冒泡排序
- 排序原理
冒泡排序方法是最简单的排序方法。这种方法的基本思想是,将待排序的元素看作是竖着排列的“气泡”,较小的元素比较轻,从而要往上浮。在冒泡排序算法中我们要对这个“气泡”序列处理若干遍。所谓一遍处理,就是自底向上检查一遍这个序列,并时刻注意两个相邻的元素的顺序是否正确。如果发现两个相邻元素的顺序不对,即“轻”的元素在下面,就交换它们的位置。显然,处理一遍之后,“最轻”的元素就浮到了最高位置;处理二遍之后,“次轻”的元素就浮到了次高位置。在作第二遍处理时,由于最高位置上的元素已是“最轻”元素,所以不必检查。一般地,第i遍处理时,不必检查第i高位置以上的元素,因为经过前面i-1遍的处理,它们已正确地排好序。
- 复杂度的计算O(n^2)
对于n位的数列则有比较次数为 (n-1) + (n-2) + … + 1 = n * (n - 1) / 2,这就得到了最大的比较次数
而O(N^2)表示的是复杂度的数量级。举个例子来说,如果n = 10000,那么 n(n-1)/2 = (n^2 - n) / 2 = (100000000 - 10000) / 2,相对10^8来说,10000小的可以忽略不计了,所以总计算次数约为0.5 * N^2。用O(N^2)就表示了其数量级(忽略前面系数0.5)。
- 代码实现
/**
* 冒泡排序算法
*/
public static void bubble(int[] arr){
for(int i = arr.length-1;i>=0;i--){//比较次数根据数组长度
for(int j = 0;j<i;j++){
if(arr[j]>arr[j+1]){//判断前一个是否比后一个数大,是的话将位置掉换
change(j,j+1,arr);
}
}
}
}
/**
* 将两个变量值调换
* @param a
* @param b
*/
private static void change(int a, int b,int[] arr) {
int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}选择排序
- 排序思想
对比数组中前一个元素跟后一个元素的大小,如果后面的元素比前面的元素小则用一个变量k来记住他的位置,接着第二次比较,前面“后一个元素”现变成了“前一个元素”,继续跟他的“后一个元素”进行比较如果后面的元素比他要小则用变量k记住它在数组中的位置(下标),等到循环结束的时候,我们应该找到了最小的那个数的下标了,然后进行判断,如果这个元素的下标不是第一个元素的下标,就让第一个元素跟他交换一下值,这样就找到整个数组中最小的数了。然后找到数组中第二小的数,让他跟数组中第二个元素交换一下值,以此类推。
- 时间复杂度计算O(n^2)
总的比较次数N=(n-1)+(n-2)+…+1=n*(n-1)/2。交换次数O(n),最好情况是,已经有序,交换0次;最坏情况交换n-1次,逆序交换n/2次。交换次数比冒泡排序少多了,由于交换所需CPU时间比比较所需的CPU时间多,n值较小时,选择排序比冒泡排序快。
- 代码实现
/**
* 选择排序
*/
public static void select(int[] arr){
for(int i = 0; i<arr.length -1;i++){//比较n-1次,每次遍历得到最小数的索引
int minIndex = i; //默认第一个数的为最小值的索引
for(int j = i+1;j<arr.length;j++){ //每次从第i+1个数开始寻找最小数的索引
if(arr[j]<arr[minIndex]){
minIndex = j;
}
}
change(i,minIndex,arr);//将该次遍历得到的最小数与第i位数交换
}
}插入排序
- 排序原理
将初始序列中的第一个元素作为一个有序序列,然后将剩下的 n-1 个元素按关键字大小依次插入该有序序列,每插入一个元素后依然保持该序列有序,经过 n-1 趟排序后使初始序列有序。
- 时间复杂度计算 O(n^2)
如果目标是把n个元素的序列升序排列,那么采用插入排序存在最好情况和最坏情况。最好情况就是,序列已经是升序排列了,在这种情况下,需要进行的比较操作需(n-1)次即可。最坏情况就是,序列是降序排列,那么此时需要进行的比较共有n(n-1)/2次。插入排序的赋值操作是比较操作的次数加上 (n-1)次。平均来说插入排序算法的时间复杂度为O(n^2)。
