学习:https://morvanzhou.github.io/tutorials/machine-learning/torch/
笔记
=============================== (1.1)简单引入 ====================================
1.torch numpy 相互转化
torch_data = torch.from_numpy(np_data)
tensor2array = torch_data.numpy()2.torch数学计算
torch.sin(), torch.mean()...
#tensor乘法
torch.mm(a,b)
3.把数据转化为32位浮点数
torch.FloatTensor(data) ================================== (1.2)Variable ================================================
莫烦很好地将Tensor比作鸡蛋,Variable比作鸡蛋篮子
import torch
from torch.autograd import Variable # torch 中 Variable 模块
# 先生鸡蛋
tensor = torch.FloatTensor([[1,2],[3,4]])
# 把鸡蛋放到篮子里, requires_grad是参不参与误差反向传播, 要不要计算梯度
variable = Variable(tensor, requires_grad=True)Variable 计算时, 它在背景幕布后面一步步默默地搭建着一个庞大的系统, 叫做计算图, computational graph. 这个图是用来干嘛的? 原来是将所有的计算步骤 (节点) 都连接起来, 最后进行误差反向传递的时候, 一次性将所有 variable 里面的修改幅度 (梯度) 都计算出来, 而 tensor 就没有这个能力啦.
v_out = torch.mean(variable*variable) # x^2v_out.backward() # 模拟 v_out 的误差反向传递
# 下面两步看不懂没关系, 只要知道 Variable 是计算图的一部分, 可以用来传递误差就好.
# v_out = 1/4 * sum(variable*variable) 这是计算图中的 v_out 计算步骤
# 针对于 v_out 的梯度就是, d(v_out)/d(variable) = 1/4*2*variable = variable/2#如果想输出variable里的tensor: variable.data
============================= (1.3)activation function =======================================
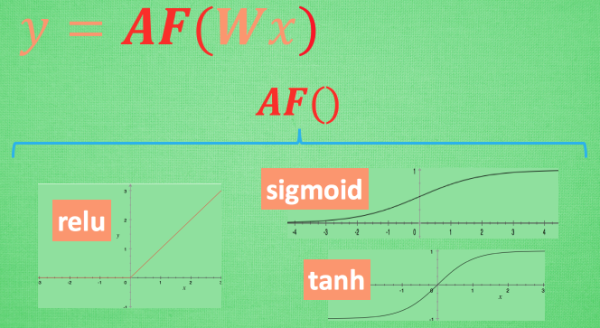
莫烦工程上的窍门
“
想要恰当使用这些激励函数, 还是有窍门的. 比如当你的神经网络层只有两三层, 不是很多的时候, 对于隐藏层, 使用任意的激励函数, 随便掰弯是可以的, 不会有特别大的影响. 不过, 当你使用特别多层的神经网络, 在掰弯的时候, 玩玩不得随意选择利器. 因为这会涉及到梯度爆炸, 梯度消失的问题. 因为时间的关系, 我们可能会在以后来具体谈谈这个问题.
最后我们说说, 在具体的例子中, 我们默认首选的激励函数是哪些. 在少量层结构中, 我们可以尝试很多种不同的激励函数. 在卷积神经网络 Convolutional neural networks 的卷积层中, 推荐的激励函数是 relu. 在循环神经网络中 recurrent neural networks, 推荐的是 tanh 或者是 relu (这个具体怎么选, 我会在以后 循环神经网络的介绍中在详细讲解).
”
import torch.nn.functional as F # 激励函数都在这
# 做一些假数据来观看图像
x = torch.linspace(-5, 5, 200) # x data (tensor), shape=(100, 1)
x = Variable(x)
# 几种常用的 激励函数
y_relu = F.relu(x).data.numpy()
y_sigmoid = F.sigmoid(x).data.numpy()
y_tanh = F.tanh(x).data.numpy()
y_softplus = F.softplus(x).data.numpy()
# y_softmax = F.softmax(x) softmax 比较特殊, 不能直接显示, 不过他是关于概率的, 用于分类