
NIPS-2016
目录
1 Motivation
Faster RCNN two stage :fully convolutional subnetwork + RoI-wise subnetwork apply a costly per-region subnetwork hundreds of times.
为了进一步提速,作者用 fully convolutional with almost all computation shared on the entire image. 减少头部的计算时间,
但是呢,如果简单的把 fully connected(Alex、VGG)层换成 fully convolutional (ResNet、GoogleNet)会导致 inferior detection accuracy that does not match the network’s superior classification accuracy,这是因为 image-level classification task favors translation invariance 但是 object detection task needs localization representations that are translation-variant to an extent,会有冲突。
ResNet的做法是 creates a deeper RoI-wise subnetwork ,虽然提高了精度,但是速度有所下降 due to the unshared per-RoI computation.
本文的目的就要想办法解决这种冲突
2 Innovation
在faster RCNN 的基础上 propose position-sensitive score maps to address a dilemma between translation-invariance in image classification and translation-variance in object detection.
3 Advantages
- region-based detector is fully convolutional with almost all computation shared on the entire image
- 2.5-20× faster than the Faster R-CNN counterpart
- 83.6% mAP on the PASCAL VOC 2007,82.0% the 2012
4 Methods
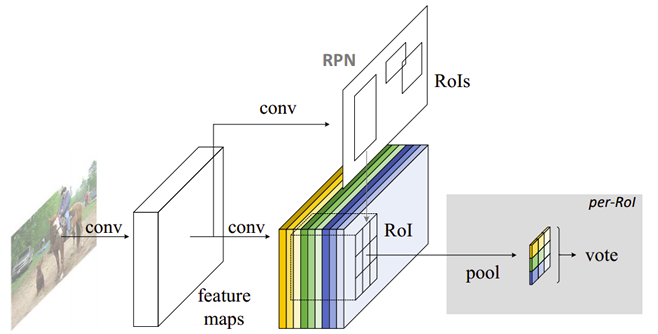
4.1 Structures
Backbone:ResNet101 = convolutional layers(100) + average pooling + 1000-class fc layer,作者只用100个convolutional layer来提取 feature map
Position-sensitive score maps & Position-sensitive RoI pooling
最后一层 convolutional layer 的 channel 设计为
,C是类别数量
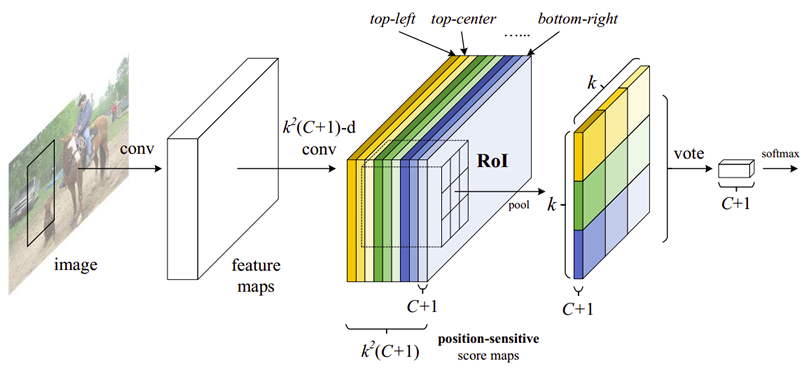
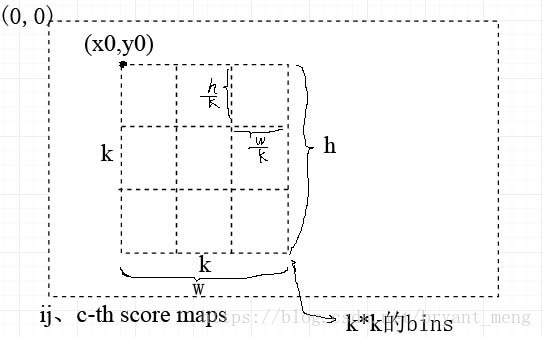
我们把score maps 上的 RoI 分成 k*k 个bins
ROI pooling 操作如下,
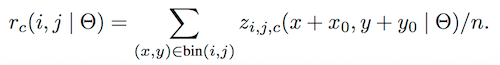
- is the pooled response in the bin for the category
- denotes all learnable parameters of the network
- is one of score map out of the score maps
- denotes the top-left corner of an RoI
- is the number of pixels in the bin
需要注意的是,pooling 后的第 i,j,c-th bin 是由 第 i,j,c-th score map对应的第 i.j bin 累加得到 ,也即是各类中每个 score maps 只 pooling 某一个bins,比如白色的 score maps 只对右下角部分的像素进行操作。
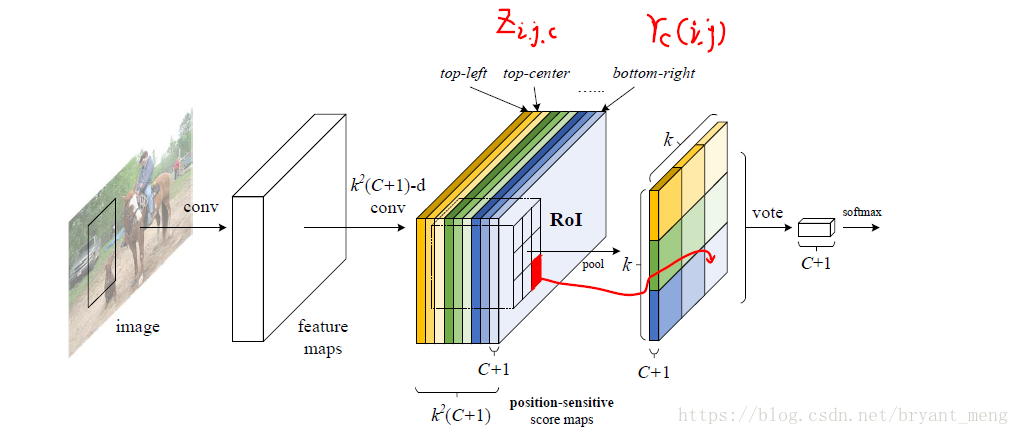
作者 address bbox regression in a similar way, feature map 通过 channel 的 conv 产生 channel 的 score maps,然后 producing a -d vector for each RoI,接着 vote 成 4-d vector,表示 ,这种情况是 class-agnostic,对于 class-specific 来说, 即可。
4.2 train
- End to End
- Loss function,和 Fast RCNN 一样 【Fast RCNN】《Fast-RCNN》
分类 Loss 和 回归 Loss 通过一个参数 λ (论文中为1)加权平均, 同样采用 L1 Smooth。 - Positive:IoU at least 0.5,Negative otherwise
- OHEM
- Single scales training:shorter side of image is 600 pixels
- 4-steps 训练,和 Faster RCNN 一样 【Faster RCNN】《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》,只不过是 RPN 和 R-FCN的交替训练
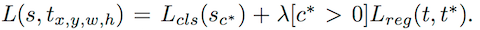
4.3 inference
- 300 RoI
- non-maximum suppression:0.3
4.4 À trous and stride
ResNet 101 中, stage 1-4 unchanged,stage 5 中,把第一个 stride = 2 的conv 变成1,然后用 À trous to compensate for the reduced stride
这样 ResNet stride from 32 to 16,提高了 score maps 的分辨率
提升效果如下,2.6 个 点

4.5 Visualization
如果每个bins 的响应都很高,vote 后的 score 会很高,反之,则 low

5 Experiments
5.1 Experiments on PASCAL VOC
5.1.1 验证结构的效果
- training :07+12
- test:07
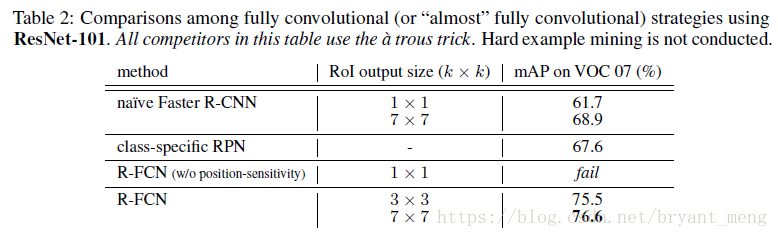
- Standard Faster RCNN:76.4% mAP,RoI pooling 插入 stage4 和 stage5之间(见文章最后的 Faster RCNN-RES101 结构图)
- naive Faster RCNN:RoI pooling after conv5,an inexpensive 21-class fc layer is evaluated on each RoI,为了对比的公平,用了 À trous trick
- class-specific RPN:RPN 的二分类(object or not)换成了 21 类,也用了À trous trick
- R-FCN(without position-sensitivity)k = 1,相当于 global pooling within each RoI
5.1.2 与Faster RCNN pk,速度和精度,k*k = 7*7
单技能释放PK
mining from a larger set of candidates has no benefit,所以作者采用 RoI = 300 (both training and inference)
组合拳PK
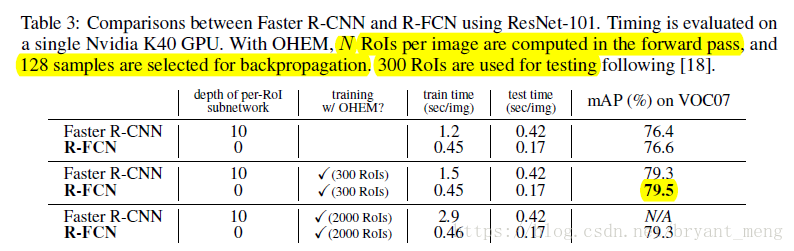
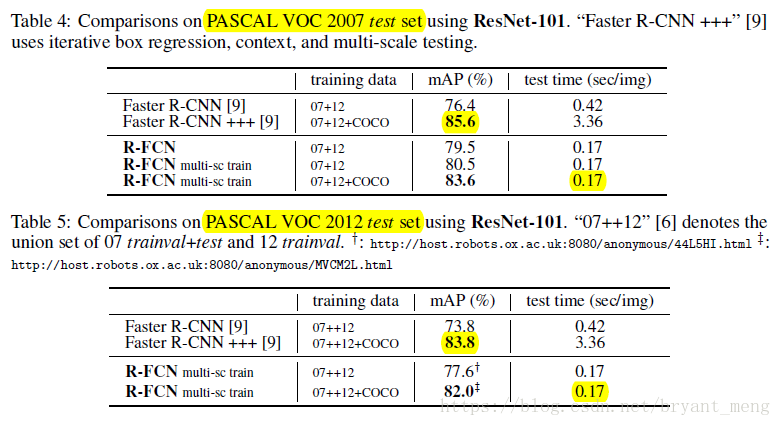
Faster R-CNN +++ 就是 ResNet 论文里面的 Box refinement + Global context + Multi-scale testing
5.1.3 Impact of Depth

5.1.4 Impact of Region Proposals

5.2 Experiments on MS COCO
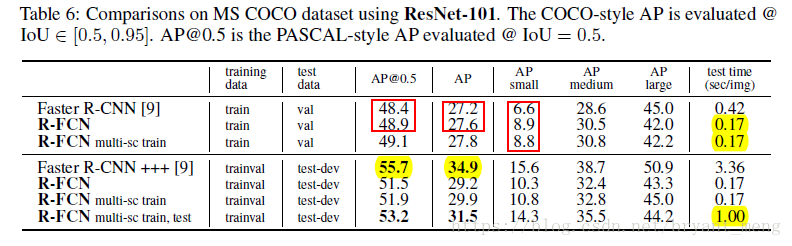
