安装Hadoop单节点集群
1. 下载并解压Hadoop
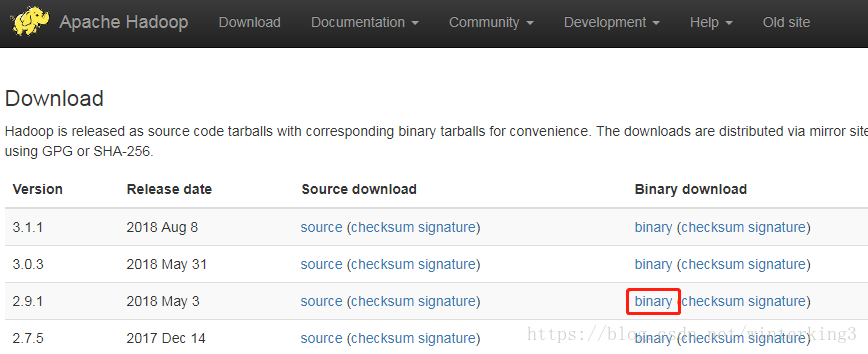
1.1 下载Hadoop
从Hadoop官网上下载,他会推荐我们从清华的镜像下载,这里我选择2.9.1版本
1.2 解压Hadoop包
$ tar -zxvf hadoop-2.9.1.tar.gz
1.3 将解压的文件夹重命名为Hadoop,然后拷贝到/usr/local下
2. 设置Hadoop环境变量
2.1 打开.bashrc文件
$ sudo gedit ~/.bashrc
2.2 在文件里后面添加如下配置
export JAVA_HOME=/usr/lib/jdk/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
2.3 让配置立即生效
$ source ~/.bashrc
3. 修改Hadoop配置文件
在hadoop目录下有etc文件夹,etc里有hadoop子文件夹,这个里面放的是hadoop的配置文件
3.1 修改hadoop-env.sh
将原来的export JAVA_HOME=${JAVA_HOME},改成自己本机的jdk路径

3.2 修改core-site.xml
添加如下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
3.3 修改yarn-site.xml
添加如下配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
3.4 修改mapred-site.xml
之前只有mapred-site.xml.template这个文件,复制一个这个,并重命名为mapred-site.xml,添加如下配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4. 创建并格式化HDFS目录
4.1 在hadoop下新建hadoop_data/hdfs文件夹,在hdfs下新建namenode和datanode文件夹
$ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
$ sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
4.2 将hadoop目录的所有者改为当前用户(winter)
$ sudo chown winter:winter -R /usr/local/hadoop
4.3 在hdfs-site.xml添加配置
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
4.4 将HDFS格式化
$ hadoop namenode -format
5. 启动Hadoop
#启动HDFS
$ start-dfs.sh
#启动MapReduce框架 YARN
$ start-yarn.sh
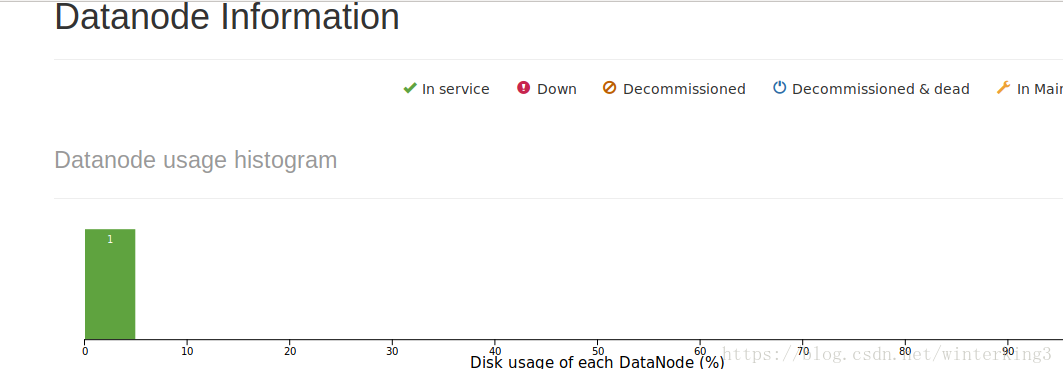
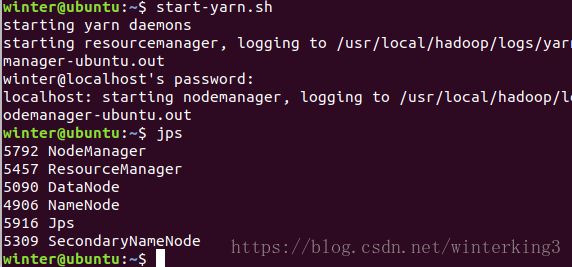
输入jps命令查看已经启动的进程
扫描二维码关注公众号,回复:
3987577 查看本文章