有没有这种感觉,学习编程的过程就像在挖一口井,而这口井你可以挖成“web”的形状,也可以挖成“app”的形状,还可以挖出“game”的形状。突然有一天,别人说:挖出“artificial intelligence”的形状后的井水才是最甜的。于是,你就开始想办法在已经挖好的井的基础上乱挖试图挖出最甜的井水,然而却挖了许多弯道。。。
机器学习的算法是建立在数学理论上的,如果数学学得不好,就算是学习已有的机器学习框架也是十分吃力。假如你曾经数学掌握得不错,但是在编程上难以 get 到该有的数学思维,那么,有很大的可能性是,你的 if-else 用久了,编程思维没有跟数学思维打通出一条路。
哈?编程思维没有跟数学思维打通一条路?我多年的数据结构 + 算法白学了?
这条虚无缥缈的“编程 <–> 数学”之路并不是说之前的知识白学了,而是机器学习相比于之前的知识更加地依赖于数学这门知识。打个比方,对于大量的“线性”与“非线性”的数据,处理前者需要用到线性代数的知识,后者大多结合了概率论与数理统计的知识,如今大多的监督学习和非监督学习算法大多基于线性代数和概率论与数理统计的数学理论。
什么线性,什么监督,说那么多,肯定是在转移话题,好好解释什么是打通编程跟数学的任督二脉!
额。。那我就先从标题展开吧!为什么你编程学得越久,越难入门人工智能?答案是:你的 if-else 用太多了!
以C++举个例子,“输入两个整数,比较两个数的大小,输入最大值”,传统的程序写法是:
#include <iostream>
using namespace std;
int max(int a, int b){
if(a > b){
cout<<a;
}
else{
cout<<b<<endl;
}
}
int main(){
int a, b;
cin>>a>>b;
max(a, b);
}
以上这段代码,每个初学者的必经之路,现在再回过来看这段代码,感觉要吐了,所以十分佩服教编程的老师,每一批学生,都要讲一遍。。。回到正题,请忽略掉上面那段要看得想吐吐的代码,请看下一段,同样是比较大小的程序,但是却骨骼惊奇:
#include <iostream>
using namespace std;
//返回一个数的绝对值
int abs(int num){
return num>0 ? num : -num;
}
//返回两个数中的最大值
int max(int a, int b){
return ( a + b + abs(a-b) ) / 2;
}
int main(){
int a, b;
cin>>a>>b;
cout<<max(a, b)<<endl;
return 0;
}
- 【注】
-
1、注意观察上面代码的 max 函数,并没有用到 if-else 就能实现比较大小,而是用
a+b+|a−b|2 公式计算出 a, b 的最大值。 -
2、同理,通过公式
a+b−|a−b|2 就能计算最小值。
哎哟,有点意思。但是,这个程序用公式反而更慢了好不好,本来 ALU 算一遍就可以,用了公式反而多算几倍,这不是多此一举吗?什么打通编程跟数学,你这标题是骗点击量的是吧。
写博文,谁不想多点人看。。。既然上面的例子没有 get 到点的话,再来一个看看吧。又是早就腻了的题目,写一个程序,1+2+3+···+100。老样子,先回顾一下闭着眼睛就能写的 for 循环传统算法:
#include <stdio.h>
int sum(int n){
int num=0;
for(int i=1; i<=n; i++){
num += i;
}
return num;
}
int main(){
printf("求和结果为%d\n\n", sum(100));
return 0;
}
再来看看公式法:
#include <stdio.h>
//返回1+2+..+n的计算结果
int sum(int n){
return n*(n+1)/2;
}
//输出1加到100
int main(){
printf("求和结果为%d\n\n", sum(100));
return 0;
}
【注】sum 函数中用的是求和公式:
嗯,我承认,用求和公式确实是比 for 循环运算速度快了。看了这两个程序,难道这篇博文想表达的是少用 for 循环,多背数学公式来代替 for 循环吗?
