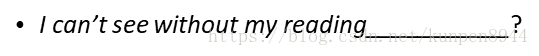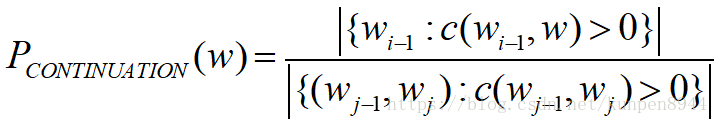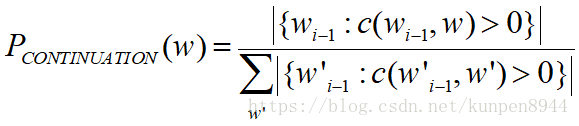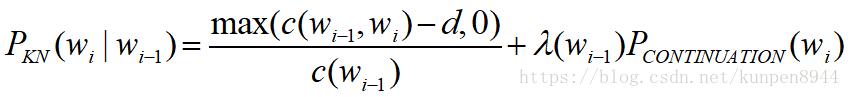一、介绍N-grams
1、概率语言模型
对每个句子给出一个概率,用以判断机器翻译中哪个句子是最佳的选择,拼写校准中哪个句子可能出现错误。
- 目标:计算句子或者是一系列单词的概率
- 相关任务:下一个词的概率
- 计算上述两者的模型就是语言模型。可能更好的叫法是语法(the grammer),但是语言模型(language model)和LM是标准的叫法。
2、如何计算P(W)
利用概率的链式法则来进行计算
- 链式法则
- 公式为:
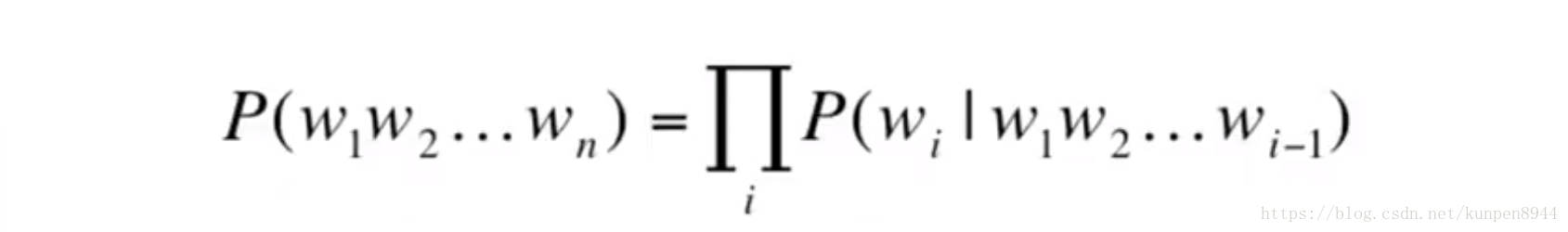
3、如何估计等式右边的概率
- 直接统计出现的次数进行比较(如下式)是不可以的。因为我们无法统计完所有可能的句子。
- 所以我们采用马尔可夫假设(Markov assumption)
或者是:
也就是说我们利用前面有限个数(k个)的单词的条件概率来估计前面所有单词的条件概率,通用公式可以表示为:
4、N-grams模型
- 利用马尔可夫假设最简单的模型是一元模型(unigram model),这个模型假设单词之间是独立的。
- 二元模型(bigram model),假设单词只与前一个单词有关联
- N元模型(N-gram model):往下拓展我们可以得到三元、四元,五元。
- 从一般意义上而言,对语言模型而言还是不够的,因为语言存在长距离相关性
- 但是对于我们研究的问题而言,大部分时候是能够解决问题的
- 利用马尔可夫假设最简单的模型是一元模型(unigram model),这个模型假设单词之间是独立的。

