
"abstractList": [
{
"topicid": "051187K4",
"ename": "T1437980175117",
"img": "http://dingyue.nosdn.127.net/CPyl06T14=6lx2V=Gy8BzwbDVnng40gvC2mkcTZmgYTvn1488900231940.jpg",
"hasIcon": true,
"tname": "智观察",
"subnum": "9164",
"topic_icons": "http://dingyue.nosdn.127.net/CPyl06T14=6lx2V=Gy8BzwbDVnng40gvC2mkcTZmgYTvn1488900231940.jpg",
"tid": "T1437980175117"
},
{
"topicid": "0511838M",
"ename": "T1426650607511",
"img": "http://img1.ph.126.net/0JLWi3-AFGkp_IJ39FzhTQ==/6619378857584634163.jpg",
"hasIcon": true,
"tname": "芯智讯",
"subnum": "1万",
"topic_icons": "http://img1.ph.126.net/0JLWi3-AFGkp_IJ39FzhTQ==/6619378857584634163.jpg",
"tid": "T1426650607511"
},
{
"topicid": "0511831Q",
"ename": "T1425885645380",
"img": "http://img2.ph.126.net/NiwTiVUjwMyfEbGGNuiAyA==/6630195852978107453.jpg",
"hasIcon": true,
"tname": "华强北在线",
"subnum": "1.5万",
"topic_icons": "http://img2.ph.126.net/NiwTiVUjwMyfEbGGNuiAyA==/6630195852978107453.jpg",
"tid": "T1425885645380"
}
],
"abstractType": "similar",
"desc": "3D打印在线(www.3d2013.com)是由世界3D打印技术产业联盟与中国3D打印技术产业联盟联袂主办的3D打印行业首家在线交易平台,是3D打印行业权威的信息资讯门户。"
}
同理对名称,别名等信息获取网址: http://c.m.163.com/nc/subscribe/v2/topic/自媒体id.html
利用get方式进行请求,获取下列json数据,可以通过该数据获取到自媒体的名称(tname),粉丝数(subnum),别名(alias)等信息
{
"tab_list": [
{
"tab_type": "all",
"tab_name": "文章"
},
{
"tab_type": "abstract",
"tab_name": "简介"
}
],
"subscribe_info": {
"template": "normal1",
"ename": "T1436178714849",
"passport": "dDmPEbeEDNJpDRGAlWMCEmWlYJxG7i/ExMsC/IX1t2E=",
"hasCover": false,
"topic_background": "http://img2.cache.netease.com/m/newsapp/reading/cover1/C1374477668016.jpg",
"certificationUrl": "http://mp.163.com/mobile/auth.html#/index",
"hasIcon": true,
"alias": "www.3d2013.com",
"tname": "3D打印在线",
"topic_icons": "http://dingyue.nosdn.127.net/Tg1kLhUOqzABq3i6HE7gyPJkHSeLxyRjDjqq43hrEFZWS.jpg",
"subnum": "8746",
"cid": "C1374477668016"
}
}
通过app的搜索功能来获取自媒体的id
url:http://c.m.163.com/nc/topicset/v5/searchByPage/android/" + 从搜索结果的第几项开始+ "-20.html
利用post方式进行请求获取(注意构建header和RequestBody)
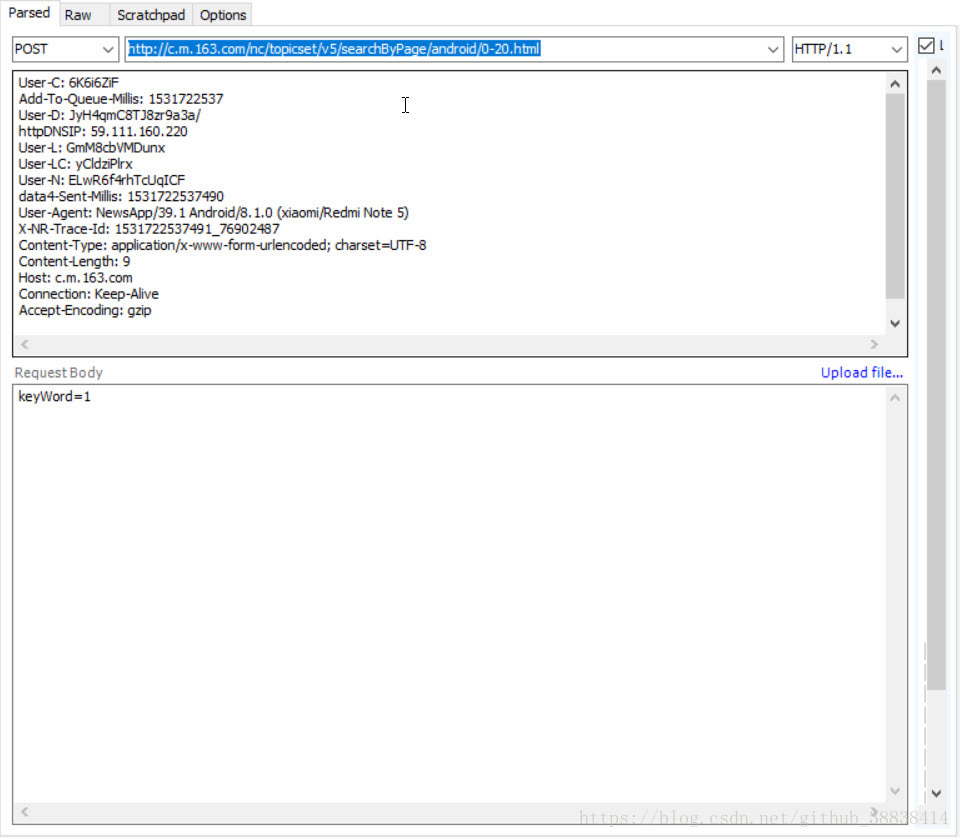
获取结果
