前言
在应用层通过设置PooledByteBufAllocator来执行ByteBuf的分配,但是最终的内存分配工作被委托给PoolArena。由于Netty通常用于高并发系统所以各个线程进行内存分配时竞争不可避免,这可能会极大的影响内存分配的效率,为了缓解高并发时的线程竞争,Netty允许使用者创建多个分配器(Arena)来分离锁提高内存分配效率
GitHub地址:https://github.com/RobertoHuang
PoolArena源码分析
PoolArena类是逻辑意义上一块连续的内存,之所以说它是逻辑的因为该类不涉及到具体的内存存储。PoolArena是由多个Chunk组成的大块内存区域,而每个Chunk则由一个或者多个Page组成。PoolArena的内部结构如下图
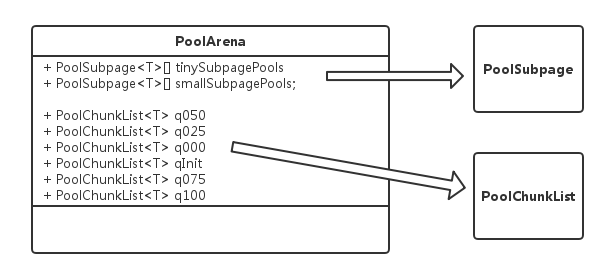
成员变量
以下是PoolArena中一些比较重要的成员变量
// 分配PoolArena的类
final PooledByteBufAllocator parent;
// 以下属性来自parent
final int pageSize;
final int pageShifts;
final int chunkSize;
private final int maxOrder;
// 数组默认长度为32(512 >>4)
// Netty认为小于512子节的内存为小内存即tiny tiny按照16字节递增 比如16,32,48
private final PoolSubpage<T>[] tinySubpagePools;
// 数组默认长度为4 pageShifts-4
// Netty认为大于等于512小于pageSize(8192)的内存空间为small
// small内存是翻倍来组织,也就是会产生[0,1024),[1024,2048),[2048,4096),[4096,8192)
private final PoolSubpage<T>[] smallSubpagePools;
// 存储内存利用率50-100%的chunk
private final PoolChunkList<T> q050;
// 存储内存利用率25-75%的chunk
private final PoolChunkList<T> q025;
// 存储内存利用率1-50%的chunk
private final PoolChunkList<T> q000;
// 存储内存利用率0-25%的chunk
private final PoolChunkList<T> qInit;
// 存储内存利用率75-100%的chunk
private final PoolChunkList<T> q075;
// 存储内存利用率100%的chunk
private final PoolChunkList<T> q100;构造方法
在PoolArena的构造方法中,主要是对以上成员变量进行初始化操作
protected PoolArena(PooledByteBufAllocator parent, int pageSize, int maxOrder, int pageShifts, int chunkSize, int cacheAlignment) {
// 初始化参数
this.parent = parent;
this.pageSize = pageSize;
this.maxOrder = maxOrder;
this.pageShifts = pageShifts;
this.chunkSize = chunkSize;
directMemoryCacheAlignment = cacheAlignment;
directMemoryCacheAlignmentMask = cacheAlignment - 1;
subpageOverflowMask = ~(pageSize - 1);
// 初始化tinySubpagePools
tinySubpagePools = newSubpagePoolArray(numTinySubpagePools);
for (int i = 0; i < tinySubpagePools.length; i ++) {
tinySubpagePools[i] = newSubpagePoolHead(pageSize);
}
// 初始化smallSubpagePools
numSmallSubpagePools = pageShifts - 9;
smallSubpagePools = newSubpagePoolArray(numSmallSubpagePools);
for (int i = 0; i < smallSubpagePools.length; i ++) {
smallSubpagePools[i] = newSubpagePoolHead(pageSize);
}
// 创建6个不同使用率的PoolChunkList
q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize);
q075 = new PoolChunkList<T>(this, q100, 75, 100, chunkSize);
q050 = new PoolChunkList<T>(this, q075, 50, 100, chunkSize);
q025 = new PoolChunkList<T>(this, q050, 25, 75, chunkSize);
q000 = new PoolChunkList<T>(this, q025, 1, 50, chunkSize);
qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize);