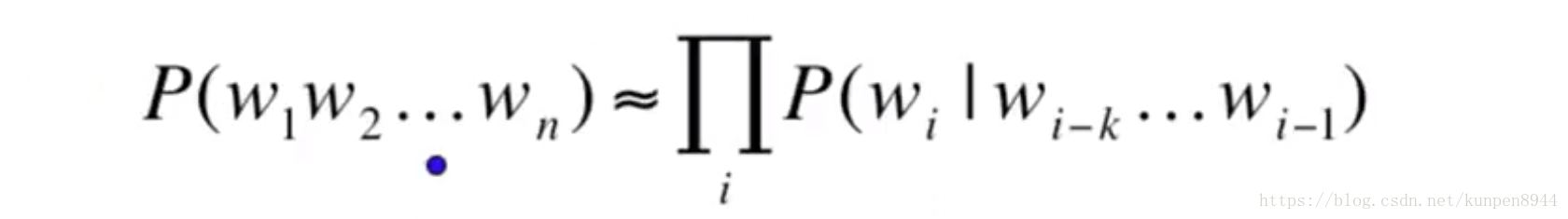
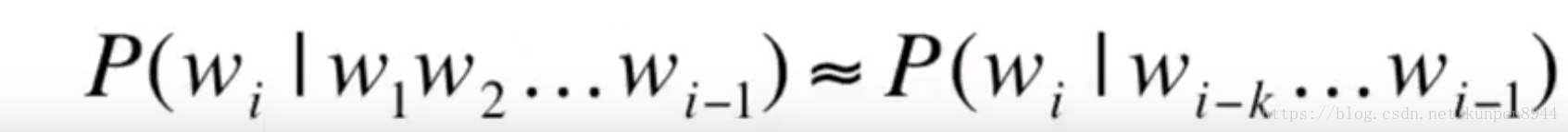
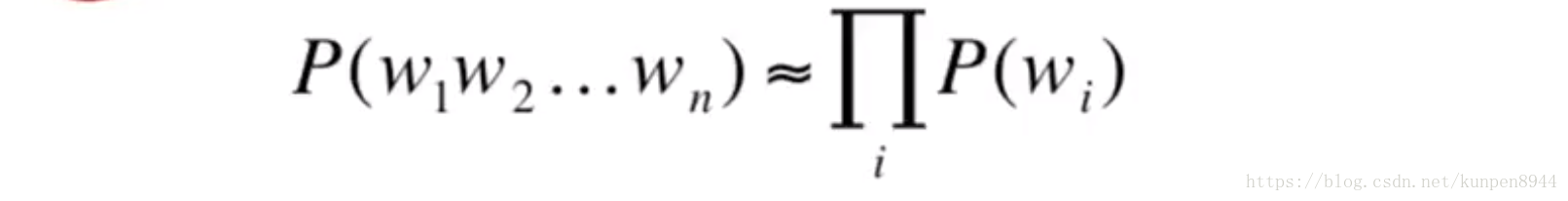
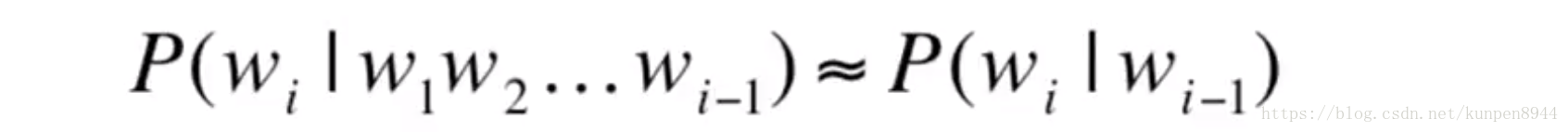
二、估计N元(N-gram)概率
1、二元概率的估计
- 极大似然的估计
- 例子
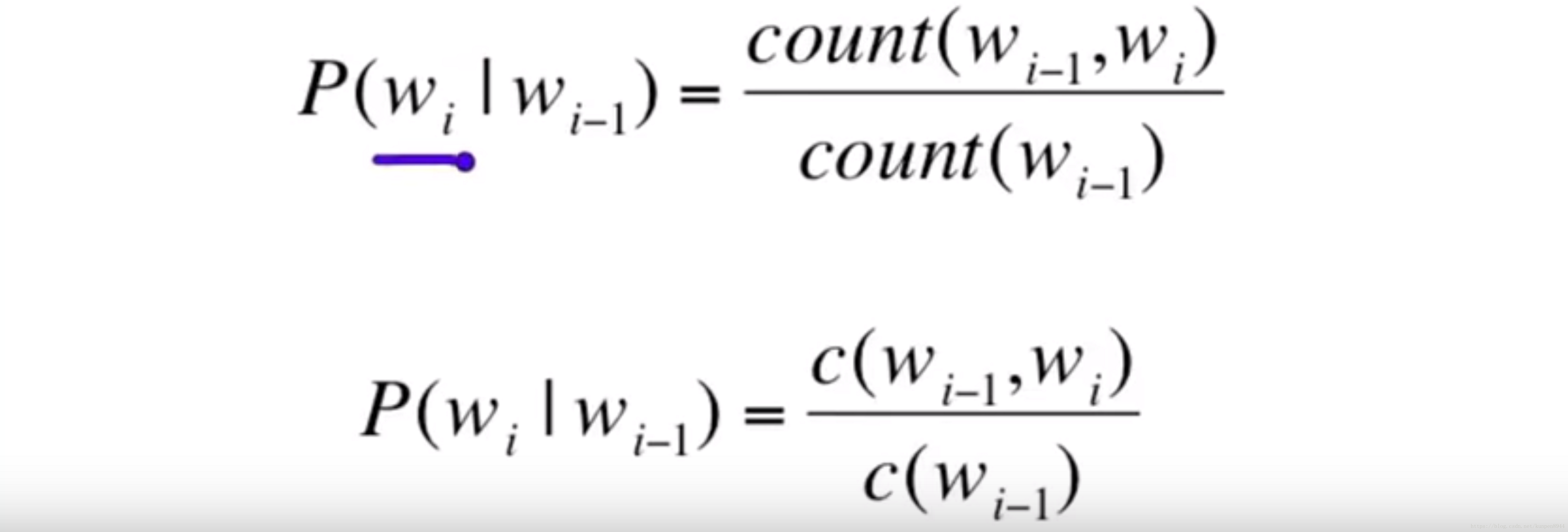

