文献提出了结合CNN和回归进行年龄预测的端到端的深度学习网络,网络结构图如下,
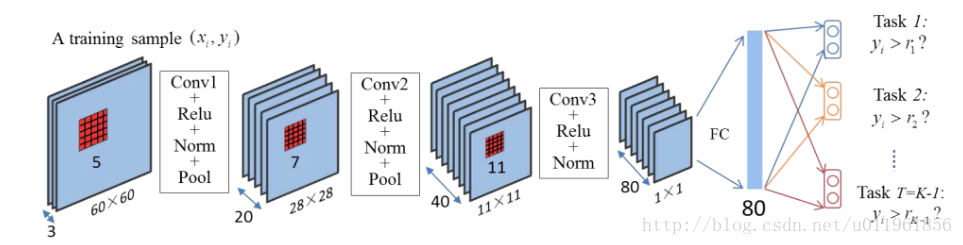
输入为
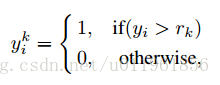
最后根据所有的100个子问题的输出结果计算预测年龄,其计算公式为:
损失函数的计算
采用交叉损失熵,对于每个类别,赋予不同的权重
- 我们有K=100个子任务,所以我们最后的损失函数公式为
Em=−1N∑Ni=1∑Tt=1(λt1oti=ytiwtilog(p(oti|xi,Wt))) - 其中
λt 代表着第t个子任务的数据权重,也就是每个年龄数据量在总数据量中的比重,其计算公式为λt=Nt√∑Ti=1Ni√ 而$ - w_i$表示每一个二分类子问题中每一个类别的权重,可以简单地设为1。 最后再利用反向梯度传播来实现参数最优化。
代码分析
文章提供了caffe代码,
输入为HDF5数据格式,
layer {
top: "data"
type: "HDF5Data"
top: "label"
name: "data"
hdf5_data_param {
source: "../data/SourceDataForCaffe/normal_Tutu_morph_wiki/hdf5_data_gray/train.txt"
batch_size: 256
}
include {
phase: TRAIN
}
}
layer {
top: "data"
top: "label"
name: "data"
type: "HDF5Data"
hdf5_data_param {
source: "../data/SourceDataForCaffe/normal_Tutu_morph_wiki/hdf5_data_gray/test.txt"
batch_size: 256
}
include {
phase: TEST
}
}对于hdf5数据的转换,可以参考代码,
import sys
import numpy as np
import matplotlib.pyplot as plt
import h5py
IMAGE_SIZE = (60, 60)
MEAN_VALUE = 128
filename = sys.argv[1]
setname, ext = filename.split('.')
with open(filename, 'r') as f:
lines = f.readlines()
np.random.shuffle(lines)
sample_size = len(lines)
imgs = np.zeros((sample_size, 1,) + IMAGE_SIZE, dtype=np.float32)
freqs = np.zeros((sample_size, 2), dtype=np.float32)
h5_filename = '{}.h5'.format(setname)
with h5py.File(h5_filename, 'w') as h:
for i, line in enumerate(lines):
image_name, fx, fy = line[:-1].split()
img = plt.imread(image_name)[:, :, 0].astype(np.float32)
img = img.reshape((1, )+img.shape)
img -= MEAN_VALUE
imgs[i] = img
freqs[i] = [float(fx), float(fy)]
if (i+1) % 1000 == 0:
print('Processed {} images!'.format(i+1))
h.create_dataset('data', data=imgs)
h.create_dataset('freq', data=freqs)
with open('{}_h5.txt'.format(setname), 'w') as f:
f.write(h5_filename)之后是卷积和FC层,最后是损失函数层,
layer {
bottom: "fc_output"
bottom: "label"
top: "loss"
name: "loss"
type: "OrdinalRegressionLoss"
include {
phase: TRAIN
}
ordinal_regression_loss_param {
weight_file: "../data/weight_file/weight_file_normal.txt"
}
}
layer {
bottom: "fc_output"
bottom: "label"
top: "loss"
name: "loss"
type: "OrdinalRegressionLoss"
include {
phase: TEST
}
ordinal_regression_loss_param {
weight_file: "../data/weight_file/weight_file_normal.txt"
}
}由于caffe没有多任务训练的损失函数,因此作者编写了对于的层,需要重新编译caffe,可以参考,
https://github.com/kongsicong/Age_recognition_OR/tree/master/OrdinalRegression
处理后便可以训练.
tensorflow模型训练
编写对应的tensorflow模型,训练lmdb年龄分类数据,测试精度为,
平均年龄误差:8.