一 摘要
RNN运用到序列的学习中很有用,但是还是需要预处理数据,即例如处理语音数据,之前每一帧的输入需要对应一个label,本文直接利用RNN处理未预处理的数据,并在TIMIT语料库中进行实验,相对HMM和HMM-RNN取得明显的优势。
二 CTC详细介绍
1之前的方式
之前手写数字识别,语音识别,姿态识别都需要对数据进行预处理,即分割成letters或者word。
如今hidden Markov Models (HMMs; Rabiner, 1989), conditional random fields (CRFs; Lafferty et al., 2001)俩种模型运用到序列标签的处理中,但是有缺点,(1)需要语音或者其他方面专业知识(2)假设独立(3)…
2ctc的方式
优点:
- 不需要分割
基本方法:
- 给定一个输入,把网络的输出更改为所有可能标签序列的概率分布,如果有了这个分布,那么目标函数就可以定义为使正确标签的概率分布最大,并且目标函数可微,所以可以通过标准的后向传播来训练。
3 ctc与传统rnn的俩个比较大的区别
1 增加空格,减轻网络在某一帧预测不确定标签的压力。
2 训练的基准不是优化log(输入数据的最大可能概率),而是优化log(状态序列的概率)。
参考:Fast and Accurate Recurrent Neural Network Acoustic Models for Speech Recognition
4 tensorflow ctc 运行方式
特征向量经过LSTM得到的是每个标签的概率分布权重logits(未归一化),通过这个logits,我们可以计算ctc_loss和把这个logits解码成预测的标签以及置信度。具体参考运行流程图如下:
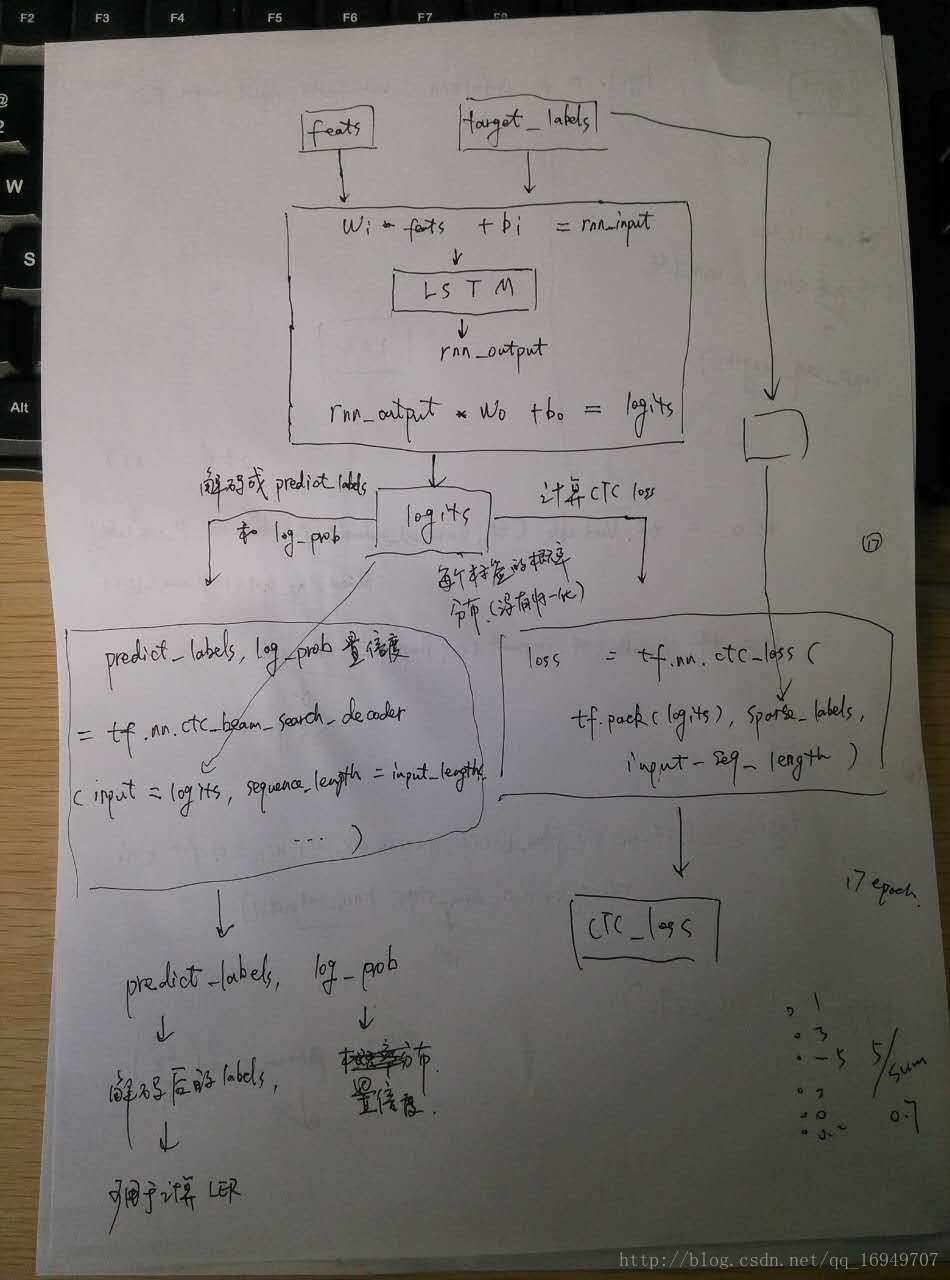