R-FCN vs Faster RCNN 不打组合拳是 R-FCN厉害,组合后 Faster RCNN 厉害,但是 R-FCN 会快很多
Faster RCNN-RES101 结构图

train.prototxt
# Enter your network definition here.
# Use Shift+Enter to update the visualization.
name: "ResNet-50"
layer {
name: 'input-data'
type: 'Python'
top: 'data'
top: 'im_info'
top: 'gt_boxes'
python_param {
module: 'roi_data_layer.layer'
layer: 'RoIDataLayer'
param_str: "'num_classes': 21"
}
}
# ------------------------ conv1 -----------------------------
layer {
bottom: "data"
top: "conv1"
name: "conv1"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 7
pad: 3
stride: 2
}
param {
lr_mult: 0.0
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "bn_conv1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "scale_conv1"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "conv1"
top: "conv1"
name: "conv1_relu"
type: "ReLU"
}
layer {
bottom: "conv1"
top: "pool1"
name: "pool1"
type: "Pooling"
pooling_param {
kernel_size: 3
stride: 2
pool: MAX
}
}
layer {
bottom: "pool1"
top: "res2a_branch1"
name: "res2a_branch1"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "res2a_branch1"
top: "res2a_branch1"
name: "bn2a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2a_branch1"
top: "res2a_branch1"
name: "scale2a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "pool1"
top: "res2a_branch2a"
name: "res2a_branch2a"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "bn2a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "scale2a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "res2a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2b"
name: "res2a_branch2b"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "bn2a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "scale2a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "res2a_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2c"
name: "res2a_branch2c"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "res2a_branch2c"
top: "res2a_branch2c"
name: "bn2a_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2a_branch2c"
top: "res2a_branch2c"
name: "scale2a_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2a_branch1"
bottom: "res2a_branch2c"
top: "res2a"
name: "res2a"
type: "Eltwise"
}
layer {
bottom: "res2a"
top: "res2a"
name: "res2a_relu"
type: "ReLU"
}
layer {
bottom: "res2a"
top: "res2b_branch2a"
name: "res2b_branch2a"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2a"
name: "bn2b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2a"
name: "scale2b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2a"
name: "res2b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res2b_branch2a"
top: "res2b_branch2b"
name: "res2b_branch2b"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "res2b_branch2b"
top: "res2b_branch2b"
name: "bn2b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2b_branch2b"
top: "res2b_branch2b"
name: "scale2b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2b_branch2b"
top: "res2b_branch2b"
name: "res2b_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res2b_branch2b"
top: "res2b_branch2c"
name: "res2b_branch2c"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "res2b_branch2c"
top: "res2b_branch2c"
name: "bn2b_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2b_branch2c"
top: "res2b_branch2c"
name: "scale2b_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2a"
bottom: "res2b_branch2c"
top: "res2b"
name: "res2b"
type: "Eltwise"
}
layer {
bottom: "res2b"
top: "res2b"
name: "res2b_relu"
type: "ReLU"
}
layer {
bottom: "res2b"
top: "res2c_branch2a"
name: "res2c_branch2a"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "res2c_branch2a"
top: "res2c_branch2a"
name: "bn2c_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2c_branch2a"
top: "res2c_branch2a"
name: "scale2c_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2c_branch2a"
top: "res2c_branch2a"
name: "res2c_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res2c_branch2a"
top: "res2c_branch2b"
