1.二叉树的常用性质
<1>.在二叉树的第i层上最多有2 i-1 个节点 。(i>=1)
<2>.二叉树中如果深度为k(有k层),那么最多有2k-1个节点。(k>=1)
<3>.若二叉树按照从上到下从左到右依次编号,则若某节点编号为k,则其左右子树根节点编号分别为2k和2k+1;
<4>.二叉树分类:满二叉树,完全二叉树
满二叉树:高度为h,由2^h-1个节点构成的二叉树称为满二叉树。


<5>.在完全二叉树中,具有n个节点的完全二叉树的深度为[log2n]+1,其中[log2n]+1是向下取整。满二叉树的深度为k=log2(n+1);
二.二叉树的三种访问方式
1.先序遍历:按照根节点->左子树->右子树的顺序访问二叉树


先序遍历:(1)访问根节点;(2)采用先序递归遍历左子树;(3)采用先序递归遍历右子树;
(注:每个节点的分支都遵循上述的访问顺序,体现“递归调用”)
先序遍历结果:A BDFE CGHI
思维过程:
(1)先访问根节点A,
(2)A分为左右两个子树,因为是递归调用,所以左子树也遵循“先根节点-再左-再右”的顺序,所以访问B节点,
(3)然后访问D节点,
(4)访问F节点的时候有分支,同样遵循“先根节点-再左--再右”的顺序,
(5)访问E节点,此时左边的大的子树已经访问完毕,
(6)然后遵循最后访问右子树的顺序,访问右边大的子树,右边大子树同样先访问根节点C,
(7)访问左子树G,
(8)因为G的左子树没有,所以接下俩访问G的右子树H,
(9)最后访问C的右子树I
2.中序遍历:按照左子树->根节点->右子树的顺序访问
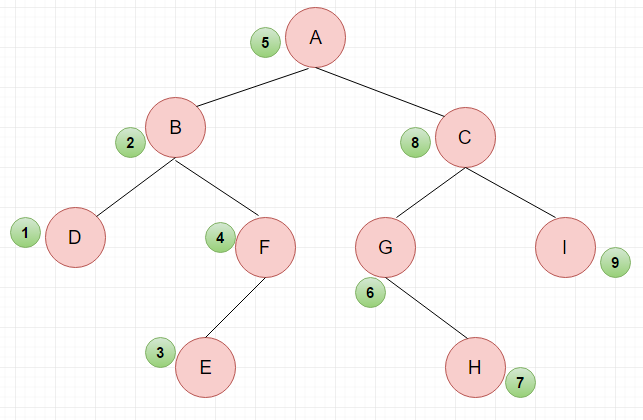
中序遍历:(1)采用中序遍历左子树;(2)访问根节点;(3)采用中序遍历右子树
中序遍历结果:DBEF A GHCI
3.后序遍历
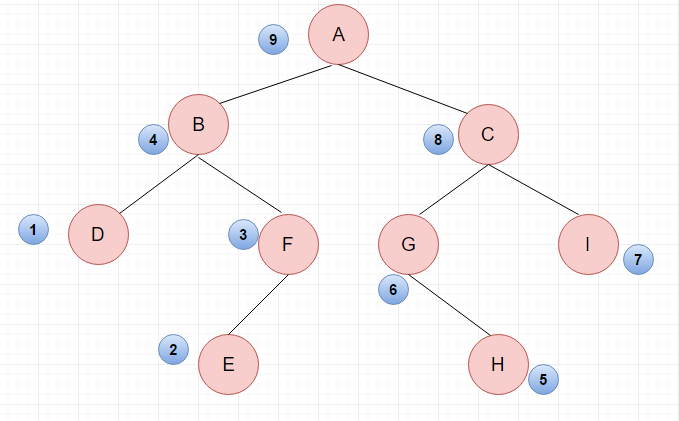
后序遍历:(1)采用后序递归遍历左子树;(2)采用后序递归遍历右子树;(3)访问根节点;
后序遍历的结果:DEFB HGIC A
小结:三种方法遍历过程中经过节点的路线一样;只是访问各个节点的时机不同。
递归算法主要使用堆栈来实现。
1.创建一个结构体
type treeNode struct {
value string
left, right *treeNode
}
2.创建一个如上图所示的树
//创建一颗树
root := treeNode{"A", nil, nil}
root.left = &treeNode{value:"B"}
root.right = &treeNode{value:"C"}
root.left.left = &treeNode{value:"D"}
root.left.right = &treeNode{value:"F"}
root.left.right.left = new(treeNode)
root.left.right.left.value = "E"
root.right.left = &treeNode{value:"G"}
root.right.left.right = &treeNode{value:"H"}
root.right.right = &treeNode{value:"I"}3.go实现,通过递归来实现二叉树的遍历,更改print打印顺序就可以进行不同遍历,是不是很方便
1⃣️先序遍历
func (node *treeNode)traverse(){
if(node == nil){
return
}
fmt.Print(node.value + " ")
node.left.traverse()
node.right.traverse()
}
遍历结果:A B D F E C G H I2⃣️中序遍历
func (node *treeNode)traverse(){
if(node == nil){
return
}
node.left.traverse()
fmt.Print(node.value + " ")
node.right.traverse()
}
遍历结果:D B E F A G H C I
3⃣️后序遍历
func (node *treeNode)traverse(){
if(node == nil){
return
}
node.left.traverse()
node.right.traverse()
fmt.Print(node.value + " ")
}
遍历结果:D E F B H G I C A