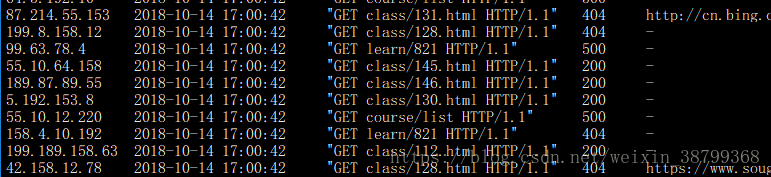
vi generate.py
代码
#coding=UTF-8
import random
import time
# url
url_paths = [
"class/112.html",
"class/128.html",
"class/145.html",
"class/146.html",
"class/131.html",
"class/130.html",
"learn/821",
"course/list"
]
# 搜索引擎
http_referers = [
"http://www.baidu.com/s?wd={query}",
"https://www.sougou.com/web?query={query}",
"http://cn.bing.com/search?q={query}",
"https://search.yahoo.com/search?q={query}"
]
# 搜索的课程名字
search_keyword = [
"Spark SQL实战",
"Hadoop基础",
"Storm实战",
"Spark Streaming实战",
"大数据面试"
]
#IP
ip_silces = [132,158,192,10,20,55,89,165,153,189,5,42,87,8,99,199,64,12,214,220,55,4,78,63]
# 状态码
status_codes = ["200","404","500"]
def sample_url():
return random.sample(url_paths,1)[0]
def sample_ip():
slice = random.sample(ip_silces,4)
return ".".join([str(item) for item in slice])
def sample_referer():
if random.uniform(0,1) > 0.2:
return "-"
refer_str = random.sample(http_referers,1)
query_str = random.sample(search_keyword,1)
return refer_str[0].format(query = query_str[0])
def sample_status_code():
return random.sample(status_codes,1)[0]
def generate_log(count = 100):
time_str = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime())
f = open("/root/zoujc/logs.txt","w+")
while count >= 1:
query_log = "{ip}\t{local_time}\t\"GET {url} HTTP/1.1\"\t{statu_code}\t{referer}".format(local_time = time_str,url = sample_url(),ip = sample_ip(),referer = sample_referer(),statu_code = sample_status_code())
print(query_log)
f.write(query_log + "\n")
count = count - 1
if __name__ == '__main__':
generate_log()
执行代码
python generate.py
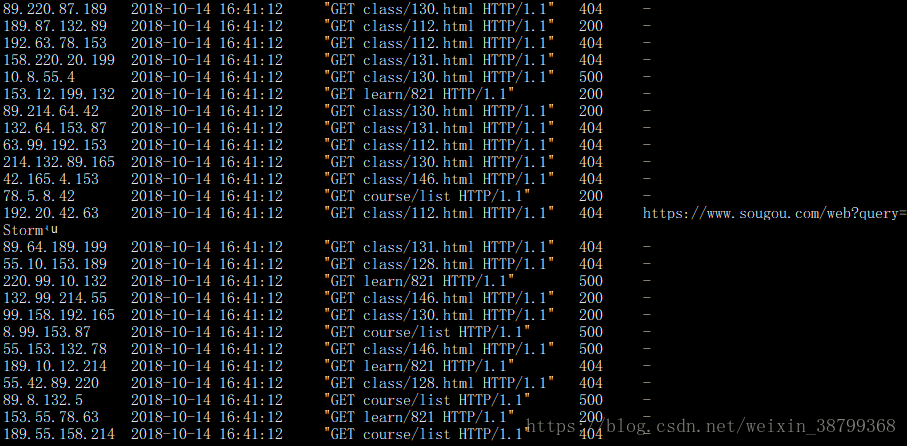
用crontab把python程序做成定时运行(每分钟)
touch log_generator.sh
chmod u+x log_generator.sh
vi log_generator.sh 我是在当前目录下
配置到crontab中
crontab -e */1 * * * * /root/zoujc/log_generator.sh >> /root/zoujc/flume/crontabLog_generator
查看是否每分钟一次执行了生成日志的python代码
cd /zoujc/flume
tail -f generateLog.log