// 使用链表维护PoolChunkList
q100.prevList(q075);
q075.prevList(q050);
q050.prevList(q025);
q025.prevList(q000);
q000.prevList(null);
qInit.prevList(qInit);
List<PoolChunkListMetric> metrics = new ArrayList<PoolChunkListMetric>(6);
metrics.add(qInit);
metrics.add(q000);
metrics.add(q025);
metrics.add(q050);
metrics.add(q075);
metrics.add(q100);
chunkListMetrics = Collections.unmodifiableList(metrics);
}PoolArena中的六个PoolChunkList通过链表串联,结构如下图所示
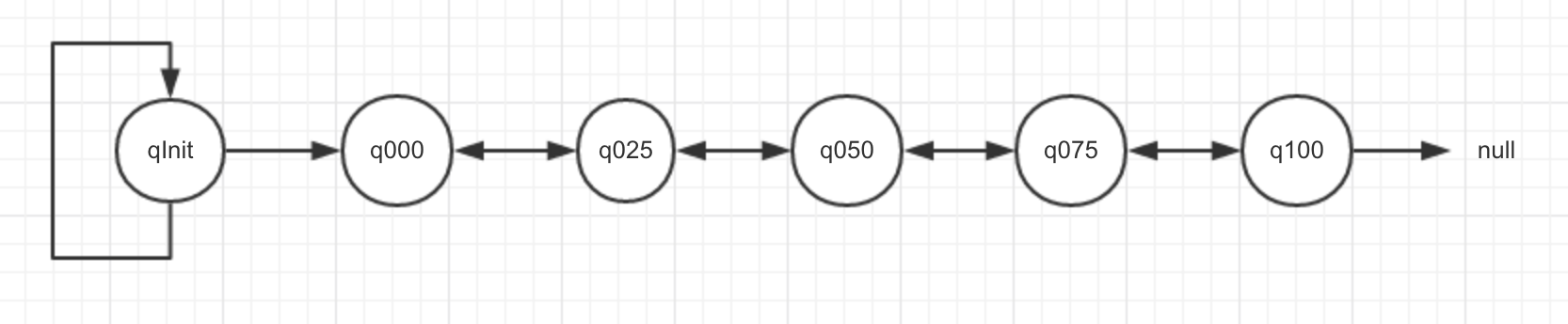
为什么链表是这样的顺序排列的
qInit前置节点为自己且minUsage=Integer.MIN_VALUE,这意味着一个初始分配的chunk在最开始的内存分配过程中(内存使用率<25%),即使完全释放也不会被回收会始终保留在内存中,q000没有前置节点,当一个chunk进入到q000列表,如果其内存被完全释放则不再保留在内存中,其分配的内存被完全回收。并且随着chunk中page的不断分配和释放会导致很多碎片内存段,大大增加了之后分配一段连续内存的失败率,针对这种情况可以把内存使用量较大的chunk放到PoolChunkList链表更后面,这样就便于内存的成功分配内存分配
PoolArena的内存分配是由allocate()完成的,它的大致流程如下
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
// 1.创建一个纯净的PooledByteBuf对象
PooledByteBuf<T> buf = newByteBuf(maxCapacity);
// 2.对PooledByteBuf进行内存分配
allocate(cache, buf, reqCapacity);
return buf;
}PooledByteBuf初始化
protected PooledByteBuf<byte[]> newByteBuf(int maxCapacity) {
return HAS_UNSAFE ? PooledUnsafeHeapByteBuf.newUnsafeInstance(maxCapacity) : PooledHeapByteBuf.newInstance(maxCapacity);
}
static PooledHeapByteBuf newInstance(int maxCapacity) {
// 从RECYCLER获取PooledHeapByteBuf实例
PooledHeapByteBuf buf = RECYCLER.get();
// 重新设置PooledHeapByteBuf属性
buf.reuse(maxCapacity);
return buf;
}到目前为止我们创建的PooledHeapByteBuf还只是一个空壳,我们还需要确定这个PooledHeapByteBuf在Chunk的底层存储所处在的位置。(关于RECYCLER后续的博客中会详细介绍)
PooledByteBuf内存分配
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
// 1.将需要分配的内存规格化
final int normCapacity = normalizeCapacity(reqCapacity);
// 2.判断需要申请的内存是否小于pageSize
if (isTinyOrSmall(normCapacity)) {
int tableIdx;
PoolSubpage<T>[] table;
// 3.判断内存是否属于tiny
boolean tiny = isTiny(normCapacity);
if (tiny) {
// 4.尝试从本地线程申请tiny 如果申请成功则直接返回
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
return;
}
// 5.根据需要申请的内存 计算出tinyIdx
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
// 6.尝试从本地线程申请small 如果申请成功则直接返回
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
return;
}
// 7.根据需要申请的内存 计算出smallIdx
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
final PoolSubpage<T> head = table[tableIdx];
// 8.走到这里说明尝试在poolThreadCache中分配失败
// 开始尝试借用tinySubpagePools或smallSubpagePools缓存中的Page来进行分配
synchronized (head) {
final PoolSubpage<T> s = head.next;
// 9.第一次在此位置申请内存的时候 s==head会调用allocateNormal方法来分配
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