name: "res2c_branch2b"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "res2c_branch2b"
top: "res2c_branch2b"
name: "bn2c_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2c_branch2b"
top: "res2c_branch2b"
name: "scale2c_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2c_branch2b"
top: "res2c_branch2b"
name: "res2c_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res2c_branch2b"
top: "res2c_branch2c"
name: "res2c_branch2c"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 0.0
}
}
layer {
bottom: "res2c_branch2c"
top: "res2c_branch2c"
name: "bn2c_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2c_branch2c"
top: "res2c_branch2c"
name: "scale2c_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2b"
bottom: "res2c_branch2c"
top: "res2c"
name: "res2c"
type: "Eltwise"
}
layer {
bottom: "res2c"
top: "res2c"
name: "res2c_relu"
type: "ReLU"
}
layer {
bottom: "res2c"
top: "res3a_branch1"
name: "res3a_branch1"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3a_branch1"
top: "res3a_branch1"
name: "bn3a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3a_branch1"
top: "res3a_branch1"
name: "scale3a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res2c"
top: "res3a_branch2a"
name: "res3a_branch2a"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2a"
name: "bn3a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2a"
name: "scale3a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2a"
name: "res3a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res3a_branch2a"
top: "res3a_branch2b"
name: "res3a_branch2b"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3a_branch2b"
top: "res3a_branch2b"
name: "bn3a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3a_branch2b"
top: "res3a_branch2b"
name: "scale3a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3a_branch2b"
top: "res3a_branch2b"
name: "res3a_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res3a_branch2b"
top: "res3a_branch2c"
name: "res3a_branch2c"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3a_branch2c"
top: "res3a_branch2c"
name: "bn3a_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3a_branch2c"
top: "res3a_branch2c"
name: "scale3a_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3a_branch1"
bottom: "res3a_branch2c"
top: "res3a"
name: "res3a"
type: "Eltwise"
}
layer {
bottom: "res3a"
top: "res3a"
name: "res3a_relu"
type: "ReLU"
}
layer {
bottom: "res3a"
top: "res3b_branch2a"
name: "res3b_branch2a"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2a"
name: "bn3b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2a"
name: "scale3b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2a"
name: "res3b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res3b_branch2a"
top: "res3b_branch2b"
name: "res3b_branch2b"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3b_branch2b"
top: "res3b_branch2b"
name: "bn3b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3b_branch2b"
top: "res3b_branch2b"
name: "scale3b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3b_branch2b"
top: "res3b_branch2b"
name: "res3b_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res3b_branch2b"
top: "res3b_branch2c"
name: "res3b_branch2c"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3b_branch2c"
top: "res3b_branch2c"
name: "bn3b_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3b_branch2c"
top: "res3b_branch2c"
name: "scale3b_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3a"
bottom: "res3b_branch2c"
top: "res3b"
name: "res3b"
type: "Eltwise"
}
layer {
bottom: "res3b"
top: "res3b"
name: "res3b_relu"
type: "ReLU"
}
layer {
bottom: "res3b"
top: "res3c_branch2a"
name: "res3c_branch2a"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3c_branch2a"
top: "res3c_branch2a"
name: "bn3c_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3c_branch2a"
top: "res3c_branch2a"
name: "scale3c_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3c_branch2a"
top: "res3c_branch2a"
name: "res3c_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res3c_branch2a"
