2D-2D:对极几何
A.对极约束
@输入:参考帧和当前帧的2D点坐标对(一般8对),内参
@输出:运动恢复R t

参考帧和当前帧的二维像素点通过特征点法拿到了匹配关系,那么从各自光心出发的两条射线交点即3D点,P和两个光心构成了极平面,
\
为极点,
\
是极线(Epipolar line)。
对极几何必须要有正确的匹配关系,否则当前帧无法找到参考帧
对应的点在
,那样的话就要用极线搜索了。
对极几何求R t的步骤是:
1.根据匹配的像素点对和内参求出基础矩阵F或者本质矩阵E。E=t^ R,只和运动有关,所以是我们求的本质,平移和旋转各3自由度,单目尺度歧义性自由度-1,所以E有5个自由度,一般用八点法,8对点求;F还包括内参
.
2.根据E或者R恢复R t。这里一般用SVD分解恢复出4个解,然后取点在相机前方的那个解。
B.单应矩阵
@输入:参考帧和当前帧的2D点坐标对(一般4对),内参
@输出:运动恢复R t
Homography描述两个平面之间的映射关系,自由度为8。可以通过4对不共线的点得出。一般配合RANSAC。
退化(degenerate):特征点共面or纯旋转,基础矩阵的自由度下降(比如平移那块没了),就出现了退化。
ORB中H 和F都算,取好的。
没有特征匹配下的2D-2D:极线搜索

深度滤波器:用多次三角测量让深度估计收敛
直接法时候没有特征点匹配,所以需要用极限搜索,如DSO中ImmaturePoint::traceOn()。DSO论文中没有过多提及,深度滤波器部分可以看SVO比较详细。
@输入:*Frame_ref, *Frame_curr, R, t, 参考帧点像素位置和深度估计区间, 内参
@输出:当前帧对应点像素位置,点的深度和不确定度。
这时候的前提是已知Rt(可以是估计出来的,也可以是静止模型、匀速模型、随机模型之类的),思路是:
这时候只知道参考帧的点像素坐标和深度区间,也知道当前帧的极线,
深度区间投过来后限定了极线的搜索范围,于是在范围内用块匹配之类的方法评估NCC(Normalized Cross Correlation)找到相似度最高的点,如果只把这个点当作最终结果是不行的,很容易陷入局部极值。所以需要用滤波的方法多次搜索直到收敛。所以过程是:
1.假设像素的深度满足高斯分布,通过极限搜索确定当前帧像素点对应位置
2.根据几何关系三角化计算深度和几何不确定性(DSO还加上了光度不确定性)
3.根据深度和不确定性融合进上一次的估计中,DSO中是GN迭代,直到深度收敛。
三角测量Triangulation
@输入:参考帧和当前帧的2D点坐标对,恢复出的R t
@输出:空间点的位置(即参考帧和当前帧点对应的深度s1 s2)
在用2D-2D的方法恢复出Rt后,还需要用运动估计点的空间位置。
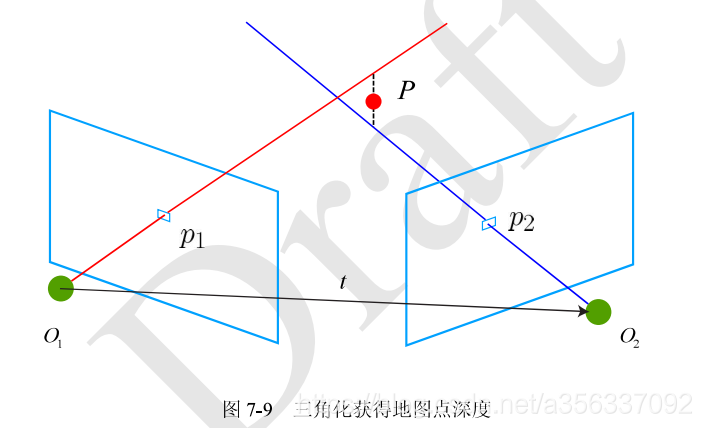
理论上两个射线会交于点P,但无论是匹配误差还是运动估计误差等噪声都会导致无法相交,所以一般用最小二乘的思路解点的位置。最后求得两帧系下的位置深度s1和s2。三角测量必须要有一定的平移。(CSDN里面 \^{}打不出反协号)
3D-2D:PnP
@输入:参考帧下的特征点像素坐标和3D坐标,匹配到当前帧的2D点像素坐标,内参
@输出:运动估计R t
Perspective-n-Point,当知道了n个空间点和其投影位置的情况下求解位姿。3D-2D比2D-2D简单的多,最少只需要3对点,不过他需要特征点的3D位置,可以由三角化or RGB-D or lidar提供,因此在双目和RGB-D中就很方便,单目中要先初始化后才能用PnP。需要注意的是:3D点的位置应该是在参考帧坐标系下的,实际上等价于在世界坐标系下已知(因为参考帧对世界系的T已知),而当前帧的空间坐标是不知道的,只知道参考帧特征点对应的2D像素坐标,否则就成了3D-3D ICP了。
PnP有很多方法,一般先用P3P/EPnP估计一个初值,然后用非线性优化的方法即BA refine:
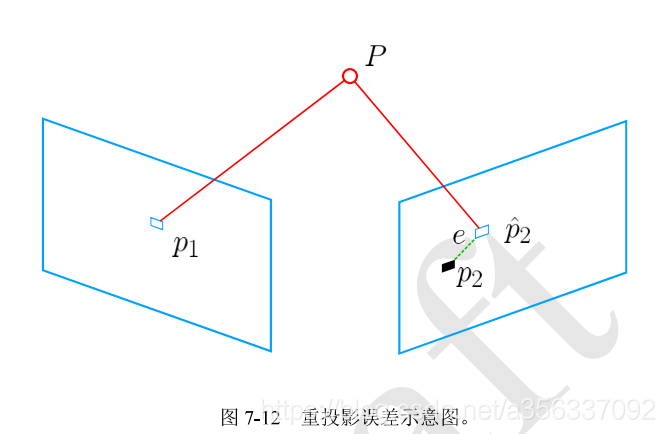
当前已知p1 p2坐标和P在左图下的3D点,这时候BA优化重投影误差,不断更新R t,让P在右图的投影p2^尽量接近p2,即可用G-N L-M等优化方法求出R t。(这里可以看看其中的雅可比推导),BA的目标函数:
即重投影误差,u是当前帧像素坐标即p2,Pi是参考帧下的3D点齐次坐标,这里的1/s实际上就是在K投影前将当前系下估计出的3D坐标归一化,所以变量只有李代数。
3D-3D ICP
@输入:配对好的一组3D点对,即那坨点云分别在参考帧下和当前帧下的坐标
@输出:运动恢复R t
这时候不用输入相机内参,3D-3D和相机模型无关,所以lidar也可以直接用,视觉和lidar的ICP区别是:视觉可以通过特征点去匹配2D点然后找到对应的3D点对,但是lidar有时比较难匹配特征点对,就认为距离最近的两个点是同一个点,即最近邻,当然这个点也是有一定的几何特征的特征点;当然lidar也可以用强度匹配之类的。
BA的目标函数:p p’为两对输入,变量为李代数