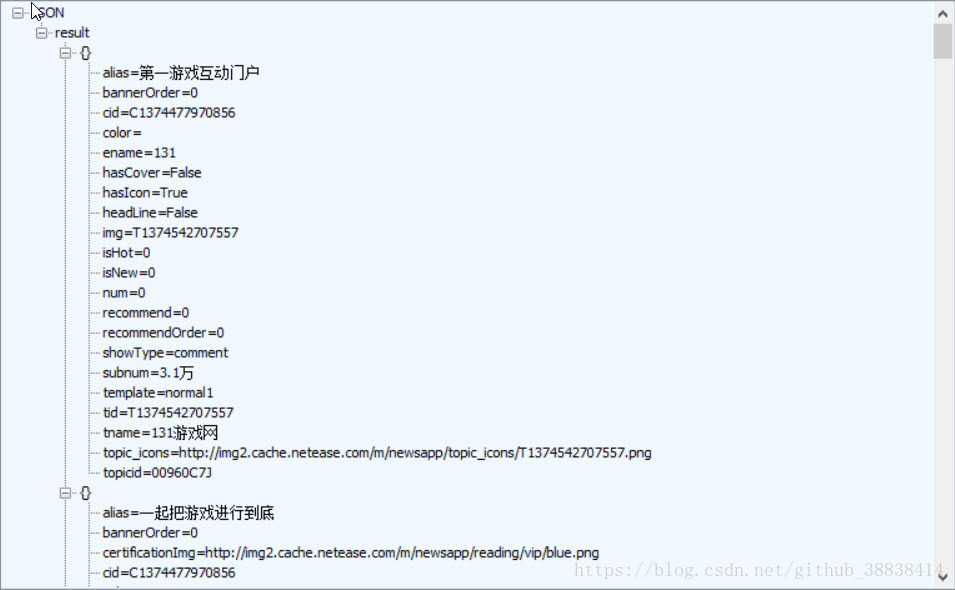
2.利用maven导入相关包
主要是JSONObject依赖,httpclient依赖
<dependencies>
<!-- jsoup解析依赖包 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.7.3</version>
</dependency>
<!-- JSONObject依赖-->
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>net.sf.ezmorph</groupId>
<artifactId>ezmorph</artifactId>
<version>1.0.3</version>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
<!-- httpclient依赖 -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.6</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.3</version>
</dependency>
</dependencies>
3. 根据爬取流程确定架构
我们爬取一个自媒体信息的过程,首先是通过构建搜索url来获取一系列的自媒体的id,然后才通过其id与简介url和名称url爬取该自媒体的简介信息与名称信息
这很自然的构成了一个生产者-消费者模型
所以一只爬虫需要两类线程,一类生产者(负责爬取自媒体id),一类消费者(负责通过id补全自媒体其他信息)
实现代码
生产者
package thread;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import util.Filter;
import util.URLUtil;
import vo.PageVo;
import java.util.List;
import java.util.concurrent.BlockingQueue;
/**
* 通过网易app搜索引擎获取自媒体名单
*/
public class ThirdThread implements Runnable
{
BlockingQueue<PageVo> queue;
Filter filter;
//TODO 测试时设置上限
static int MaxNum = 0;
final String filePath = "D:/wangyiApp/";
public ThirdThread(BlockingQueue<PageVo> queue)
{
this.queue = queue;
filter = new Filter();
}
@Override
public void run()
{
List<String> stringList = URLUtil.getGB2312List();
//对搜索关键词进行遍历
for (String s : stringList)
{
int num = 0;
String data = null;
//对单个关键词的结果进行遍历
while (true)
{
String httpUrl = "http://c.m.163.com/nc/topicset/v5/searchByPage/android/" + num + "-20.html";
num += 20;
try
{
data = URLUtil.doPost(httpUrl, "keyWord=" + URLUtil.getEncodedBase64(s));
JSONObject jsonObject = JSONObject.fromObject(data);
//获取其他公众号网址
JSONArray jsonArray = jsonObject.getJSONArray("result");
//当结果页结束时,换下一个搜索词
if (jsonArray.size() == 0)
{
break;
}
for (int i = 0; i < jsonArray.size(); i++)
{
System.out.println("线程" + Thread.currentThread().getName() + "容量" + queue.remainingCapacity());
//当队列剩余容量小于2时,丢弃该公众号网页
if (queue.remainingCapacity() < 2)
{
}
PageVo vo = new PageVo();
// 遍历 jsonarray 数组,把每一个对象转成 json 对象
