语音学习笔记(四)【传统声学模型】
1.混合高斯模型(GMM)
当使用混合高斯随机变量的分布用于匹配语音特征时,就形成了混合高斯模型(GMM)。
1.1随机变量
1)随机变量可以理解为从随机实验到变量的一个映射;
2)随机变量所有可能的取值成为域;
3)连续随机变量的概率密度函数(Probability density function,PDF):p(x)
4)随机变量在x=a处的累计分布函数 : 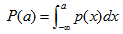
1.2 高斯分布和混合高斯随机变量
1)高斯分布
标量:若随机变量x的概率密度函数是: 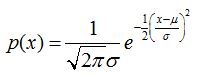
那么它服从正态分布或高斯分布,记为: 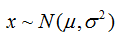
矢量/向量:对于高斯分布的随机变量矢量x=(x1,x2,…,xD)T,也成为多元或向量值高斯随机变量,其联合概率密度函数为: 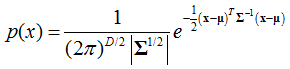
同样,记为: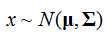
2)混合高斯分布
标量:服从混合高斯分布的随机变量x,其概率密度函数为:(M个高斯) 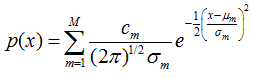
其中混合权重为正实数,其和为1: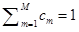
混合高斯分布最明显的性质是他的多模态(M大于1),不同于高斯分布的单模态(M=1),这使得混合高斯模型足以描述很多显示出多模态性质的物理数据,比如语音数据,而单高斯分布则不合适。
矢量/向量:多变量的多元混合高斯分布,即,服从高斯分布的随机变量向量,其联合概率密度函数为: 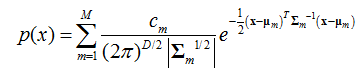
在DNN出现之前,GMM是提升语音识别系统性能的一个关键,且一般M为一个先验值。
如果变量x的维度D很大,比如语音识别中的特征40维,那么使用全协方差矩阵(非对角)(∑m)将引入大量参数(大约M x D^2)。为了减少这个数量,可以使用对角协方差矩阵。对角协方差矩阵极大简化了计算量。将全协方差矩阵近似为对角协方差矩阵看似是使用了各维度不相关的假设,实际是一种误导,因为,混合高斯模型具有多个高斯成分,虽然每个成分都使用了对角协方差矩阵,但总体上至少可以有效的描述由一个使用全协方差矩阵的单高斯模型所描述的向量维度相关性。