这个倒不是。本文想表达的是,从初学到熟练,程序员的代码逻辑会能力越来越强,但是,也会慢慢地忽视曾经也花了很多时间才掌握的数学知识也能在代码层派上用场。尤其在人工智能方面,数学是重中之重的基础。
其实我也知道数学很重要,但是现在很忙,数学的知识又多,又不知道从何入手,怎么学得过来。。。
如果不喜欢数学,学起来确实痛苦,但是进步的过程总会伴随着痛苦(突然鸡汤了)。在机器学习方面,最简单的,应该是线性回归算法,乃至 多元线性回归算法 了,我觉得这个算法是机器学习的基础中的基础,所需的知识是线性代数。
接下来,我简单讲一下不需要线性代数的知识也能理解的多元线性回归算法(非原理,仅简单应用)。
有一天,我漫步在学校教导处门口,偶然捡到了一张纸,难道是期末试卷?好像不是,有点失望,但我还是好奇地看了一下,这是一张表格,是对多个学生的德智体美的综合评分:
| 学生 | 德 | 智 | 体 | 美 | 总评 |
|---|---|---|---|---|---|
| 钾 | 9 | 7 | 5 | 10 | 80 |
| 钙 | 8 | 8 | 8 | 8 | 80 |
| 钠 | 7 | 10 | 4 | 5 | 65 |
| 镁 | 7 | 6 | 9 | 5 | 68 |
| 铝 | 8 | 7 | 8 | 6 | 74 |
[ 教C语言的老师告诉我,看到表格,第一时间就要想到二维数组 ]
于是我的脑海里,出现了这么一副画面:
//表格数据
float data[ROW][COL] = {
{
9, 7, 5, 10, 80
},{
8, 8, 8, 8, 80
},{
7, 10, 4, 5, 65
},{
7, 6, 9, 5, 68
},{
8, 7, 8, 6, 74
}
};这个表格的数据,称之为训练数据。
表格中的数据突然打断了我的思绪,“嘿呀,不对啊,钾同学的体育才5分,总评却有80分,怎么可能,不就是成绩好吗,切!”
我随手就把表格给扔了,然后越想越气,成绩好了不起吗!就在此刻,我回忆了起来,之前班主任有讲过总评是根据德智体美的评分算出来的,但是体育究竟占总评的比重有多大,跟智力(成绩)的比重相差多少,我实在想不起来了,这个计算总评的公式大概是:
其中
不知不觉,下意识地~~,定义了这个总评的计算函数:
//多元线性方程
float fun(float d, float z, float t, float m, float d_w, float z_w, float t_w, float m_w){
return d*d_w + z*z_w + t*t_w + m*m_w;
}这时候,我想到了多元线性回归,又称多变量线性回归。多元线性回归有一个很有用的公式:
有人看掉这条公式,立即放弃数学。那么这个公式到底什么意思?简单理解为为:
另外,这个公式不是计算一遍,而是对几乎所有的权重组合都计算一遍,然后取
是不是太复杂了?举个例子按步骤算你就明白了:
1、假设取一组权重值:1, 2, 1, 2,分别对应德, 智, 体, 美的权重值;
2、查表看第一行: 钾 | 9 | 7 | 5 | 10 | 80
计算对应权重值的总评猜测值:9×1+7×2+5×1+10×2 = 48 (这个结果是对应假设的权重值求出的猜测值,不是真实的,下一步用这个值与真实的总评值作差再平方);
3、用上一步求出的总评猜测值-在表格中真实的值,然后对结果平方,即(48-80)^2 = 1024 (咦,求出的值好亲切);
4、还没完呢,继续查看表格,看第二行,用同样的这组权重值计算:8×1+8×2+8×1+8×2 = 48,然后又得到1024;
5、接着,计算表格第三行,7×1+10×2+4×1+5×2 = 41,然后(41-65)^2 = 576;
6、接着继续下去,把对应同样的权重值求出总评猜测值 - 真实的总评值再把结果平方;
7、直到把所有行都算完后,把之前算好的所有猜测值与总评值的差的平方全部加起来,然后得到的结果再除以2倍的表格行数;
8、重新取新的权重组合,又把以上七步又计算一遍。把所有的权重组合对应结果计算一遍后,取结果值最小的对应的权重组合作为数据训练成果。
根据多元线性回归公式,写出的算法如下:
//数据训练完成后的德智体美的权重
float d_w = 0;
float z_w = 0;
float t_w = 0;
float m_w = 0;
//各权重的取值区间估计
float w_min = 0;
float w_max = 4;
//多元线性回归估计权重算法
void train( float data[ROW][COL] ){
//回归函数的最小值
float Linear_value_min = -1;
//每次计算回归函数的结果值
float Linear_value = 0;
//德智体美值
float d = 0;