JSONObject job = jsonArray.getJSONObject(i);
// 得到自媒体id
String ID = job.getString("tid");
vo.setId(ID);
/**
* 对网址去重
*/
if (filter.Contain(ID))
{
System.out.println("爬取到一条重复记录");
continue;
}
vo.setUrl(ID);
queue.put(vo);
System.out.println(ID);
}
} catch (Exception e)
{
e.printStackTrace();
}
}
}
}
}
消费者
package thread;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import util.FileUtil;
import util.Filter;
import util.URLUtil;
import vo.PageVo;
import java.util.concurrent.BlockingQueue;
/**
* 一号线程,爬取对应自媒体的简介,名称等信息
*
* 简介获取网址: http://c.m.163.com/nc/subscribe/abstract/自媒体id.html
* 名称,别名等信息获取网址: http://c.m.163.com/nc/subscribe/v2/topic/自媒体id.html
*/
public class FirstThread implements Runnable
{
BlockingQueue<PageVo> queue;
Filter filter;
//TODO 测试时设置上限
static int MaxNum = 0;
final String filePath="D:/wangyiApp/";
public FirstThread(BlockingQueue<PageVo> queue)
{
this.queue = queue;
filter = new Filter();
}
@Override
public void run()
{
while (true)
{
//TODO 测试用
synchronized (this)
{
MaxNum++;
}
try
{
PageVo pageVo = queue.take();
//构建简介获取网址
String descUrl="http://c.m.163.com/nc/subscribe/abstract/"+pageVo.getId()+".html";
JSONObject jsonObject = JSONObject.fromObject(URLUtil.doGet(descUrl));
String desc = jsonObject.getString("desc");
pageVo.setDescription(desc);
//构建名称等信息获取网址
String msgUrl="http://c.m.163.com/nc/subscribe/v2/topic/"+pageVo.getId()+".html";
JSONObject jsonObject2 = JSONObject.fromObject(URLUtil.doGet(msgUrl));
JSONObject msg=jsonObject2.getJSONObject("subscribe_info");
pageVo.setAlias(msg.getString("alias"));
pageVo.setAvatarsUrl(msg.getString("topic_icons"));
pageVo.setName(msg.getString("tname"));
//将subnum中的xx万转为数字
String tmp=msg.getString("subnum");
if (tmp.length()>1&&tmp.substring(tmp.length()-1).equals("万"))
{
float tmp2= Float.parseFloat(tmp.substring(0,tmp.length()-1));
pageVo.setFanNum(String.valueOf((int) (tmp2*10000)));
}
pageVo.setUrl(msgUrl);
//标注为网易
pageVo.setSite("netease");
//储存
FileUtil.save(pageVo,filePath);
// //获取其他公众号网址
// JSONArray jsonArray = jsonObject.getJSONArray("abstractList");