top: "res3c_branch2b"
name: "res3c_branch2b"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3c_branch2b"
top: "res3c_branch2b"
name: "bn3c_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3c_branch2b"
top: "res3c_branch2b"
name: "scale3c_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3c_branch2b"
top: "res3c_branch2b"
name: "res3c_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res3c_branch2b"
top: "res3c_branch2c"
name: "res3c_branch2c"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3c_branch2c"
top: "res3c_branch2c"
name: "bn3c_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3c_branch2c"
top: "res3c_branch2c"
name: "scale3c_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3b"
bottom: "res3c_branch2c"
top: "res3c"
name: "res3c"
type: "Eltwise"
}
layer {
bottom: "res3c"
top: "res3c"
name: "res3c_relu"
type: "ReLU"
}
layer {
bottom: "res3c"
top: "res3d_branch2a"
name: "res3d_branch2a"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3d_branch2a"
top: "res3d_branch2a"
name: "bn3d_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3d_branch2a"
top: "res3d_branch2a"
name: "scale3d_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3d_branch2a"
top: "res3d_branch2a"
name: "res3d_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res3d_branch2a"
top: "res3d_branch2b"
name: "res3d_branch2b"
type: "Convolution"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3d_branch2b"
top: "res3d_branch2b"
name: "bn3d_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3d_branch2b"
top: "res3d_branch2b"
name: "scale3d_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3d_branch2b"
top: "res3d_branch2b"
name: "res3d_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res3d_branch2b"
top: "res3d_branch2c"
name: "res3d_branch2c"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res3d_branch2c"
top: "res3d_branch2c"
name: "bn3d_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3d_branch2c"
top: "res3d_branch2c"
name: "scale3d_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3c"
bottom: "res3d_branch2c"
top: "res3d"
name: "res3d"
type: "Eltwise"
}
layer {
bottom: "res3d"
top: "res3d"
name: "res3d_relu"
type: "ReLU"
}
layer {
bottom: "res3d"
top: "res4a_branch1"
name: "res4a_branch1"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4a_branch1"
top: "res4a_branch1"
name: "bn4a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4a_branch1"
top: "res4a_branch1"
name: "scale4a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res3d"
top: "res4a_branch2a"
name: "res4a_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 2
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2a"
name: "bn4a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2a"
name: "scale4a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2a"
name: "res4a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4a_branch2a"
top: "res4a_branch2b"
name: "res4a_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4a_branch2b"
top: "res4a_branch2b"
name: "bn4a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4a_branch2b"
top: "res4a_branch2b"
name: "scale4a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4a_branch2b"
top: "res4a_branch2b"
name: "res4a_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4a_branch2b"
top: "res4a_branch2c"
name: "res4a_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4a_branch2c"
top: "res4a_branch2c"
name: "bn4a_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4a_branch2c"
top: "res4a_branch2c"
name: "scale4a_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4a_branch1"
bottom: "res4a_branch2c"
top: "res4a"
name: "res4a"
type: "Eltwise"
}
layer {
bottom: "res4a"
top: "res4a"
name: "res4a_relu"
type: "ReLU"
}
layer {
bottom: "res4a"
top: "res4b_branch2a"
name: "res4b_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2a"
name: "bn4b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2a"