float z = 0;
float t = 0;
float m = 0;
//计算权重的精度(精度越小,计算时间越久)
float w_precise = 0.5;
//遍历
for(float d_g = w_min; d_g <= w_max; d_g += w_precise){
for(float z_g = w_min; z_g <= w_max; z_g += w_precise){
for(float t_g = w_min; t_g <= w_max; t_g += w_precise){
for(float m_g = w_min; m_g <= w_max; m_g += w_precise){
//核心算法
for(int i=0; i<ROW; i++){
for(int j=0; j<COL-1; j++){
//赋值德智体美
switch(j){
case 0 : d = data[i][j];
break;
case 1 : z = data[i][j];
break;
case 2 : t = data[i][j];
break;
case 3 : m = data[i][j];
break;
}
}
/* 以上准备好了参数,以下开始计算回归函数 */
float truth_score = data[i][COL-1]; //真实总评
float guess_score = fun( d,z,t,m, d_g, z_g, t_g, m_g); //猜测总评
//求和
Linear_value += (guess_score - truth_score)*(guess_score - truth_score);
/* 查看已遍历情况 */
cout<<"正在训练: "<<d_g<<" "<<z_g<<" "<<t_g<<" "<<m_g<<" "
<<truth_score<<" "<<guess_score<<" "<<truth_score<<" "
<<Linear_value<<" "<<Linear_value_min<<endl;
}
//求出回归函数结果
Linear_value = Linear_value/2*ROW;
//如果求出的结果是最小值
if( Linear_value_min == -1 || Linear_value < Linear_value_min ){
//替换原本最小值
Linear_value_min = Linear_value;
//保存求得的权重
d_w = d_g;
z_w = z_g;
t_w = t_g;
m_w = m_g;
}
if( Linear_value_min == 0){ //找到最小,直接返回
return;
}
//重置
Linear_value = 0;
}
//system("cls");
}
}
}
} 注意1】看到这段代码发现问题没有,for 循环太多了。由于我的线性代数还在学习中,暂时做不到用矩阵的计算来简化代码。有兴趣的童鞋可以围观 《线性回归之向量化 linear regression – vectorization》
注意2】计算权重的思想是机器学习算法的基础,还对机器学习懵懵懂懂的可以看这篇文章《机器学习到底学到了什么》
注意3】本文中的数学markdown格式查询于《markdown语法之如何使用LaTeX语法编写数学公式》
注意4】本文的表格举例借鉴于《机器学习有意思! 01》- 世界上最简单的机器学习入门》
多元线性回归完整代码如下:
#include <iostream>
#define ROW 5
#define COL 5
using namespace std;
//得到数据,德智体美评分 + 总评
float data[ROW][COL] = {
{
9, 7, 5, 10, 80
},{
8, 8, 8, 8, 80
},{
7, 10, 4, 5, 65
},{
7, 6, 9, 5, 68
},{
8, 7, 8, 6, 74
}
};
//数据训练完成后的德智体美的权重
float d_w = 0;
float z_w = 0;
float t_w = 0;
float m_w = 0;
//各权重的取值区间估计
float w_min = 0;
float w_max = 4;
//多元线性方程
float fun(float d, float z, float t, float m, float d_w, float z_w, float t_w, float m_w){
return d*d_w + z*z_w + t*t_w + m*m_w;
}
//多元线性回归估计权重算法
void train( float data[ROW][COL] ){
//回归函数的最小值
