DCGAN 是在生成模型和判别模型中使用卷积和反卷积操作, 提高了模型的效果.
DCGAN相比于GAN的改进之处:
- 使用了LeakRelu 激活函数, 经过大牛的实验证明效果好于Relu
- 使用batchnormalization, 有效减少了随机初始化带来的误差
- 判别网络中使用了strides convolutions 代替了池化操作, 生成器中使用fractional strided convolutions (反卷积).
- others(具体的可以Google)
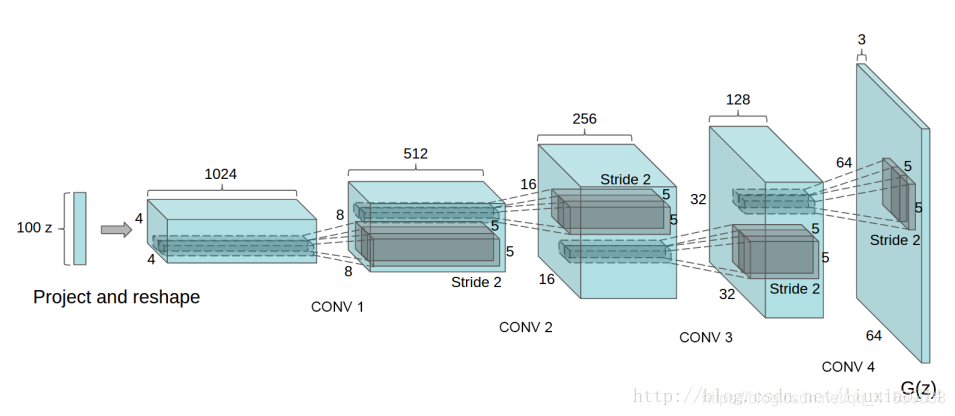
下面是代码实现,基本的GAN代码实现可以参照快速上手生成对抗生成网络生成手写数字集(直接上代码以及详细注释,亲测可用)
#代码附详细注释
import os
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# 定义几个超参数, batch-size的大小
batch_size = 64
# 噪声的长度
noise_size = 100
# 迭代的轮数
epochs = 5
# 学习率
learning_rate = 0.001
# 抽取样本检查生成器的性能
n_smples = 20
# 读取mnist数据集
mnist = input_data.read_data_sets("MNIST_DATA")
# 获取生成网络和判别网络的输入
def get_input(noise_dim, image_height, image_width, image_depth):
"""
:param noise_dim: 噪声的长度
:param image_height: 图片的高度
:param image_width: 图片的宽度
:param image_depth: 图片的深度
:return: 以placeholder形式返回两个网络的输入
"""
D_input = tf.placeholder(tf.float32, [None, image_height, image_width, image_depth], name="input_real")
G_input = tf.placeholder(tf.float32, [None, noise_dim], name="input_noise")
return D_input, G_input
# 定义生成器
def get_generator(G_input, output_dim, is_train=True, alpha=0.01):
"""
:param G_input: 生成器的输入,应该是(batch_size, 100)
:param output_dim: 生成器的输出, (batch_size, 28, 28, 1)
:param is_train: 是否训练
:param alpha: LeakyRelu的参数
:return: 返回生成的图片
"""
# 定义一个命名空间generator
with tf.variable_scope("generator", reuse=(not is_train)):
# batch x 100 x 1 ---> batch x 4 x 4 x 512
layer1 = tf.layers.dense(G_input, 4*4*512)
layer1 = tf.reshape(layer1, [-1, 4, 4, 512])
layer1 = tf.layers.batch_normalization(layer1, training=is_train)
layer1 = tf.maximum(alpha * layer1, layer1)
layer1 = tf.nn.dropout(layer1, keep_prob=0.6)
# batch x 4 x 4 x 512 ---> batch x 7 x 7 x 256
layer2 = tf.layers.conv2d_transpose(layer1, 256, 4, strides=1, padding="valid")
layer2 = tf.layers.batch_normalization(layer2, training=is_train)
layer2 = tf.maximum(alpha * layer2, layer2)
layer2 = tf.nn.dropout(layer2, keep_prob=0.6)
# batch x 7 x 7 x 256 ---> batch x 14 x 14 x 128
layer3 = tf.layers.conv2d_transpose(layer2, 128, 3, strides=2, padding="same")
layer3 = tf.layers.batch_normalization(layer3, training=is_train)
layer3 = tf.maximum(alpha * layer3, layer3)
layer3 = tf.nn.dropout(layer3, keep_prob=0.6)
# batch x 14 x 14 x 128 ---> batch x 28 x 28 x 1
logits = tf.layers.conv2d_transpose(layer3, output_dim, 3, strides=2, padding="same")
outputs = tf.tanh(logits)
return outputs
# 定义一个判别器
def get_discriminator(D_input, reuse=False, alpha=0.01):
"""
:param D_input: 输入图片
:param reuse: 是否重用参数
:param alpha: LeakyRelu的参数
:return: 返回对图片的判别结果,是一个概率值
"""
# 定义一个命名空间discriminator
with tf.variable_scope("discriminator", reuse=reuse):
# batch x 28 x 28 x 1 ---> batch x 14 x 14 x 128
layer1 = tf.layers.conv2d(D_input, 128, 3, strides=2, padding="same")
layer1 = tf.maximum(alpha * layer1, layer1)
layer1 = tf.nn.dropout(layer1, keep_prob=0.6)
# batch x 14 x 14 x 28 ---> batch x 7 x 7 x 256
layer2 = tf.layers.conv2d(layer1, 256, 3, strides=2, padding="same")
layer2 = tf.layers.batch_normalization(layer2, training=True)
layer2 = tf.maximum(alpha * layer2, layer2)
layer2 = tf.nn.dropout(layer2, keep_prob=0.6)
# batch x 7 x 7 x 256 ---> batch x 4 x 4 x 512
layer3 = tf.layers.conv2d(layer2, 512, 3, strides=2, padding='same')
layer3 = tf.layers.batch_normalization(layer3, training=True)
layer3 = tf.maximum(alpha * layer3, layer3)
layer3 = tf.nn.dropout(layer3, keep_prob=0.6)
# batch x 4 x 4 x 512 ---> batch x (16*512)
flatten = tf.reshape(layer3, (-1, 16*512))
logits = tf.layers.dense(flatten, 1)
outputs = tf.sigmoid(logits)
return logits, outputs