name: "scale4b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2a"
name: "res4b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4b_branch2a"
top: "res4b_branch2b"
name: "res4b_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4b_branch2b"
top: "res4b_branch2b"
name: "bn4b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4b_branch2b"
top: "res4b_branch2b"
name: "scale4b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4b_branch2b"
top: "res4b_branch2b"
name: "res4b_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4b_branch2b"
top: "res4b_branch2c"
name: "res4b_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4b_branch2c"
top: "res4b_branch2c"
name: "bn4b_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4b_branch2c"
top: "res4b_branch2c"
name: "scale4b_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4a"
bottom: "res4b_branch2c"
top: "res4b"
name: "res4b"
type: "Eltwise"
}
layer {
bottom: "res4b"
top: "res4b"
name: "res4b_relu"
type: "ReLU"
}
layer {
bottom: "res4b"
top: "res4c_branch2a"
name: "res4c_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4c_branch2a"
top: "res4c_branch2a"
name: "bn4c_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4c_branch2a"
top: "res4c_branch2a"
name: "scale4c_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4c_branch2a"
top: "res4c_branch2a"
name: "res4c_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4c_branch2a"
top: "res4c_branch2b"
name: "res4c_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4c_branch2b"
top: "res4c_branch2b"
name: "bn4c_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4c_branch2b"
top: "res4c_branch2b"
name: "scale4c_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4c_branch2b"
top: "res4c_branch2b"
name: "res4c_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4c_branch2b"
top: "res4c_branch2c"
name: "res4c_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4c_branch2c"
top: "res4c_branch2c"
name: "bn4c_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4c_branch2c"
top: "res4c_branch2c"
name: "scale4c_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4b"
bottom: "res4c_branch2c"
top: "res4c"
name: "res4c"
type: "Eltwise"
}
layer {
bottom: "res4c"
top: "res4c"
name: "res4c_relu"
type: "ReLU"
}
layer {
bottom: "res4c"
top: "res4d_branch2a"
name: "res4d_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4d_branch2a"
top: "res4d_branch2a"
name: "bn4d_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4d_branch2a"
top: "res4d_branch2a"
name: "scale4d_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4d_branch2a"
top: "res4d_branch2a"
name: "res4d_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4d_branch2a"
top: "res4d_branch2b"
name: "res4d_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4d_branch2b"
top: "res4d_branch2b"
name: "bn4d_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4d_branch2b"
top: "res4d_branch2b"
name: "scale4d_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4d_branch2b"
top: "res4d_branch2b"
name: "res4d_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4d_branch2b"
top: "res4d_branch2c"
name: "res4d_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4d_branch2c"
top: "res4d_branch2c"
name: "bn4d_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4d_branch2c"
top: "res4d_branch2c"
name: "scale4d_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4c"
bottom: "res4d_branch2c"
top: "res4d"
name: "res4d"
type: "Eltwise"
}
layer {
bottom: "res4d"
top: "res4d"
name: "res4d_relu"
type: "ReLU"
}
layer {
bottom: "res4d"
top: "res4e_branch2a"
name: "res4e_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4e_branch2a"
top: "res4e_branch2a"
name: "bn4e_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4e_branch2a"
top: "res4e_branch2a"
name: "scale4e_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4e_branch2a"
top: "res4e_branch2a"
name: "res4e_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4e_branch2a"
top: "res4e_branch2b"