2、句子概率的二元估计

3、在实际应用中我们会以对数形式运算
优点是
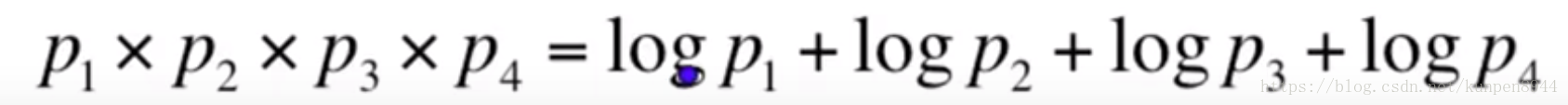
- 可以防止得到的数字过小下溢(underflow)
- 加法算起来比乘法更快
4、语言模型工具(toolkits)
- SRILM http://www.speech.sri.com/projects/srilm
- Google N-Gram Release (2006年八月)http://googleresearch.blogspot.com/2006/08/all-our-n-gram-are-belong-to-you.html
- Google book N-grams http://ngrams.googlelabs.com/
三、Evaluation and Perplexity
1、N元模型的外部估计(extrinsic evaluation)
- 比较模型A和模型B的最好估计:给AB两个模型一样的任务,比较A和B的任务的正确情况
- 问题这样的估计有的时候非常费时,所以我们的有的时候会使用内部(intrinsic)估计:perplexity。
- perplexity不是一个好的近似,只有在测试数据和训练数据相似的时候,才比较好。所以我们一般用在中间试验(pilot experiment)
2、Perplexity的一种度量
- 一个比较好的模型,应该给实际上会出现的单词更高的概率。最好的模型,应该是在测试集上表现得最好的模型。
- Perplexity就是在测试集上度量的概率,并且用单词数进行标准化,等价于最大化概率。
使用链式法则
当二元模型时:
3、perplexity的第二种度量
- 这种定义来源于Josh Goodman
- 认为perplexity可以用加权等价分支因子(wighted equivalent branching factor),也就是每次有可能发生,并进行加权标准化。
- 对于一个识别数字的问题而言,(0,1,2,3,4,5,6,7,8,9),perplexity是10
4、更低的perplexit代表更好的模型

四、一般化与零(Generalization and Zeros)
1、香农可视化法(Shannon Visualization method)
- 根据概率选择一个随机的二元(<s>, w)
- 根据概率再选择随机二元(w,s)
- 一直到我们最后得到<\s>
- 然后把这些字符串表现出来
- 比如

