版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lusongno1/article/details/82864059
一个简单的pingpong程序测试mpi消息通讯的开销
随着科技的进步,集群单节点计算能力的提高,似乎通讯开销成了并行计算中dominant,再提高计算能力对于并行的增益似乎效果不明显,限制性能的瓶颈从处理器计算能力上转移到通讯开销上。显然,此时设法降低MPI消息通讯带来的时间消耗,成为了当务之急。
因此,写了一个极其简单的pingpong并行程序来测试消息通讯带来的开销。
基本思想
所谓的pingpong,顾名思义就是找一个数据包不断地在两个节点之间丢来丢去,想打乒乓球一样。
我们在程序中定义两重循环,外重循环定义数据量大小,从1kb到100m,涨幅为100kb,内层循环对于每一固定大小的数据跑100个来回,最后取平均值,作为这个大小的数据的传输时间。最后,以数据量大小为横轴,时间为纵轴,plot一下。
准备工作
我们连接了机房的两台电脑,作为实验环境。主要设置了SSH免密登录和NFS共享目录。
一个简单的代码如下:
/**
* pingpong程序,用于测试点点传送的速度
*/
//32位系统中,一个int占4B(sizeof(int)),1KB=250int,1M=250000int
//1M=1000kb,100M = 10e5kb
#include <stdio.h>
#include <stdlib.h>
#include <mpi.h>
//#define N 4 //外层循环数据量大小改变,使用动态数组来实现
#define m 100
#define debugflag 0
int main (int argc, char *argv[]) {
int myrank,i,nprocs;
double pingpongSize,aver_tcost,total_t,Ts[m];
double st, et, time_cost;
int N;
int *pingpong;
MPI_Init(&argc, &argv);//初始化MPI环境
MPI_Comm_size(MPI_COMM_WORLD, &nprocs);//获取总进程数
MPI_Comm_rank (MPI_COMM_WORLD, &myrank);//获取本地进程编号
MPI_Status status;
//int opposite_rank; opposite_rank = (myrank == 0) ? (1) : (0);
// for(N=1; N<=1e4; N=N+1e3) {
for(N=1; N<=1e5; N=N+1e2){
total_t = 0.0;
pingpong = (int*)malloc( N*1000);
if(!pingpong) {
printf("创建pingpong失败!\n");
exit(1);
}
// int pingpong[N] = {0};//随便赋值
for(i=0;i<N;i++)
{
pingpong[i] = 999;
// printf("%d,%d",i,pingpong[i]);
}
// pingpong[0] = 999;
if(myrank==0)
{
printf("开始 %dkb/1e5kb 数据传送……\n",N);
}
for(i=0; i<m; i++) {
st = MPI_Wtime();
if(myrank==0) {
MPI_Send (pingpong, N, MPI_INT, 1, i, MPI_COMM_WORLD);
#if debugflag
printf("第%d回合:%d发送数据完成……\n",i+1,myrank);
#endif
}
if(myrank==1) {
MPI_Recv (pingpong, N, MPI_INT, 0, i, MPI_COMM_WORLD, &status);
MPI_Send (pingpong, N, MPI_INT, 0, i, MPI_COMM_WORLD);
#if debugflag
printf("第%d回合:%d接收和发送数据完成……\n",i+1,myrank);
#endif
}
if(myrank==0) {
MPI_Recv (pingpong, N, MPI_INT, 1, i, MPI_COMM_WORLD, &status);
#if debugflag
printf("第%d回合:%d接收数据完成……\n",i+1,myrank);
printf("第%d回合succeed! The time of cost is %lf\n\n",i+1,time_cost);
// printf("一个int占用:%ld B",sizeof(myrank));
#endif
}
et = MPI_Wtime();
time_cost = et-st;
total_t = total_t+time_cost;
Ts[i] = time_cost;
}
aver_tcost = total_t/m;
pingpongSize = N/1e3;
// printf("%d个int的数据量大小为%lf M!\n",N,pingpongSize);
FILE *fp;
fp=fopen("data.txt","a+");
fprintf(fp,"%lf,%lf\n",pingpongSize,aver_tcost);
fclose(fp);
free(pingpong);
if(myrank == 0){
printf("%lfM 数据包发送接收回合完成……\n",pingpongSize);
printf("%dkb 的数据量的传送时间平均时间为: %lf \n\n",N,aver_tcost);
}
}
MPI_Finalize ();//结束MPI环境
return 0;
}
实验和结果
这个实验结果,其实心里有点虚,因为跑100M的数据,时间却不到0.01s,这个速度让我怀疑我哪里出问题了。一个可能是造数据造得不对,还有一个可能是消息传递的时候出问题了。
Anyway,先将结果画一下图,如下:
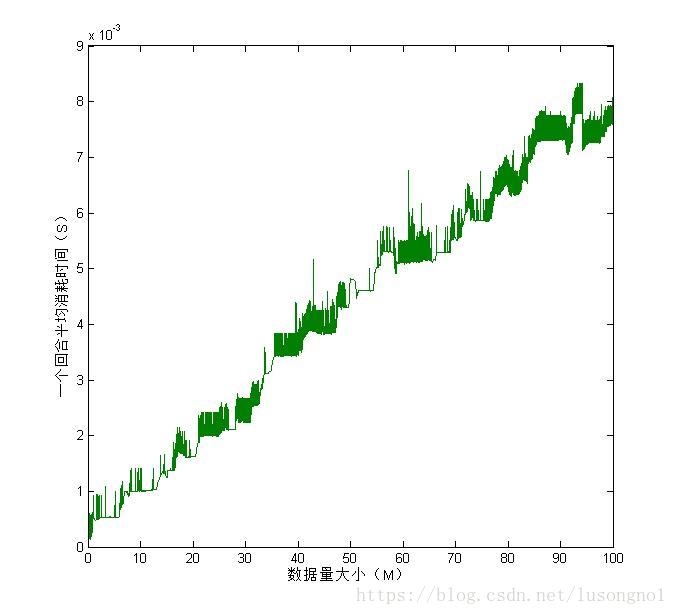
从结果上可以看到,通讯开销随着数据量大小呈现一个“局部震荡,整体近似线性增长”的关系,我们可以很容易地用线性函数去做线性fit,得到了T = 7.79e-5X+0.00041这个这样一个关系,可靠程度:误差平方和为0.0001721,均方根误差为0.000333,确定系数约为0.9787。这里的确定系数已经很接近1了,说明这个拟合是很可靠的。
分析一波这个拟合结果,我们大概能知道每增加100m的数据,大概需要增加7.8ms,快得令人难以置信,这也是我怀疑我的结果的原因。错归错,时间宝贵,总不能将青春都浪费在debug上面。