name: "res4e_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4e_branch2b"
top: "res4e_branch2b"
name: "bn4e_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4e_branch2b"
top: "res4e_branch2b"
name: "scale4e_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4e_branch2b"
top: "res4e_branch2b"
name: "res4e_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4e_branch2b"
top: "res4e_branch2c"
name: "res4e_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4e_branch2c"
top: "res4e_branch2c"
name: "bn4e_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4e_branch2c"
top: "res4e_branch2c"
name: "scale4e_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4d"
bottom: "res4e_branch2c"
top: "res4e"
name: "res4e"
type: "Eltwise"
}
layer {
bottom: "res4e"
top: "res4e"
name: "res4e_relu"
type: "ReLU"
}
layer {
bottom: "res4e"
top: "res4f_branch2a"
name: "res4f_branch2a"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4f_branch2a"
top: "res4f_branch2a"
name: "bn4f_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4f_branch2a"
top: "res4f_branch2a"
name: "scale4f_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4f_branch2a"
top: "res4f_branch2a"
name: "res4f_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res4f_branch2a"
top: "res4f_branch2b"
name: "res4f_branch2b"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4f_branch2b"
top: "res4f_branch2b"
name: "bn4f_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4f_branch2b"
top: "res4f_branch2b"
name: "scale4f_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4f_branch2b"
top: "res4f_branch2b"
name: "res4f_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res4f_branch2b"
top: "res4f_branch2c"
name: "res4f_branch2c"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res4f_branch2c"
top: "res4f_branch2c"
name: "bn4f_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4f_branch2c"
top: "res4f_branch2c"
name: "scale4f_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4e"
bottom: "res4f_branch2c"
top: "res4f"
name: "res4f"
type: "Eltwise"
}
layer {
bottom: "res4f"
top: "res4f"
name: "res4f_relu"
type: "ReLU"
}
layer {
bottom: "res4f"
top: "res5a_branch1"
name: "res5a_branch1"
type: "Convolution"
convolution_param {
num_output: 2048
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res5a_branch1"
top: "res5a_branch1"
name: "bn5a_branch1"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5a_branch1"
top: "res5a_branch1"
name: "scale5a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res4f"
top: "res5a_branch2a"
name: "res5a_branch2a"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2a"
name: "bn5a_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2a"
name: "scale5a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2a"
name: "res5a_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res5a_branch2a"
top: "res5a_branch2b"
name: "res5a_branch2b"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
dilation: 2
pad: 2
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res5a_branch2b"
top: "res5a_branch2b"
name: "bn5a_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5a_branch2b"
top: "res5a_branch2b"
name: "scale5a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5a_branch2b"
top: "res5a_branch2b"
name: "res5a_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res5a_branch2b"
top: "res5a_branch2c"
name: "res5a_branch2c"
type: "Convolution"
convolution_param {
num_output: 2048
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res5a_branch2c"
top: "res5a_branch2c"
name: "bn5a_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5a_branch2c"
top: "res5a_branch2c"
name: "scale5a_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5a_branch1"
bottom: "res5a_branch2c"
top: "res5a"
name: "res5a"
type: "Eltwise"
}
layer {
bottom: "res5a"
top: "res5a"
name: "res5a_relu"
type: "ReLU"
}
layer {
bottom: "res5a"
top: "res5b_branch2a"
name: "res5b_branch2a"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2a"
