三者都是对数据进行预处理的方式,目的都是为了让数据便于计算或者获得更加泛化的结果,但是不改变问题的本质。
标准化(Standardization)
归一化(normalization)
正则化(regularization)
归一化
我们在对数据进行分析的时候,往往会遇到单个数据的各个维度量纲不同的情况,比如对房子进行价格预测的线性回归问题中,我们假设房子面积(平方米)、年代(年)和几居室(个)三个因素影响房价,其中一个房子的信息如下:
- 面积(S):150 平方米
- 年代(Y):5 年
这样各个因素就会因为量纲的问题对模型有着大小不同的影响,但是这种大小不同的影响并非反应问题的本质。
为了解决这个问题,我们讲所有的数据都用归一化处理至同一区间内。
正则化
这篇文章对于正则化的讲解通俗易懂:https://www.zhihu.com/question/20924039
正则化主要用于防止过拟合
我们在训练模型时,要最小化损失函数,这样很有可能出现过拟合的问题(参数过多,模型过于复杂),所以我么在损失函数后面加上正则化约束项,转而求约束函数和正则化项之和的最小值。
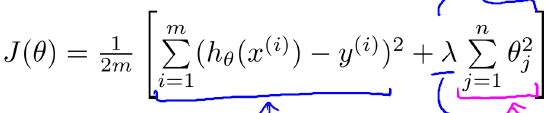
上式中,蓝色部分即为损失函数,红色部分是正则化项(参数的2-范数)
标准化
标准化也是将样本的特征转化只同一量纲下的一种方法,标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。
但是在机器学习的数据预处理中,归一化和正则化更为常用。