2、以莎士比亚作为训练语料库
- N=884647 tokens,V=29066
- 在所有可能的二元组中(V的平方次84亿),实际出现的二元组只有30万左右,所以99.96%的二元组没有出现(在表中表现为0)
- 多元模型会更加表现出对莎士比亚的相似性
3、过拟合与一般化
- 而以其他语料库进行训练的话,他们就会表现得和莎士比亚不同。这里就会存在一个过拟合的问题。也就是在和训练集相似的测试集上才能得到好的结果。
- 因此我们需要更稳健一般化的模型,就需要关注0,也就是在测试集中出现,但是没有在训练集中出现的。
- 零概率二元:当在测试集中有0概率二元组出现的时候,perplexity就没有办法计算(0出现在分母上)。所以,我们需要方法来进行处理。
五、拉普拉斯平滑
1、所谓拉普拉斯平滑
- 也被称作加一估计(add-one estimation),假设我们每次都比实际的单词数目多1.
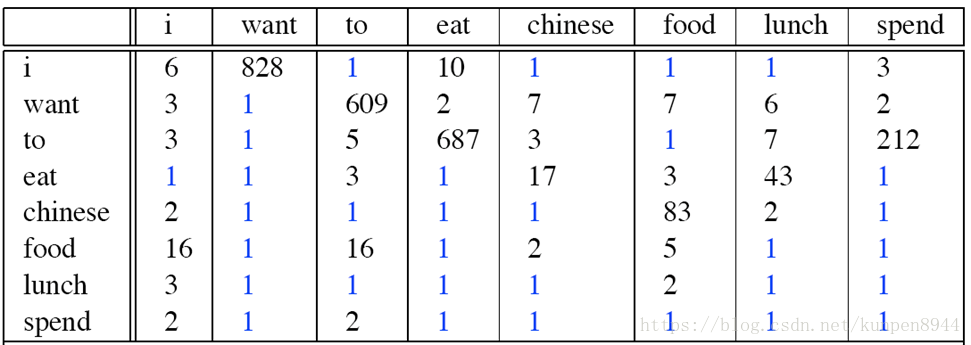
- 拉普拉斯平滑之后的二元模型的一个例子:
重新进行次数计算可得到:(和原来的次数比较就会发现,原先很多的次数变小了,而原来是0的次数不为0了)