name: "bn5b_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2a"
name: "scale5b_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2a"
name: "res5b_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res5b_branch2a"
top: "res5b_branch2b"
name: "res5b_branch2b"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
dilation: 2
pad: 2
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res5b_branch2b"
top: "res5b_branch2b"
name: "bn5b_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5b_branch2b"
top: "res5b_branch2b"
name: "scale5b_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5b_branch2b"
top: "res5b_branch2b"
name: "res5b_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res5b_branch2b"
top: "res5b_branch2c"
name: "res5b_branch2c"
type: "Convolution"
convolution_param {
num_output: 2048
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res5b_branch2c"
top: "res5b_branch2c"
name: "bn5b_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5b_branch2c"
top: "res5b_branch2c"
name: "scale5b_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5a"
bottom: "res5b_branch2c"
top: "res5b"
name: "res5b"
type: "Eltwise"
}
layer {
bottom: "res5b"
top: "res5b"
name: "res5b_relu"
type: "ReLU"
}
layer {
bottom: "res5b"
top: "res5c_branch2a"
name: "res5c_branch2a"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2a"
name: "bn5c_branch2a"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2a"
name: "scale5c_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2a"
name: "res5c_branch2a_relu"
type: "ReLU"
}
layer {
bottom: "res5c_branch2a"
top: "res5c_branch2b"
name: "res5c_branch2b"
type: "Convolution"
convolution_param {
num_output: 512
kernel_size: 3
dilation: 2
pad: 2
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2b"
name: "bn5c_branch2b"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2b"
name: "scale5c_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2b"
name: "res5c_branch2b_relu"
type: "ReLU"
}
layer {
bottom: "res5c_branch2b"
top: "res5c_branch2c"
name: "res5c_branch2c"
type: "Convolution"
convolution_param {
num_output: 2048
kernel_size: 1
pad: 0
stride: 1
bias_term: false
}
param {
lr_mult: 1.0
}
}
layer {
bottom: "res5c_branch2c"
top: "res5c_branch2c"
name: "bn5c_branch2c"
type: "BatchNorm"
batch_norm_param {
use_global_stats: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5c_branch2c"
top: "res5c_branch2c"
name: "scale5c_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
param {
lr_mult: 0.0
decay_mult: 0.0
}
}
layer {
bottom: "res5b"
bottom: "res5c_branch2c"
top: "res5c"
name: "res5c"
type: "Eltwise"
}
layer {
bottom: "res5c"
top: "res5c"
name: "res5c_relu"
type: "ReLU"
}
#========= RPN ============
layer {
name: "rpn_conv/3x3"
type: "Convolution"
bottom: "res4f"
top: "rpn/output"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 512
kernel_size: 3 pad: 1 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
layer {
name: "rpn_relu/3x3"
type: "ReLU"
bottom: "rpn/output"
top: "rpn/output"
}
layer {
name: "rpn_cls_score"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_cls_score"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 18 # 2(bg/fg) * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
layer {
name: "rpn_bbox_pred"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_bbox_pred"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 36 # 4 * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
layer {
bottom: "rpn_cls_score"
top: "rpn_cls_score_reshape"
name: "rpn_cls_score_reshape"
type: "Reshape"
reshape_param { shape { dim: 0 dim: 2 dim: -1 dim: 0 } }
}
layer {
name: 'rpn-data'
type: 'Python'
bottom: 'rpn_cls_score'
bottom: 'gt_boxes'
bottom: 'im_info'
bottom: 'data'
top: 'rpn_labels'
top: 'rpn_bbox_targets'
top: 'rpn_bbox_inside_weights'
top: 'rpn_bbox_outside_weights'
python_param {
module: 'rpn.anchor_target_layer'
layer: 'AnchorTargetLayer'
param_str: "'feat_stride': 16"
}
}
layer {
