python处理二进制数据时可以使用python的struct模块。
struct模块中最重要的三个函数是pack(), unpack(), calcsize():
pack(fmt, v1, v2, ...) 按照给定的格式(fmt),返回一个包装后的字符串。
unpack(fmt, string) 按照给定的格式(fmt)解析字节流string,返回一个解析出来的tuple。
calcsize(fmt) 计算给定的格式(fmt)占用多少字节的内存。
struct中支持的格式如下表:
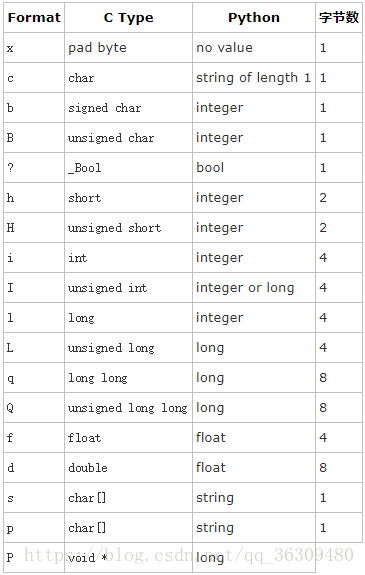
可以用格式(fmt)中的第一个字符来改变对齐方式。定义如下:

如果没有附加,默认为@。
例子如下:
扫描二维码关注公众号,回复:
3964825 查看本文章

>>> import struct
>>> a = struct.pack('ihb',1,2,3)
>>> a
b'\x01\x00\x00\x00\x02\x00\x03'
>>> b = struct.unpack('ihb',a)
>>> b
(1, 2, 3)
首先将参数1,2,3打包。
打包前1,2,3明显属于python数据类型中的integer,打包后就成了C结构的二进制串。
转成python的string类型来显示就是'\x01\x00\x00\x00\x02\x00\x03'。由于本机是小端因此高位放在低地址段。
i:代表C结构中的int类型,占4位,表示为01000000;
h:代表C结构中的short类型,占2位,表示为0200;
b:代表C结构中的signed char类型,占1位,表示为03。
再来看一个例子:
>>> a = struct.pack('!ihb',1,2,3)
>>> a
b'\x00\x00\x00\x01\x00\x02\x03'
>>> b = struct.unpack('!ihb',a)
>>> b
(1, 2, 3)
使用的format string中首位为'!',即为大端模式标准对齐方式。
故而输出为'\x00\x00\x00\x01\x00\x02\x03',其中高位就被放在内存的高地址位了。