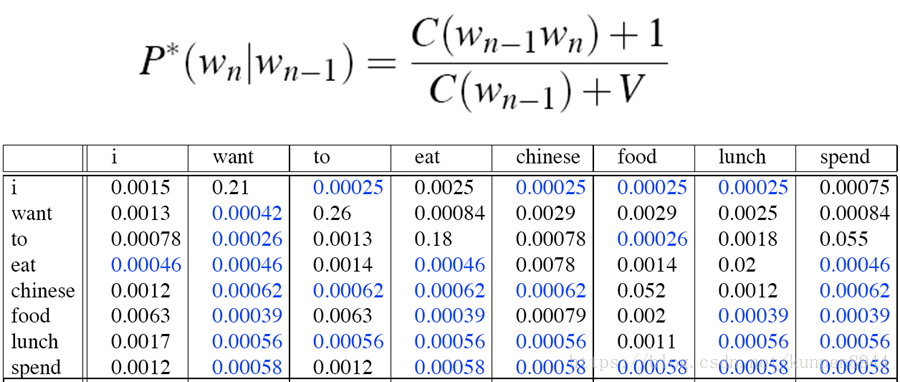

2、拉普拉斯平滑是一个相对粗糙的方法
- 加一法不会被用在N元模型中,相反我们会有更好的方法
- 但是加一法确实被用在其他的NLP模型的平滑之中,比如文本分类,以及其它0的数目不是那么巨大的领域中。
六、 插值,退化以及web级别语言模型(Interpolation,backoff and web-scale LMs)
1、退化(backoff )与插值(Interpolation)
- 这两种方法能够帮助我们用更少的文本进行训练
- 退化:在能得到比较好的数据的时候,使用三元模型,否则则使用二元,甚至是一元模型。
- 插值:混合一元、二元和三元模型的结果
- 一般而言插值的效果会更好
2、线性插值
- 简单线性插值
- 基于上下文的条件lamda
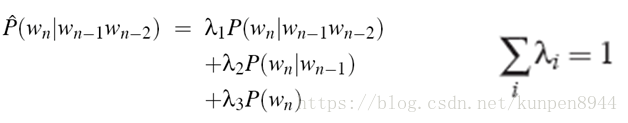
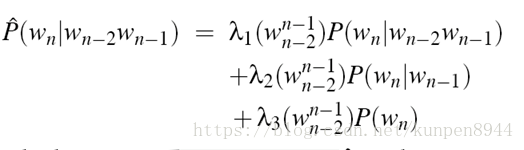
3、如何确定lambda?
- 使用预留(held-out)语料
- 选择使得预留数据概率最大化的lambda

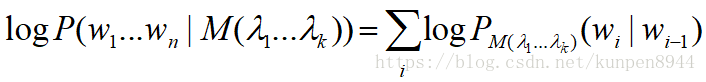
4、未知的单词(开放和封闭的词汇任务)
- 封闭词汇任务(closed vocabulary task):词汇是固定的
- 开放词汇任务(open vocabulary task):存在一些超出词汇的词(OOV words| out of vocabulary words)
- 处理方法:创建一个<UNK>
- 对<UNK>概率的训练
- 创建一个规模为V的固定词汇L
- 在文本标准化的阶段,任何不在L中的训练单词都改为<UNK>
- 然后我们就可以像一个正常的单词去训练
- 在解码(decoding)阶段:对那些不在训练集中的单词赋予<UNK>的概率
- 对<UNK>概率的训练
5、巨型web规模N元
- 比如说:google N-gram corpus
- 剪枝
- 只存储出现次数大于阈值的N元组,比如:对于那些高维的N元组只出现一次的移除
- 基于熵的剪枝
- 效率
- 使用高效的数据结构,比如tries
- Bloom filter:近似语言模型
- 用索引而不是字符串来存储单词:利用哈夫曼编码把单词转化为二进制的
- 用4-8位存储,而不是8byte的浮点数
- 常用的平滑方法:stupid backoff(Brants et al.2007)如果在n元模型的时候计数为0,那么就退化到n-1元。
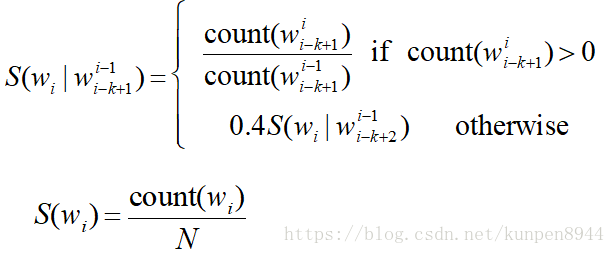
6、N元平滑总结
- 加一平滑:文本分类是合适的,但是不适用于语言建模
- 最经常使用的方法:Extended Interpolated Kneser-Ney
- 对于大型的N元e.g web:stupid backo
7、高级语言模型