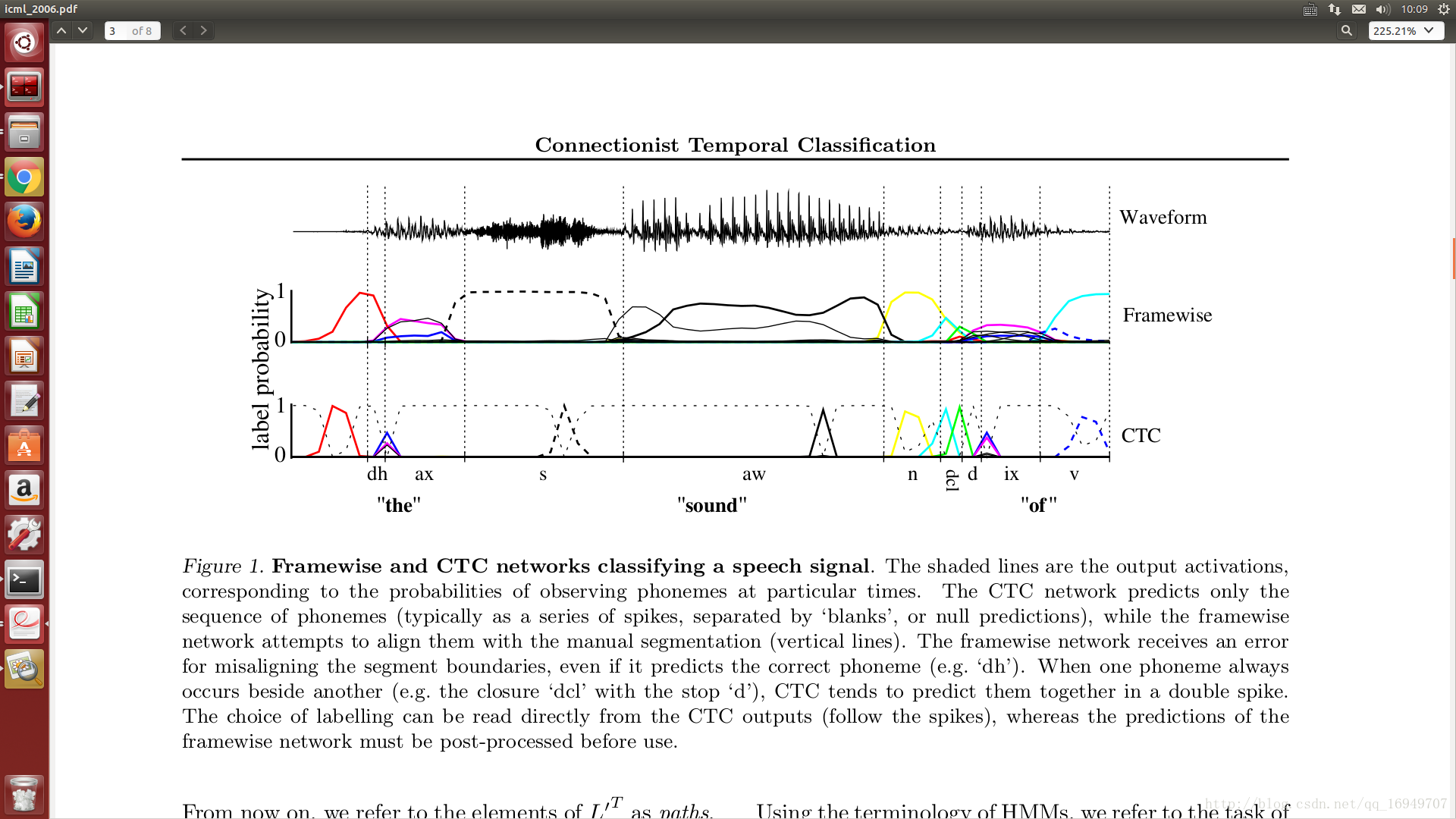
5 ctc 运行效果图
最下面为ctc的概率分布,每个时间段都有一个最大值,代表这个时间段这个标签的概率最高。文章讲了俩种解码方式,一种方式就是直接去最大值,即最优路径解码greedy decoder,但取到的不一定是概率最大的路径。
三 The CTC Forward-Backward Algorithm,ctc前向后向算法
1 这个算法的目的是啥?
有效的计算p(l|x),即计算输入为x输出标签为l的概率,因为路径有很多条,成指数增长,所以需要一个有效的计算方式。
2 HMM前向后向算法
漫谈 HMM:Forward-Backward Algorithm
3 CTC Forward-Backward Algorithm
(1) 前向推导
定义一个α t (s),表示到时间t,前面翻译成labels的前s个的概率。
然后α t (s)可以通过之前的迭代来计算,具体情况如下:
未完待续
(2) 后向推导
定义一个β t (s),表示从t到T,翻译成labels的s到l的概率,也可以迭代计算,具体情况如下:
未完待续
(3) 这样可以用α t (s),β t (s)来表示p(l|x)了
具体见原论文公式14 (由13可以推导过来)
四 CTC_loss计算
ctc训练流程和传统的神经网络类似,构建loss function,然后根据BP算法进行训练,不同之处在于传统的神经网络的训练准则是针对每帧数据,即每帧数据的训练误差最小,而CTC的训练准则是基于序列(比如语音识别的一整句话)的,比如最大化p(z|x),即使输入正确标签的概率达到最大,序列化的概率求解比较复杂,因为一个输出序列可以对应很多的路径,所有引入前后向算法来简化计算。
(1)通过前向后向算法来计算
(2)对
(3)bp训练
1 损失函数对
2 损失函数对