float Linear_value_min = -1;
//每次计算回归函数的结果值
float Linear_value = 0;
//德智体美值
float d = 0;
float z = 0;
float t = 0;
float m = 0;
//计算权重的精度(精度越小,计算时间越久)
float w_precise = 0.5;
//遍历
for(float d_g = w_min; d_g <= w_max; d_g += w_precise){
for(float z_g = w_min; z_g <= w_max; z_g += w_precise){
for(float t_g = w_min; t_g <= w_max; t_g += w_precise){
for(float m_g = w_min; m_g <= w_max; m_g += w_precise){
//核心算法
for(int i=0; i<ROW; i++){
for(int j=0; j<COL-1; j++){
//赋值德智体美
switch(j){
case 0 : d = data[i][j];
break;
case 1 : z = data[i][j];
break;
case 2 : t = data[i][j];
break;
case 3 : m = data[i][j];
break;
}
}
/* 以上准备好了参数,以下开始计算回归函数 */
float truth_score = data[i][COL-1]; //真实总评
float guess_score = fun( d,z,t,m, d_g, z_g, t_g, m_g); //猜测总评
//求和
Linear_value += (guess_score - truth_score)*(guess_score - truth_score);
/* 查看已遍历情况 */
cout<<"正在训练: "<<d_g<<" "<<z_g<<" "<<t_g<<" "<<m_g<<" "
<<truth_score<<" "<<guess_score<<" "<<truth_score<<" "
<<Linear_value<<" "<<Linear_value_min<<endl;
}
//求出回归函数结果
Linear_value = Linear_value/2*ROW;
//如果求出的结果是最小值
if( Linear_value_min == -1 || Linear_value < Linear_value_min ){
//替换原本最小值
Linear_value_min = Linear_value;
//保存求得的权重
d_w = d_g;
z_w = z_g;
t_w = t_g;
m_w = m_g;
}
if( Linear_value_min == 0){ //找到最小,直接返回
return;
}
//重置
Linear_value = 0;
}
//system("cls");
}
}
}
}
//开始训练
int main(){
//训练数据
train(data);
//训练结束
cout<<endl;
cout<<"训练结束!"<<endl<<endl;
cout<<"德的权重为:"<<d_w<<endl;
cout<<"智的权重为:"<<z_w<<endl;
cout<<"体的权重为:"<<t_w<<endl;
cout<<"美的权重为:"<<m_w<<endl;
}
运行结果如下:
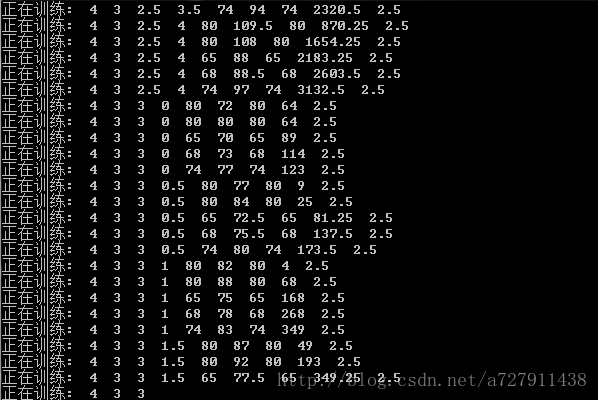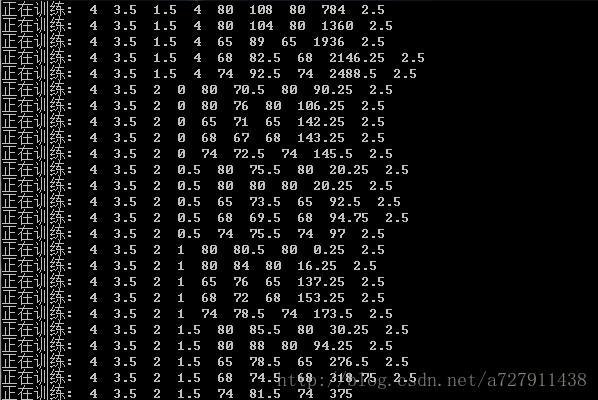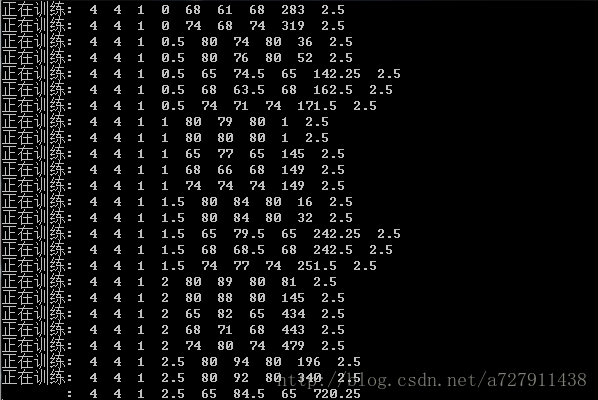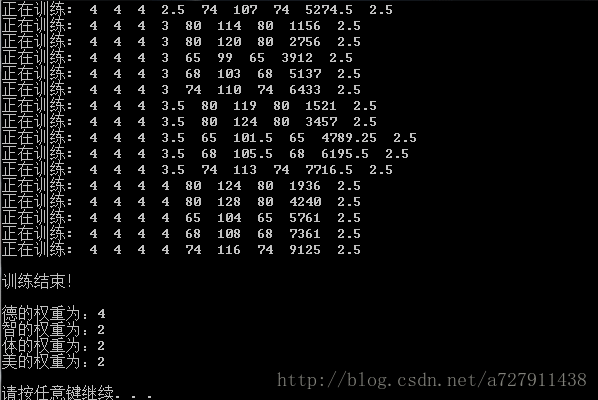
运算程序后,算出的权重组为:4, 2, 2, 2。带入表格随便一行比如第二行计算得:8×4+8×2+8×2+8×2 = 80,验证成功!(细心的童鞋会发现,前面我猜测智力的权重比较大,计算结果显示智力跟体育的权重一样大,证明我对学习好的人过于偏见了)
总结
如果想要更好地学习和掌握机器学习算法,数学是少不了的,Python 也是要学的(不然用C写特别痛苦)。在有了不错的数学功底和熟练使用蟒蛇语言后,选择一款机器学习框架就可以轻松上手和灵活使用。
如果数学基础扎实,语言也熟练运用还是对学习机器学习算法感到吃力的话,不妨转化一下思维,将数学思维与编程思维结合起来(学习MATLAB或许有好处)。因为编程思维讲究确定性、步骤性;而数学思维有关系性、抽象性。两者结合,即人工智能。
(以上仅为博主自己的感想与理解,有误之处,请多多指出,谢谢阅读)