InFluxDB的优点之一是能够将原始事件存储为不规则的时间序列,这些事件可能以不同的间隔出现。然而,不规则的时间序列带来了一些独特的挑战,在某些情况下,对数据的共同操作根本行不通。幸运的是,InFluxDB允许您通过计算任意时间窗口的单个值的总和,动态地将不规则的时间序列转换为规则的时间序列。这使您在从系统中捕获事件和处理这些数据时,这两个世界都是最好的。
我们可以查看一些实际的数据点,以便更好地理解在处理不规则时间序列时需要考虑的事项。例如,我们将使用五个数据点,并给出它们的值10、20、30、40和50。
但是,如果数据是以不定期的间隔收集的,那么计算值的平均值将不会给出预期的结果。
将这些数据点添加到InFluxDB中并对其进行处理将使我们更好地了解正在发生的事情。使用流入的CLI,我将这五个值插入到一个名为m1:
> select * from m1 where time > '2018-08-14T17:22:14Z' and time < '2018-08-14T17:23:20Z'name: m1time value---- -----2018-08-14T17:22:14.159637Z 102018-08-14T17:22:16.3561521Z 202018-08-14T17:22:18.2251241Z 302018-08-14T17:22:20.18086Z 402018-08-14T17:23:19.8976057Z 50由于我手动插入了数据,所以这些值的时间戳的间隔并不均匀,这正是我们在本例中所需要的。前四次发生在同一分钟内,第五次发生在将近一分钟之后。我们可以计算这五个值的平均值:
> select mean(*) From m1name: m1time mean_value---- ----------1970-01-01T00:00:00Z 30我们得到的结果是30,结果中的时间戳值是计算平均值的时间窗口的开始。
如果这是一个有规律的时间序列,那么从直觉上看,平均值为30将是有意义的。因为我们的例子是一个不规则的时间序列,但是,在计算最终结果时,测量之间的时间量很重要。当可视化这些值时,这一点变得更清楚了;下面是图中这些点的样子:
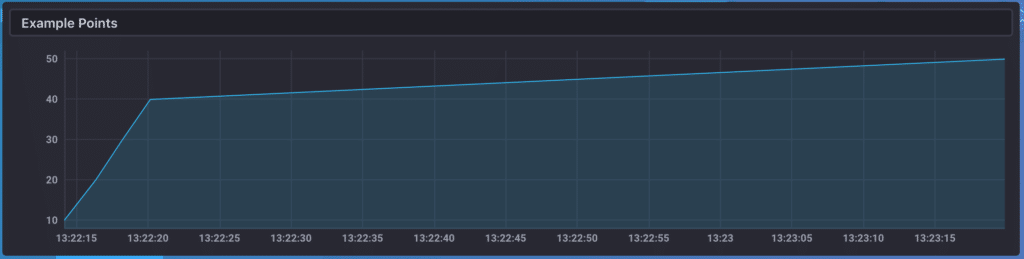
我们可以看到,大部分时间花在40和50之间(我们在这些点之间做线性插值来绘制一个图)。因此,我们可以合理地猜测,随着时间的推移,平均值可能接近40,而不是30。
显然,直接计算不规则序列中所有值的平均值是行不通的,因为该操作忽略了值在时间上的分布。我们需要对我们的数据施加某种规律。
为此,我们可以使用InfluxQL将数据的时间范围划分为离散单元GROUP BY
如果我们采取足够小的窗口,并使用mean()函数计算聚合,我们应该得到一个相当准确的时间序列表示。这就是我们的数据,在我们将这些点分组成10秒的间隔并计算出每个组的平均值之后,我们的数据是什么样子的:
> select mean(*) from m1 where time > '2018-08-14T17:22:14Z' and time < '2018-08-14T17:23:20Z' group by time(10s)name: m1time mean_value---- ----------2018-08-14T17:22:10Z 202018-08-14T17:22:20Z 402018-08-14T17:22:30Z 2018-08-14T17:22:40Z 2018-08-14T17:22:50Z 2018-08-14T17:23:00Z 2018-08-14T17:23:10Z 50对于2018-08-14T17:22:10z的10秒周期,我们有三个值,10,20和30,它们的平均值是20。对于下一个窗口,我们只有一个值,然后在看到最终值50之前,我们有一些没有值的窗口。和以前一样,我们必须对如何处理这些空窗口作出判断。
fill()任选GROUP BY将允许我们填写任何这些空窗口的数据。fill()null, previous, number, none,或linear。在我们的情况下,linear是正确的选择,因为我们用线性插值来绘制值,但是如果这是真实的数据,其他一些选项可能更合适。
这就是我们使用的数据fill(linear):
> select mean(*) from m1 where time > '2018-08-14T17:22:14Z' and time < '2018-08-14T17:23:20Z' group by time(10s) fill(linear)name: m1time mean_value---- ----------2018-08-14T17:22:10Z 202018-08-14T17:22:20Z 402018-08-14T17:22:30Z 422018-08-14T17:22:40Z 442018-08-14T17:22:50Z 462018-08-14T17:23:00Z 482018-08-14T17:23:10Z 50然后,我们可以使用以下方法计算新的、有规律的时间序列的平均值。子查询:
> select mean(*) from (select mean(*) from m1 where time > '2018-08-14T17:22:14Z' and time < '2018-08-14T17:23:20Z' group by time(10s) fill(linear))name: m1time mean_mean_value---- ---------------1970-01-01T00:00:00Z 41.42857142857143不过,还有一个警告:我们选择的窗口将对我们的最终结果产生影响。如果我们使用的是1s窗口而不是10s窗口呢?
> select mean(*) from (select mean(*) from m1 where time > '2018-08-14T17:22:14Z' and time < '2018-08-14T17:23:20Z' group by time(1s) fill(linear))name: m1time mean_mean_value---- ---------------1970-01-01T00:00:00Z 42.95454545454546如果数据是在状态发生变化时收集的,那么也许我们有一些LED,并且我们用十个块打开它们,那么我们在查询中执行的线性填充不再有意义;相反,使用fill(previous)根据我们的数据打算建模的系统的行为会更合适。
最终,这是处理不规则时间序列的最大挑战:您需要对数据有足够的了解,以便就如何处理这些数据做出明智的决定。