name: "rpn_loss_cls"
type: "SoftmaxWithLoss"
bottom: "rpn_cls_score_reshape"
bottom: "rpn_labels"
propagate_down: 1
propagate_down: 0
top: "rpn_cls_loss"
loss_weight: 1
loss_param {
ignore_label: -1
normalize: true
}
}
layer {
name: "rpn_loss_bbox"
type: "SmoothL1Loss"
bottom: "rpn_bbox_pred"
bottom: "rpn_bbox_targets"
bottom: 'rpn_bbox_inside_weights'
bottom: 'rpn_bbox_outside_weights'
top: "rpn_loss_bbox"
loss_weight: 1
smooth_l1_loss_param { sigma: 3.0 }
}
#========= RoI Proposal ============
layer {
name: "rpn_cls_prob"
type: "Softmax"
bottom: "rpn_cls_score_reshape"
top: "rpn_cls_prob"
}
layer {
name: 'rpn_cls_prob_reshape'
type: 'Reshape'
bottom: 'rpn_cls_prob'
top: 'rpn_cls_prob_reshape'
reshape_param { shape { dim: 0 dim: 18 dim: -1 dim: 0 } }
}
layer {
name: 'proposal'
type: 'Python'
bottom: 'rpn_cls_prob_reshape'
bottom: 'rpn_bbox_pred'
bottom: 'im_info'
top: 'rpn_rois'
# top: 'rpn_scores'
python_param {
module: 'rpn.proposal_layer'
layer: 'ProposalLayer'
param_str: "'feat_stride': 16"
}
}
#layer {
# name: 'debug-data'
# type: 'Python'
# bottom: 'data'
# bottom: 'rpn_rois'
# bottom: 'rpn_scores'
# python_param {
# module: 'rpn.debug_layer'
# layer: 'RPNDebugLayer'
# }
#}
layer {
name: 'roi-data'
type: 'Python'
bottom: 'rpn_rois'
bottom: 'gt_boxes'
top: 'rois'
top: 'labels'
top: 'bbox_targets'
top: 'bbox_inside_weights'
top: 'bbox_outside_weights'
python_param {
module: 'rpn.proposal_target_layer'
layer: 'ProposalTargetLayer'
param_str: "'num_classes': 2"
}
}
#----------------------new conv layer------------------
layer {
bottom: "res5c"
top: "conv_new_1"
name: "conv_new_1"
type: "Convolution"
convolution_param {
num_output: 1024
kernel_size: 1
pad: 0
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
param {
lr_mult: 1.0
}
param {
lr_mult: 2.0
}
}
layer {
bottom: "conv_new_1"
top: "conv_new_1"
name: "conv_new_1_relu"
type: "ReLU"
}
layer {
bottom: "conv_new_1"
top: "rfcn_cls"
name: "rfcn_cls"
type: "Convolution"
convolution_param {
num_output: 1029 #21*(7^2) cls_num*(score_maps_size^2)
kernel_size: 1
pad: 0
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
param {
lr_mult: 1.0
}
param {
lr_mult: 2.0
}
}
layer {
bottom: "conv_new_1"
top: "rfcn_bbox"
name: "rfcn_bbox"
type: "Convolution"
convolution_param {
num_output: 392 #2*4*(7^2) (bg/fg)*(dx, dy, dw, dh)*(score_maps_size^2)
kernel_size: 1
pad: 0
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
param {
lr_mult: 1.0
}
param {
lr_mult: 2.0
}
}
#--------------position sensitive RoI pooling--------------
layer {
bottom: "rfcn_cls"
bottom: "rois"
top: "psroipooled_cls_rois"
name: "psroipooled_cls_rois"
type: "PSROIPooling"
psroi_pooling_param {
spatial_scale: 0.0625
output_dim: 21
group_size: 7
}
}
layer {
bottom: "psroipooled_cls_rois"
top: "cls_score"
name: "ave_cls_score_rois"
type: "Pooling"
pooling_param {
pool: AVE
kernel_size: 7
stride: 7
}
}
layer {
bottom: "rfcn_bbox"
bottom: "rois"
top: "psroipooled_loc_rois"
name: "psroipooled_loc_rois"
type: "PSROIPooling"
psroi_pooling_param {
spatial_scale: 0.0625
output_dim: 8
group_size: 7
}
}
layer {
bottom: "psroipooled_loc_rois"
top: "bbox_pred"
name: "ave_bbox_pred_rois"
type: "Pooling"
pooling_param {
pool: AVE
kernel_size: 7
stride: 7
}
}
#-----------------------output------------------------
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "cls_score"
bottom: "labels"
top: "loss_cls"
loss_weight: 1
propagate_down: true
propagate_down: false
}
layer {
name: "accuarcy"
type: "Accuracy"
bottom: "cls_score"
bottom: "labels"
top: "accuarcy"
#include: { phase: TEST }
propagate_down: false
propagate_down: false
}
layer {
name: "loss_bbox"
type: "SmoothL1LossOHEM"
bottom: "bbox_pred"
bottom: "bbox_targets"
bottom: 'bbox_inside_weights'
top: "loss_bbox"
loss_weight: 1
loss_param {
normalization: PRE_FIXED
pre_fixed_normalizer: 128
}
propagate_down: true
propagate_down: false
propagate_down: false
}
layer {
name: "silence"
type: "Silence"
bottom: "bbox_outside_weights"
}