//
// for (int i = 0; i < jsonArray.size(); i++)
// {
// System.out.println("线程"+Thread.currentThread().getName()+"容量"+queue.remainingCapacity());
// //当队列剩余容量小于2时,丢弃该公众号网页
// if (queue.remainingCapacity() < 2)
// {
//
// }
// PageVo vo = new PageVo();
//
// // 遍历 jsonarray 数组,把每一个对象转成 json 对象
// JSONObject job = jsonArray.getJSONObject(i);
// // 得到 每个对象中的属性值
// String ID = job.getString("ename");
// vo.setId(ID);
//
//
// /**
// * 对网址去重
// */
// if (filter.Contain(ID))
// {
// System.out.println("爬取到一条重复");
// continue;
// }
// vo.setUrl(ID);
// queue.put(vo);
//
// System.out.println();
// }
}catch (Exception e)
{
}
}
}
}
可能遇到的问题:
####NO1.fiddler抓不到包,真心玄学问题,试过各种解决方法包括利用wireshark从底层抓包,都没有解决,在这一步卡了快一天,最后发现重装了一下网易新闻app。。。。就好了,好了,了
####No2.用被爬取app的搜索引擎,然后就想到了利用常用的汉字作为搜索关键词,然而,去那去找这些常用的汉字表呢?此时很自然的就想到了gb2312字符集。所以此时需要遍历gb2312字符集
//对gb2312字符集遍历
try
{
//遍历gb2312汉字编码分区
for (int i=0xB0;i<0xF7;i++)
{
//遍历每个分区中的汉字
for (int j=0xA1;j<0xFF;j++)
{
byte[] bytes=new byte[2];
bytes[0]= (byte) i;
bytes[1]= (byte) j;
short tmp= (short) (i+j);
String s = new String(bytes, "gb2312");
System.out.println(s);
}
}
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
No3.网易app的搜索汉字使用base64编码的(常识),但一时想不到可能就会很迷
/**
* 通过jdk8的util类中的Base64类实现 base64编码
* @param plainText
* @return
*/
public static String getEncodedBase64(String plainText)
{
String encoded = null;
try
{
byte[] bytes = plainText.getBytes("UTF-8");
encoded = Base64.getEncoder().encodeToString(bytes);
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
return encoded;
}
####No4. set的线程安全问题,因为爬虫肯定涉及到去重问题,在数据量不大时,常直接采用set去重,然而set并不是线程安全滴,在爬虫这种典型的多线程应用中,肯定是不行的,此时可以通过利用synchronizedSet使set线程安全(private static Set set= Collections.synchronizedSet(new HashSet());),当然,也可以自己通过synchronized实现
###思考:app爬虫和一般的网络爬虫的区别
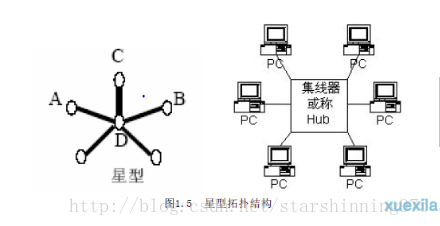
app的各个网址(节点)分布就类似于计网中的星型拓扑结构,各个页面间一般没用能直接跳转到其他页面的url(或者是只有同一类的页面间能相互跳转),所以普通页面就相当于星型结构中的周围节点。而中心节点则是app的搜索url,只有通过app的搜索功能才能找到这些周围节点
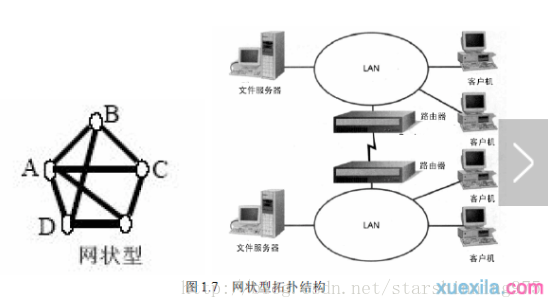
而一般的网络爬虫,则是网状模型,一般来说,重任意节点都能很容易的遍历整个网络