- 代码实现
/**
*插入排序
*/
public static void insert(int[] arr){
for(int i=1;i<arr.length;i++){//定义外层循环,从第二个数开始进行比较
int temp = arr[i];//记录每次循环需要比较的数
int j = i-1;//设置要比较的短数组的长度(初始序列长度)
for(;j>=0;j--){
if(arr[j]>temp){//如果前面的数比temp大,则将该书后移到j+1的位置
arr[j+1] = arr[j];
}else{//如果前面的数比temp小,终止循环,将该数的下个位置的值改为temp
arr[j+1] = temp;
break;
}
}//循环结束后j==-1
if(j==-1){//当前面的数都比temp小时,将第一个数的值改为temp
arr[0] = temp;
}
}
}快速排序
- 排序原理
找一个值作为参考值,比参考值大的就放在右边,比参考值小的就放在左边。那么一趟完成后就将数组分成了两部分:参考值左边的都是小于参考值的数,参考值右边的都是大于参考值的数,然后分别递归求这两部分,最后得到的就是一个排好序的数组了。
- 时间复杂度计算O(n)
快速排序每次将待排序数组分为两个部分,在理想状况下,每一次都将待排序数组划分成等长两个部分,则需要logn次划分。
而在最坏情况下,即数组已经有序或大致有序的情况下,每次划分只能减少一个元素(中间位置元素),这样的结果就好比是冒泡排序,所以快速排序时间复杂度下界为O(nlogn),最坏情况为O(n^2)。
- 代码实现
public static void quicksort(int[] arr,int low, int high){
int l = low;
int h = high;
int key = arr[low];//每次比较将左侧的第一个数作为关键数
while(l<h){
while(l<h && arr[h]>=key) h--;//左右没有出现交叉,并且右边没有找到比关键数小的,则索引左移
if(l<h){
//从右边找到了将找到的比关键数小的值与左边索引对应的值交换,再从左侧开始找,左侧索引值右移移
int temp = arr[l];
arr[l] = arr[h];
arr[h] = temp;
l++;
}
while(l<h && arr[l]<=key) l++;//左右两边没有出现交叉,并且左边没由找到比关键数大的,则索引右移
if(l<h){
//将在左侧找到的比关键数大的值与右边索引对应的值交换,开始从右侧查找,右侧索引值左移
int temp = arr[h];
arr[h] = arr[l];
arr[l] = temp;
h--;
}
}//当l==h出现交叉时,跳出循环,也就是找到了中间点,接下来从中间点左右分开,再次分别查找
//此时左边的数均小于右边的数
if(l>low){//l>low代表没由找到比关键数大的数,那么就需要跟换关键数从新找
quicksort(arr,low,l-1);
}
if(h<high){
quicksort(arr,l+1,high);
}
}在这里再介绍下随机化快排:
随机化快排是建立在基本快排的算法上做出的改进,利用概率事件降低快排出现的最不利情况的可能性,也就是说:基本的快速排序选取第一个元素作为关键数。这样在数组已经有序的情况下,每次划分将得到最坏的结果。而随机快排是选取一个元素作为关键数。这种情况下虽然最坏情况仍然是O(n^2),但最坏情况不再依赖于输入数据,而是由于随机函数取值不佳。实际上,随机化快速排序得到理论最坏情况的可能性仅为1/(2^n)。所以随机化快速排序可以对于绝大多数输入数据达到O(nlogn)的期望时间复杂度。
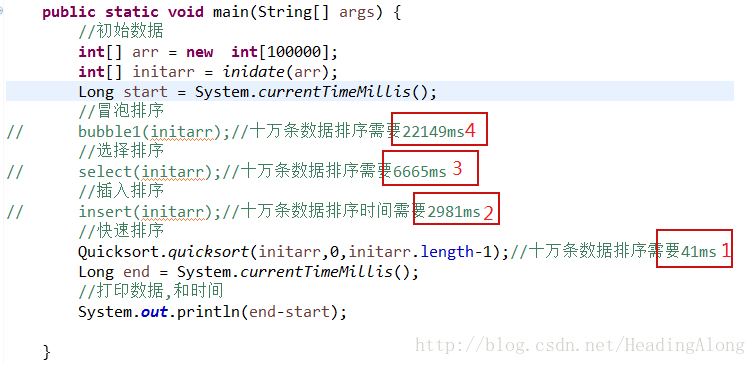
测试
这里使用十万条数据进行测试,分别用每一种算法进行(之所以使用十万条数据而不是百万条千万条,是受到个人电脑配置限制,而且快排时使用到递归后,数据量过大,造成栈内存溢出)