# 获取模型的损失值
def get_loss(D_input_real, G_input, image_depth, smooth=0.1):
"""
:param D_input: 判别模型的输入
:param G_input: 生成模型的输入
:param image_depth: 图片的通道数,彩色为3,灰度为1
:param smooth: 平滑值
:return: 返回两个网络的损失
"""
g_outputs = get_generator(G_input, image_depth, is_train=True)
# 将真实的图片放入模型中判别
d_logits_real, d_output_real = get_discriminator(D_input_real)
# 将生成器生成的图片放入判别模型中判读
d_logits_fake, d_output_fake = get_discriminator(g_outputs, reuse=True)
#计算损失, 生成器努力让图片更加逼真
g_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.ones_like(d_logits_fake)*(1-smooth)))
# 判别器努力分别出真实图片和生成图片,所以判别器的损失函数是两部分
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real,
labels=tf.ones_like(d_logits_real)*(1-smooth)))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake,
labels=tf.zeros_like(d_logits_fake)))
# 判别器的损失
d_loss = tf.add(d_loss_fake, d_loss_real)
# 返回损失
return g_loss, d_loss
# 优化操作
def get_optimizer(g_loss, d_loss, learning_rate=0.001):
"""
:param g_loss: 生成器的损失
:param d_loss: 判别器的损失
:param learning_rate: 学习率
:return: 优化操作
"""
# 分别通过tftrainable-variables()获得两个网络中的参数
train_vars = tf.trainable_variables()
g_vars = [var for var in train_vars if var.name.startswith("generator")]
d_vars = [var for var in train_vars if var.name.startswith("discriminator")]
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
g_opt = tf.train.AdamOptimizer(learning_rate).minimize(g_loss, var_list=g_vars)
d_opt = tf.train.AdamOptimizer(learning_rate).minimize(d_loss, var_list=d_vars)
# 返回优化操作
return g_opt, d_opt
# 训练模型
def train(noise_size, data_shape, batch_size, n_samples):
"""
:param noise_size: 噪声的维度
:param data_shape: 图片的形状
:param batch_size: 每个batch的大小
:param n_samples: 抽样数目
"""
# 计步器
steps = 0
# 调用get_input()函数,从而获得两个网络的输入(placeholder形式)
D_input, G_input = get_input(noise_size, data_shape[1], data_shape[2], data_shape[3])
# 获取损失值
g_loss, d_loss = get_loss(D_input, G_input, data_shape[-1])
# 获取优化操作
g_train_opt, d_train_opt = get_optimizer(g_loss, d_loss, learning_rate)
# 打开一个会话
with tf.Session() as sess:
# 初始化所有的变量
sess.run(tf.global_variables_initializer())
for epoch in range(epochs):
for i in range(mnist.train.num_examples // batch_size):
steps += 1
# 获取真实图片
batch = mnist.train.next_batch(batch_size)
batch_images = batch[0].reshape((batch_size, data_shape[1], data_shape[2], data_shape[3]))
# 生成噪音
batch_noise = np.random.uniform(-1, 1, size=(batch_size, noise_size))
# 开始优化
sess.run(g_train_opt, feed_dict={D_input: batch_images,
G_input: batch_noise})
sess.run(d_train_opt, feed_dict={D_input: batch_images,
G_input: batch_noise})
# 每间隔5步打印出结果, 并且保存生成模型生成的图片
if steps % 5 == 0:
train_loss_d = d_loss.eval({D_input: batch_images,
G_input: batch_noise})
train_loss_g = g_loss.eval({D_input: batch_images,
G_input: batch_noise})
# 保存生成的图片
temp = tf.placeholder(tf.float32, [None, 100])
sample_input_noise= np.random.uniform(-1, 1, size=(n_smples, noise_size))
generator_pictures = sess.run(get_generator(temp, 1, is_train=False), feed_dict={
temp:sample_input_noise})
# 从生成的图片中随机的选取一张保存下来
single_picture = generator_pictures[np.random.randint(0, n_samples)]
single_picture = (np.reshape(single_picture, (28, 28)) + 1) * 127.5
# 保存图片
if not os.path.exists('DC_pictures/'):
os.makedirs('DC_pictures/')
cv2.imwrite("DC_pictures/A{}.jpg".format(str(steps)), single_picture)
print(
"Epoch {}/{}... stpes:{} ".format(epoch + 1, epochs, steps),
"Discriminator loss : {:.4f}...".format(train_loss_d),
"Generator loss: {:.4f}".format(train_loss_g)
)
if __name__ == '__main__':
with tf.Graph().as_default():
train(noise_size, [-1, 28, 28, 1], batch_size, n_samples=n_smples)