incTinySmallAllocation(tiny);
return;
}
}
synchronized (this) {
// 10.使用全局allocateNormal进行分配内存
allocateNormal(buf, reqCapacity, normCapacity);
}
incTinySmallAllocation(tiny);
return;
}
// 11.判断需要申请的内存是否小于chunkSize
if (normCapacity <= chunkSize) {
12.尝试从本地线程allocateNormal方法进行内存分配
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
return;
}
synchronized (this) {
13.使用全局allocateNormal进行分配内存
allocateNormal(buf, reqCapacity, normCapacity);
++allocationsNormal;
}
} else {
// 14.如果申请内存大于chunkSize 直接创建非池化的Chunk来分配 并且该Chunk不会放在内存池中重用
allocateHuge(buf, reqCapacity);
}
}内存规格化
int normalizeCapacity(int reqCapacity) {
if (reqCapacity < 0) {
throw new IllegalArgumentException("capacity: " + reqCapacity + " (expected: 0+)");
}
// 请求的内存大小是否超过了chunkSize
if (reqCapacity >= chunkSize) {
// 如果已超出说明一个该内存已经超出了一个chunk能分配的范围 这种内存内存池无法分配应由JVM分配 直接返回原始大小
return directMemoryCacheAlignment == 0 ? reqCapacity : alignCapacity(reqCapacity);
}
// 请求大小大于等于512
if (!isTiny(reqCapacity)) {
// 返回一个512的2次幂倍数当做最终的内存大小
// 当原始大小是512时返回512 当原始大小在(512,1024]区间返回1024 当在(1024,2048]区间,返回2048等等
int normalizedCapacity = reqCapacity;
normalizedCapacity --;
normalizedCapacity |= normalizedCapacity >>> 1;
normalizedCapacity |= normalizedCapacity >>> 2;
normalizedCapacity |= normalizedCapacity >>> 4;
normalizedCapacity |= normalizedCapacity >>> 8;
normalizedCapacity |= normalizedCapacity >>> 16;
normalizedCapacity ++;
if (normalizedCapacity < 0) {
normalizedCapacity >>>= 1;
}
assert directMemoryCacheAlignment == 0 || (normalizedCapacity & directMemoryCacheAlignmentMask) == 0;
return normalizedCapacity;
}
if (directMemoryCacheAlignment > 0) {
return alignCapacity(reqCapacity);
}
// Tiny且已经是16的整数倍 直接返回
if ((reqCapacity & 15) == 0) {
return reqCapacity;
}
// 请求大小小于512返回一个16的整数倍 这些大小的内存块在内存池中叫tiny块
// 原始大小(0,16]区间返回16 (16,32]区间返回32 (32,48]区间返回48等等
return (reqCapacity & ~15) + 16;
}总结:内存池包含两层分配区:线程私有分配区和内存池公有分配区。当内存被分配给某个线程之后在释放内存时释放的内存不会直接返回给公有分配区,而是直接在线程私有分配区中缓存,当线程频繁的申请内存时会提高分配效率。同时当线程申请内存的动作不活跃时可能会造成内存浪费的情况,这时候内存池会对线程私有分配区中的情况进行监控,当发现线程的分配活动并不活跃时会把线程缓存的内存块释放返回给公有区。在整个内存分配时可能会出现分配的内存过大导致内存池无法分配的情况,这时候就需要JVM堆直接分配,所以严格的讲有三层分配区
分配内存时默认先尝试从PoolThreadCache中分配内存,PoolThreadCache利用ThreadLocal的特性消除了多线程竞争,提高内存分配效率。首次分配时PoolThreadCache中并没有可用内存进行分配,当上一次分配的内存使用完并释放时,会将其加入到PoolThreadCache中,提供该线程下次申请时使用。分配的内存大小小于512时内存池分配Tiny块,大小在[512,PageSize]区间时分配Small块,Tiny块和Small块基于Page分配,分配的大小在(PageSize,ChunkSize]区间时分配Normal块,Normal块基于Chunk分配,内存大小超过Chunk内存池无法分配这种大内存,直接由JVM堆分配并且内存池也不会缓存这种内存
关于内存线程私有分配和内存公有分配将在下一篇博客中进行详细介绍