七、进阶:好的剪枝平滑
1、加k(add-k)平滑:加一平滑的衍生
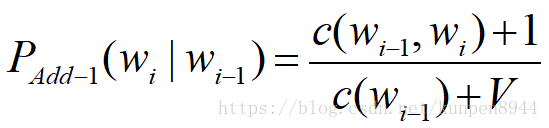
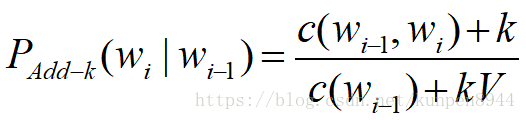
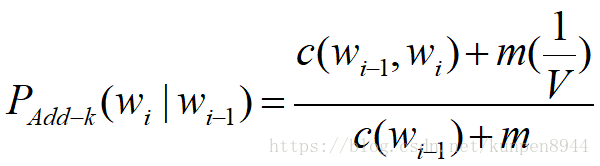
2、一元先验平滑(unigram prior smoothing)
基于Add-k衍生,可以得到一元先验平滑(unigram prior smoothing)
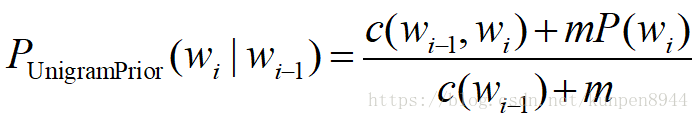
3、进阶平滑算法
- 被下面三种算法使用(good-turing,Kneser-Ney, Wittern Bell)
- 主要的思想是:利用我们统计出来次数为1的次数来估计没有出现的事物。
- 定义Nc表示频率c的频率
- 例子:
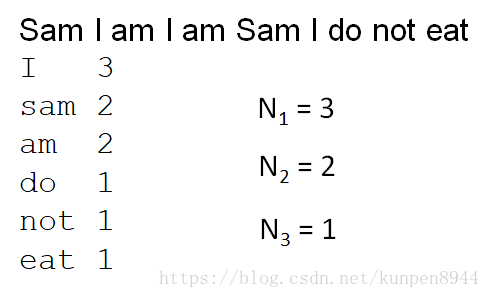
4、good-turing算法
- 对出现次数为0的计算:
- 对出现次数大于0的计算:
- 例子:
- 在河边垂钓,已经钓到鱼的情况如下:
- 下一条鱼是新品种的概率(比如catfish/bass):
- 下一条鱼是trout的概率
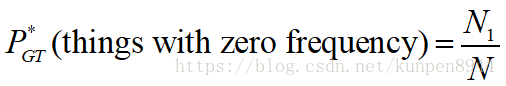
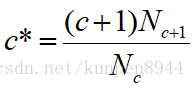
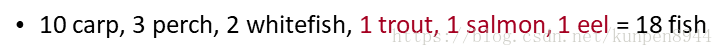


5、Ney et al的Good turing方法的解释
- 针对上面的方程,我们可以放到一个情景里面去理解它的正确性
- 假设我们对一个长度为c的样本进行留一法抽样,那就可以得到c个训练集。
- 那么在c个训练集中留出的单词没有出现在训练集中的比例是
- 那么在c个训练集中留出的单词在训练集中出现k次的比例是
- 所以我们会说,上面的公式就是那些在训练集中出现k次的预期
- Nk个单词出现了k次
- 所以每一个出现的概率是
- 预期的次数为
6、 Good turing complication
- the的问题:对于大k而言,是很稀疏的,无法得到k-1的数据,比如说单词the。
- 改进方法:一旦记数不可靠,我们就用指数法则来代替。


八、Kneser Ney Smoothing
1、绝对折扣插值(absolute discounting interpolation)
- 直接在count的数目上减去一个折扣d(discount)
- 有的时候count为1或者2的会有单独的折扣d
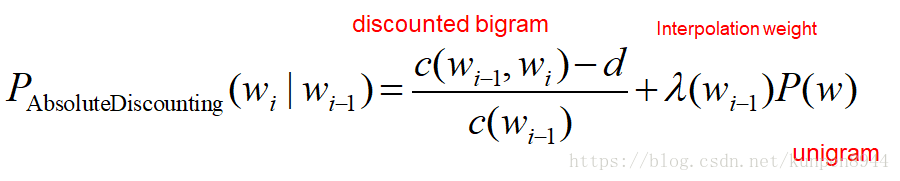
2、Kneser Ney Smoothing
- 在上面的绝对折扣插值中会存在一个问题:P(w)的估计是不准确的,比如说在这样一句话中:
当我们统计出来P(w),Franciso的概率要高于glasses。但是实际上,Franciso只会出现在San后面的概率高,因此不能简单使用P(w),所以这里使用了另外一个概念:
- 这个新概念的定义公式如下:
- 其中分子表示的是,以w为第二个词的二元组的个数(这里重复的二元组只记一次数,比如样本为,chinese food,Indian food,chinese food,San Franciso,w是food的时候,分子是2。
- 分母表示的是所有的不重复的二元组的个数,比如样本为,chinese food,Indian food,chinese food,San Franciso,w是food的时候,分母是3。
- 等价可以表示为:
- 所以,在Kneser Ney Smoothing中,平滑的公式如下:
- 其中lamba是一个标准化的常数,计算公式如下:
- 其中lamba是一个标准化的常数,计算公式如下: