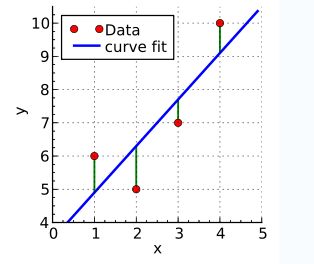
先选取最为简单的一元线性函数拟合助于我们理解最小二乘法的原理。
要让一条直接最好的拟合红色的数据点,那么我们希望每个点到直线的残差都最小。
y
i
=
b
+
a
x
i
y_{i}= b+ax_{i}
y i = b + a x i
S
=
∑
i
=
1
n
(
y
−
b
−
a
x
i
)
2
S=\sum_{i=1}^{n}(y-b-ax_{i})^2
S = ∑ i = 1 n ( y − b − a x i ) 2
b
,
a
b,a
b , a
S
S
S
b
,
a
b,a
b , a
∂
S
∂
b
=
−
2
∑
i
=
1
n
(
y
i
−
b
−
a
x
i
)
=
0
{\frac{\partial S}{\partial b}}= -2\sum_{i=1}^{n}(y_{i}-b-ax_{i})=0
∂ b ∂ S = − 2 i = 1 ∑ n ( y i − b − a x i ) = 0
∂
S
∂
a
=
−
2
∑
i
=
1
n
(
y
i
−
b
−
a
x
i
)
x
i
=
0
{\frac{\partial S}{\partial a}}= -2\sum_{i=1}^{n}(y_{i}-b-ax_{i})x_{i}=0
∂ a ∂ S = − 2 i = 1 ∑ n ( y i − b − a x i ) x i = 0
a
=
n
∑
x
i
y
i
−
∑
x
i
∑
y
i
n
∑
x
i
2
−
(
∑
x
i
)
2
a= \frac{ n\sum x_{i}y_{i}-\sum x_{i}\sum y_{i}}{n\sum x_{i}^2-(\sum x_{i})^2}
a = n ∑ x i 2 − ( ∑ x i ) 2 n ∑ x i y i − ∑ x i ∑ y i
b
=
y
‾
−
a
x
‾
b=\overline{y}-a\overline{x}
b = y − a x
∂
S
∂
b
=
−
2
∑
i
=
1
n
(
y
i
−
b
−
a
x
i
)
=
0
{\frac{\partial S}{\partial b}}= -2\sum_{i=1}^{n}(y_{i}-b-ax_{i})=0
∂ b ∂ S = − 2 i = 1 ∑ n ( y i − b − a x i ) = 0
∂
S
∂
a
=
−
2
∑
i
=
1
n
(
y
i
−
b
−
a
x
i
)
x
i
=
0
{\frac{\partial S}{\partial a}}= -2\sum_{i=1}^{n}(y_{i}-b-ax_{i})x_{i}=0
∂ a ∂ S = − 2 i = 1 ∑ n ( y i − b − a x i ) x i = 0
令
∂
D
∂
a
=
0
\frac{\partial D}{\partial a}=0
∂ a ∂ D = 0
∂
D
∂
a
\frac{\partial D}{\partial a}
∂ a ∂ D
n
x
ˉ
=
∑
i
=
1
n
x
i
,
n
y
ˉ
=
∑
i
=
1
n
y
i
n\bar{x}=\sum_{i=1}^nx_i,n\bar{y}=\sum_{i=1}^ny_i
n x ˉ = ∑ i = 1 n x i , n y ˉ = ∑ i = 1 n y i
n
y
ˉ
−
n
a
−
b
n
x
ˉ
=
0
n\bar{y}-na-bn\bar{x}=0
n y ˉ − n a − b n x ˉ = 0
∑
i
=
1
n
x
i
y
i
−
a
∑
i
=
1
n
x
i
−
b
∑
i
=
1
n
x
i
2
=
0
\sum_{i=1}^nx_iy_i-a\sum_{i=1}^nx_i-b\sum_{i=1}^nx_i^2=0
i = 1 ∑ n x i y i − a i = 1 ∑ n x i − b i = 1 ∑ n x i 2 = 0
得:
b
=
y
ˉ
−
a
x
ˉ
b=\bar{y}-a\bar{x}
b = y ˉ − a x ˉ
∑
i
=
1
n
x
i
y
i
−
y
ˉ
∑
i
=
1
n
x
i
+
b
x
ˉ
∑
i
=
1
n
x
i
2
=
0
\sum_{i=1}^nx_iy_i-\bar{y}\sum_{i=1}^nx_i+b\bar{x}\sum_{i=1}^nx_i^2=0
i = 1 ∑ n x i y i − y ˉ i = 1 ∑ n x i + b x ˉ i = 1 ∑ n x i 2 = 0
最终得
b
=
y
ˉ
−
a
x
ˉ
b=\bar{y}-a\bar{x}
b = y ˉ − a x ˉ
a
=
∑
i
=
1
n
x
i
y
i
−
y
ˉ
∑
i
=
1
n
x
i
∑
i
=
1
n
x
i
2
−
x
ˉ
∑
i
=
1
n
x
i
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
2
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
a=\frac{\sum_{i=1}^nx_iy_i-\bar{y}\sum_{i=1}^nx_i}{\sum_{i=1}^nx_i^2-\bar{x}\sum_{i=1}^nx_i}=\frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})^2}{\sum_{i=1}^n(x_i-\bar{x})^2}
a = ∑ i = 1 n x i 2 − x ˉ ∑ i = 1 n x i ∑ i = 1 n x i y i − y ˉ ∑ i = 1 n x i = ∑ i = 1 n ( x i − x ˉ ) 2 ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) 2
求和性质:具体可以参考Introductory Econometrics A Modern Approach (Fourth Edition) 一书(计量经济学导论,第4版,杰弗里·M·伍德里奇 著)的附录A。
求和性质证明:
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
=
∑
i
=
1
n
(
x
i
2
−
2
x
i
x
ˉ
+
x
ˉ
2
)
\sum_{i=1}^n(x_i-\bar{x})^2=\sum_{i=1}^n(x_i^2-2x_i\bar{x}+\bar{x}^2)
i = 1 ∑ n ( x i − x ˉ ) 2 = i = 1 ∑ n ( x i 2 − 2 x i x ˉ + x ˉ 2 )
=
∑
i
=
1
n
x
i
2
−
2
x
ˉ
∑
i
=
1
n
x
i
+
∑
i
=
1
n
x
ˉ
2
=\sum_{i=1}^nx_i^2-2\bar{x}\sum_{i=1}^nx_i+\sum_{i=1}^n\bar{x}^2
= i = 1 ∑ n x i 2 − 2 x ˉ i = 1 ∑ n x i + i = 1 ∑ n x ˉ 2
=
∑
i
=
1
n
−
2
n
x
ˉ
2
+
n
x
ˉ
2
=\sum_{i=1}^n-2n\bar{x}^2+n\bar{x}^2
= i = 1 ∑ n − 2 n x ˉ 2 + n x ˉ 2
=
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
=
∑
i
=
1
n
x
i
2
−
x
ˉ
∑
i
=
1
n
x
i
=\sum_{i=1}^nx_i^2-n\bar{x}^2=\sum_{i=1}^nx_i^2-\bar{x}\sum_{i=1}^nx_i
= i = 1 ∑ n x i 2 − n x ˉ 2 = i = 1 ∑ n x i 2 − x ˉ i = 1 ∑ n x i
(2)
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})
i = 1 ∑ n ( x i − x ˉ ) ( y i − y ˉ )
=
∑
i
=
1
n
(
x
i
y
i
−
x
i
y
ˉ
−
x
ˉ
y
i
+
x
ˉ
y
ˉ
)
=\sum_{i=1}^n(x_iy_i-x_i\bar{y}-\bar{x}y_i+\bar{x}\bar{y})
= i = 1 ∑ n ( x i y i − x i y ˉ − x ˉ y i + x ˉ y ˉ )
=
∑
i
=
1
n
x
i
y
i
−
∑
i
=
1
n
x
i
y
ˉ
−
∑
i
=
1
n
x
ˉ
y
i
+
∑
i
=
1
n
x
ˉ
y
ˉ
=\sum_{i=1}^nx_iy_i-\sum_{i=1}^nx_i\bar{y}-\sum_{i=1}^n\bar{x}y_i+\sum_{i=1}^n\bar{x}\bar{y}
= i = 1 ∑ n x i y i − i = 1 ∑ n x i y ˉ − i = 1 ∑ n x ˉ y i + i = 1 ∑ n x ˉ y ˉ
=
∑
i
=
1
n
x
i
y
i
−
n
x
ˉ
y
ˉ
−
n
x
ˉ
y
ˉ
+
n
x
ˉ
y
ˉ
=\sum_{i=1}^nx_iy_i-n\bar{x}\bar{y}-n\bar{x}\bar{y}+n\bar{x}\bar{y}
= i = 1 ∑ n x i y i − n x ˉ y ˉ − n x ˉ y ˉ + n x ˉ y ˉ
=
∑
i
=
1
n
x
i
y
i
−
y
ˉ
∑
i
=
1
n
x
i
=\sum_{i=1}^nx_iy_i-\bar{y}\sum_{i=1}^nx_i
= i = 1 ∑ n x i y i − y ˉ i = 1 ∑ n x i
将算法转化为python语言:
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
"""
一元线性拟合
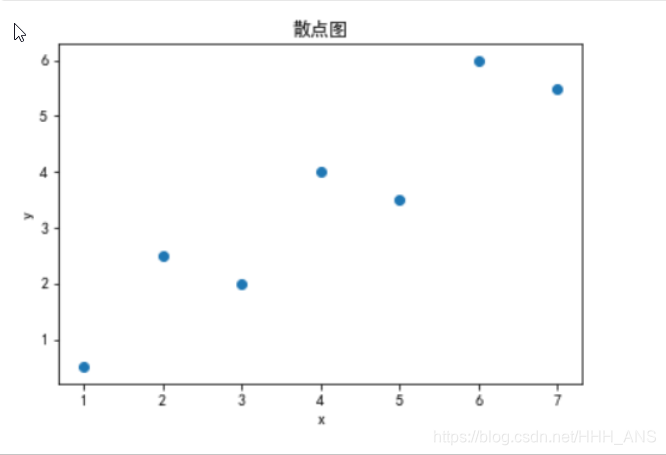
采用的拟合数据为xi=1,2,3,4,5,6,7
对应的相应函数值yi=0.5,2.5,2.4,3.5,6,5.5
"""
x=[1,2,3,4,5,6,7]
y=[0.5,2.5,2,4,3.5,6,5.5]
"""
离散点图像绘制
"""
plt.scatter(x,y)
plt.xlabel("x")
plt.ylabel("y")
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
plt.title("散点图")
plt.show()
"""
计算拟合曲线参数a,b
"""
size = len(x)
sum_x=0
sum_y=0
average_x=0
average_y=0
sum_xy=0
sum_sqare_x=0
b=0
for i in range(size):
sum_x+=x[i]
sum_y+=y[i]
sum_xy+=x[i]*y[i]
sum_sqare_x+=pow(x[i],2)
average_x=sum_x/size
average_y=sum_y/size
a= (sum_xy-average_y*sum_x)/(sum_sqare_x-average_x*sum_x)
b=(average_y-a*average_x)
print("a=",a)
print("b=",b)
a= 0.8392857142857143
"""
绘制拟合曲线
"""
data_new_y=[]
i = 0
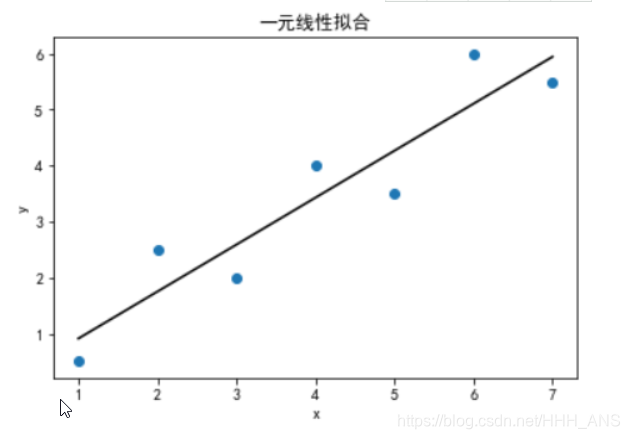
plt.scatter(x,y,label='sin')
plt.title("一元线性拟合")
plt.xlabel("x")
plt.ylabel("y")
for i in range(size):
data_new_y.append(a*x[i]+b)
plt.plot(x,data_new_y,color='black')
plt.show()
在预测中,可能结果受到多个变量的影响,那么我们的拟合曲线就由
y
=
a
0
+
a
1
x
y=a_{0}+a_{1}x
y = a 0 + a 1 x
y
=
B
0
+
B
1
x
(
1
)
+
B
2
x
(
2
)
+
.
.
.
+
B
m
x
(
m
)
y=B_{0}+B_{1}x^{(1)}+B_{2}x^{(2)}+...+B_{m}x^{(m)}
y = B 0 + B 1 x ( 1 ) + B 2 x ( 2 ) + . . . + B m x ( m )
(x的上标代表变量的编号而不是次方)
对于多变量,可以引入线性方程组和矩阵的概念得到最优解。
列出线性方程组:
B
0
+
B
1
x
1
1
+
.
.
.
+
B
m
x
1
m
=
y
1
B_{0}+B_{1}x_{1}^1+...+B_{m}x_{1}^m=y_{1}
B 0 + B 1 x 1 1 + . . . + B m x 1 m = y 1
B
0
+
B
1
x
2
1
+
.
.
.
+
B
m
x
2
m
=
y
2
B_{0}+B_{1}x_{2}^1+...+B_{m}x_{2}^m=y_{2}
B 0 + B 1 x 2 1 + . . . + B m x 2 m = y 2
B
0
+
B
1
x
i
1
+
.
.
.
+
B
m
x
i
m
=
y
i
B_{0}+B_{1}x_{i}^1+...+B_{m}x_{i}^m=y_{i}
B 0 + B 1 x i 1 + . . . + B m x i m = y i
B
0
+
B
1
x
n
1
+
.
.
.
+
B
m
x
n
m
=
y
n
B_{0}+B_{1}x_{n}^1+...+B_{m}x_{n}^m=y_{n}
B 0 + B 1 x n 1 + . . . + B m x n m = y n
上式记为矩阵形式为:
[
1
x
1
1
…
x
n
1
1
x
1
2
…
x
n
1
…
…
…
…
1
x
n
m
…
x
n
m
]
[
B
0
B
1
…
B
m
]
=
[
y
1
y
2
…
y
n
]
\left[ \begin{array} {cccc} 1&x_1^1&\dots &x_n^1\\ 1&x_1^2&\dots &x_n^1\\ \dots&\dots&\dots &\dots\\ 1&x_n^m&\dots &x_n^m\\ \end{array} \right] \left[ \begin{array} {cccc} B_0\\ B_1\\ \dots\\ B_m\\ \end{array} \right]=\left[ \begin{array} {cccc} y_1\\ y_2\\ \dots\\ y_n\\ \end{array} \right]
⎣ ⎢ ⎢ ⎡ 1 1 … 1 x 1 1 x 1 2 … x n m … … … … x n 1 x n 1 … x n m ⎦ ⎥ ⎥ ⎤ ⎣ ⎢ ⎢ ⎡ B 0 B 1 … B m ⎦ ⎥ ⎥ ⎤ = ⎣ ⎢ ⎢ ⎡ y 1 y 2 … y n ⎦ ⎥ ⎥ ⎤
可以简化为:
A
⋅
B
=
Y
A\cdot B=Y
A ⋅ B = Y
最小二乘形式:
min
∥
A
B
−
Y
∥
2
\min \left \| AB-Y \right \|^2
min ∥ A B − Y ∥ 2
得到最终的最优解为:
B
^
=
(
A
T
A
)
−
1
A
T
Y
\hat B = (A^{T}A)^{-1}A^{T}Y
B ^ = ( A T A ) − 1 A T Y
多变量线性回归代价函数为:
J
(
θ
0
,
θ
1
,
…
,
θ
n
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
−
y
(
i
)
)
)
2
J(\theta_0,\theta_1,\dots,\theta_n)=\frac{1}{2m}\sum_{i=1}^m(h_{\theta}(x^{(i)}-y^{(i)}))^2
J ( θ 0 , θ 1 , … , θ n ) = 2 m 1 i = 1 ∑ m ( h θ ( x ( i ) − y ( i ) ) ) 2
h
θ
(
x
)
=
θ
T
X
=
θ
0
x
0
+
θ
1
x
1
+
⋯
+
θ
n
x
n
h_\theta(x)=\theta^TX=\theta_0x_0+\theta_1x1+\dots+\theta_nx_n
h θ ( x ) = θ T X = θ 0 x 0 + θ 1 x 1 + ⋯ + θ n x n
正规方程式通过求解下面的方程来找出使得代价函数最小的参数:
∂
∂
θ
j
j
(
θ
j
)
=
0
\frac{\partial }{\partial \theta_j}j(\theta_j)=0
∂ θ j ∂ j ( θ j ) = 0
设有m个训练实例,每个实例有n个特征,则训练实例集为:
X
=
[
x
0
1
…
x
n
1
…
…
…
x
0
m
…
x
n
m
]
X=\begin{bmatrix} x_0^{1} & \dots &x_n^{1} \\ \dots & \dots & \dots\\ x_0^{m}& \dots & x_n^{m} \end{bmatrix}
X = ⎣ ⎡ x 0 1 … x 0 m … … … x n 1 … x n m ⎦ ⎤
其中
x
j
(
i
)
x_j^{(i)}
x j ( i )
参数特征为:
θ
=
[
θ
0
,
θ
1
,
…
,
θ
n
]
T
\theta=[\theta_0,\theta_1,\dots,\theta_n]^T
θ = [ θ 0 , θ 1 , … , θ n ] T
故代价函数为:
J
(
θ
0
,
θ
1
,
…
,
θ
n
)
=
1
2
m
(
X
∗
θ
−
Y
)
T
(
X
∗
θ
−
Y
)
=
1
2
m
(
Y
T
Y
−
Y
T
X
θ
−
θ
T
X
T
Y
+
θ
T
X
T
X
θ
)
J(\theta_0,\theta_1,\dots,\theta_n)=\frac{1}{2m}(X*\theta-Y)^T(X*\theta-Y)=\frac{1}{2m}(Y^TY-Y^TX\theta-\theta^TX^TY+\theta^TX^TX\theta)
J ( θ 0 , θ 1 , … , θ n ) = 2 m 1 ( X ∗ θ − Y ) T ( X ∗ θ − Y ) = 2 m 1 ( Y T Y − Y T X θ − θ T X T Y + θ T X T X θ )
进行求导,等价于如下的形式:
1
2
m
(
∂
Y
T
Y
∂
θ
−
∂
Y
T
X
θ
∂
θ
−
∂
θ
T
X
T
Y
∂
θ
+
∂
θ
T
X
T
X
θ
∂
θ
)
\frac{1}{2m}(\frac{\partial Y^TY}{\partial \theta}-\frac{\partial Y^TX\theta}{\partial \theta}-\frac{\partial \theta^TX^TY}{\partial \theta}+\frac{\partial \theta^TX^TX\theta}{\partial \theta})
2 m 1 ( ∂ θ ∂ Y T Y − ∂ θ ∂ Y T X θ − ∂ θ ∂ θ T X T Y + ∂ θ ∂ θ T X T X θ )
其中第一项:
∂
Y
T
Y
∂
θ
=
0
\frac{\partial Y^TY}{\partial \theta}=0
∂ θ ∂ Y T Y = 0
第二项
Y
T
X
θ
=
[
y
(
1
)
,
y
(
2
)
,
…
,
y
(
m
)
]
X
=
[
x
0
1
…
x
n
1
…
…
…
x
0
m
…
x
n
m
]
[
θ
0
,
θ
1
,
…
,
θ
n
]
T
=
(
x
0
(
1
)
y
(
1
)
+
⋯
+
x
0
(
m
)
y
(
m
)
)
θ
0
+
(
x
1
(
1
)
y
(
1
)
+
⋯
+
x
1
(
m
)
y
(
m
)
)
θ
1
+
⋯
+
(
x
n
(
1
)
y
(
1
)
+
⋯
+
x
n
(
m
)
y
(
m
)
)
θ
n
Y^TX\theta=[y^{(1)},y^{(2)},\dots,y^{(m)}]X=\begin{bmatrix} x_0^{1} & \dots &x_n^{1} \\ \dots & \dots & \dots\\ x_0^{m}& \dots & x_n^{m} \end{bmatrix}[\theta_0,\theta_1,\dots,\theta_n]^T=(x_0^{(1)}y^{(1)}+\dots+x_0^{(m)}y^{(m)})\theta_0+(x_1^{(1)}y^{(1)}+\dots+x_1^{(m)}y^{(m)})\theta_1+\dots+(x_n^{(1)}y^{(1)}+\dots+x_n^{(m)}y^{(m)})\theta_n
Y T X θ = [ y ( 1 ) , y ( 2 ) , … , y ( m ) ] X = ⎣ ⎡ x 0 1 … x 0 m … … … x n 1 … x n m ⎦ ⎤ [ θ 0 , θ 1 , … , θ n ] T = ( x 0 ( 1 ) y ( 1 ) + ⋯ + x 0 ( m ) y ( m ) ) θ 0 + ( x 1 ( 1 ) y ( 1 ) + ⋯ + x 1 ( m ) y ( m ) ) θ 1 + ⋯ + ( x n ( 1 ) y ( 1 ) + ⋯ + x n ( m ) y ( m ) ) θ n
该矩阵求导,有:
∂
Y
T
X
θ
∂
θ
=
[
∂
Y
T
X
θ
∂
θ
0
…
∂
Y
T
X
θ
∂
θ
n
]
=
[
x
0
(
1
)
y
(
1
)
+
⋯
+
x
0
(
m
)
y
(
m
)
…
x
n
(
1
)
y
(
1
)
+
⋯
+
x
n
(
m
)
y
(
m
)
]
=
X
T
Y
\frac{\partial Y^TX\theta}{\partial \theta}=\begin{bmatrix} \frac{\partial Y^TX\theta}{\partial \theta_0}\\ \dots\\ \frac{\partial Y^TX\theta}{\partial \theta_n} \end{bmatrix}=\begin{bmatrix} x_0^{(1)}y^{(1)}+\dots+x_0^{(m)}y^{(m)}\\ \dots \\ x_n^{(1)}y^{(1)}+\dots+x_n^{(m)}y^{(m)} \end{bmatrix}=X^TY
∂ θ ∂ Y T X θ = ⎣ ⎢ ⎡ ∂ θ 0 ∂ Y T X θ … ∂ θ n ∂ Y T X θ ⎦ ⎥ ⎤ = ⎣ ⎢ ⎡ x 0 ( 1 ) y ( 1 ) + ⋯ + x 0 ( m ) y ( m ) … x n ( 1 ) y ( 1 ) + ⋯ + x n ( m ) y ( m ) ⎦ ⎥ ⎤ = X T Y
第三项:
θ
T
X
T
Y
=
[
θ
0
,
θ
1
,
…
,
θ
n
]
[
x
0
(
1
)
…
x
n
(
1
)
…
…
…
x
0
(
m
)
…
x
n
(
m
)
]
[
y
(
1
)
,
y
(
2
)
,
…
,
y
(
m
)
]
T
=
(
x
0
(
1
)
θ
0
+
⋯
+
x
n
(
1
)
θ
n
)
y
(
1
)
+
(
x
0
(
2
)
θ
0
+
⋯
+
x
n
(
2
)
θ
n
)
y
(
2
)
+
⋯
+
(
x
0
(
m
)
θ
0
+
⋯
+
x
n
(
m
)
θ
n
)
y
(
m
)
\theta^TX^TY=[\theta_0,\theta_1,\dots,\theta_n]\begin{bmatrix} x_0^{(1)} &\dots &x_n^{(1)} \\ \dots & \dots &\dots \\ x_0^{(m)} & \dots & x_n^{(m)} \end{bmatrix}[y^{(1)},y^{(2)},\dots,y^{(m)}]^T=(x_0^{(1)}\theta_0+\dots+x_n^{(1)}\theta_n)y^{(1)}+(x_0^{(2)}\theta_0+\dots+x_n^{(2)}\theta_n)y^{(2)}+\dots+(x_0^{(m)}\theta_0+\dots+x_n^{(m)}\theta_n)y^{(m)}
θ T X T Y = [ θ 0 , θ 1 , … , θ n ] ⎣ ⎢ ⎡ x 0 ( 1 ) … x 0 ( m ) … … … x n ( 1 ) … x n ( m ) ⎦ ⎥ ⎤ [ y ( 1 ) , y ( 2 ) , … , y ( m ) ] T = ( x 0 ( 1 ) θ 0 + ⋯ + x n ( 1 ) θ n ) y ( 1 ) + ( x 0 ( 2 ) θ 0 + ⋯ + x n ( 2 ) θ n ) y ( 2 ) + ⋯ + ( x 0 ( m ) θ 0 + ⋯ + x n ( m ) θ n ) y ( m )
求导得:
∂
θ
T
X
T
Y
∂
θ
=
[
∂
θ
T
X
T
Y
∂
θ
0
…
∂
θ
T
X
T
Y
∂
θ
n
]
=
[
x
0
(
1
)
y
(
1
)
+
⋯
+
x
0
(
m
)
y
(
m
)
…
x
n
(
1
)
y
(
1
)
+
⋯
+
x
n
(
m
)
y
(
m
)
]
=
X
T
Y
\frac{\partial \theta^TX^TY}{\partial \theta}=\begin{bmatrix} \frac{\partial \theta^TX^TY}{\partial \theta_0}\\ \dots\\ \frac{\partial \theta^TX^TY}{\partial \theta_n} \end{bmatrix}=\begin{bmatrix} x_0^{(1)}y^{(1)}+\dots+x_0^{(m)}y^{(m)}\\ \dots\\ x_n^{(1)}y^{(1)}+\dots+x_n^{(m)}y^{(m)} \end{bmatrix}=X^TY
∂ θ ∂ θ T X T Y = ⎣ ⎢ ⎡ ∂ θ 0 ∂ θ T X T Y … ∂ θ n ∂ θ T X T Y ⎦ ⎥ ⎤ = ⎣ ⎢ ⎡ x 0 ( 1 ) y ( 1 ) + ⋯ + x 0 ( m ) y ( m ) … x n ( 1 ) y ( 1 ) + ⋯ + x n ( m ) y ( m ) ⎦ ⎥ ⎤ = X T Y
第四项:
θ
T
X
T
X
=
(
X
T
X
)
(
θ
0
(
2
)
+
θ
1
(
2
)
+
⋯
+
θ
n
(
2
)
)
\theta^TX^TX=(X^TX)(\theta_0^{(2)}+\theta_1^{(2)}+\dots+\theta_n^{(2)})
θ T X T X = ( X T X ) ( θ 0 ( 2 ) + θ 1 ( 2 ) + ⋯ + θ n ( 2 ) )
其中
θ
T
X
T
X
\theta^TX^TX
θ T X T X
故求导得:
∂
θ
T
X
T
X
θ
∂
θ
=
[
∂
θ
T
X
T
X
θ
∂
θ
0
…
∂
θ
T
X
T
X
θ
∂
θ
n
]
=
2
(
X
T
X
)
[
θ
0
…
θ
n
]
=
2
X
T
X
θ
\frac{\partial \theta^TX^TX\theta}{\partial \theta}=\begin{bmatrix} \frac{\partial \theta^TX^TX\theta}{\partial \theta_0}\\ \dots \\ \frac{\partial \theta^TX^TX\theta}{\partial \theta_n} \end{bmatrix}=2(X^TX)\begin{bmatrix} \theta_0\\ \dots\\ \theta_n \end{bmatrix}=2X^TX\theta
∂ θ ∂ θ T X T X θ = ⎣ ⎢ ⎡ ∂ θ 0 ∂ θ T X T X θ … ∂ θ n ∂ θ T X T X θ ⎦ ⎥ ⎤ = 2 ( X T X ) ⎣ ⎡ θ 0 … θ n ⎦ ⎤ = 2 X T X θ
综上,正规方程为:
1
2
m
(
−
2
X
T
Y
+
2
X
T
X
θ
)
=
0
\frac{1}{2m}(-2X^TY+2X^TX\theta)=0
2 m 1 ( − 2 X T Y + 2 X T X θ ) = 0
最终可得特征参数的表示为:
θ
=
(
X
T
X
)
−
1
X
T
Y
\theta = (X^TX)^{-1}X^TY
θ = ( X T X ) − 1 X T Y
from numpy.linalg import inv
from numpy import dot,transpose
x=[[1,6,2],[1,8,1],[1,10,0],[1,14,2],[1,18,0]]
y=[[7],[9],[13],[17.5],[18]]
print(dot(inv(dot(transpose(x),x)),dot(transpose(x),y)))
[[1.1875 ]
梯度下降算法(批量梯度下降)也适用于求线性回归的拟合曲线,我们设拟合的曲线为:
h
θ
(
x
)
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
h_{\theta}(x)=\theta_{0}+\theta_{1}x_{1}+\theta_2x_2
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2
那么我们的误差函数设为:$ J(\theta)= \frac{1}{2}\sum_{i=1}m(h_{\theta}(x {i})-y{i}) 2 $,要求误差函数的极小值,我们引入了梯度下降算法的概念。
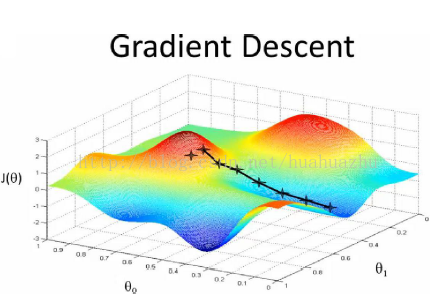
梯度下降原理:将函数比作一座山,我们站在某个山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快。
由之前所述,求θ系数的问题演变成了求J(θ)的极小值问题,这里使用梯度下降法。而梯度下降法中的梯度方向由J(θ)对θ的偏导数确定,由于求的是极小值,因此梯度方向是偏导数的反方向。
∂
∂
θ
i
J
(
θ
)
=
∂
∂
θ
i
1
2
(
h
θ
(
x
)
−
y
)
2
\frac{\partial }{\partial \theta_i}J(\theta)=\frac{\partial }{\partial \theta_i}\frac{1}{2}(h_\theta(x)-y)^2
∂ θ i ∂ J ( θ ) = ∂ θ i ∂ 2 1 ( h θ ( x ) − y ) 2
=
2
∗
1
2
(
h
θ
(
x
)
−
y
)
∂
∂
θ
i
(
h
θ
(
x
)
−
y
)
=2*\frac{1}{2}(h_\theta(x)-y)\frac{\partial }{\partial \theta_i}(h_\theta(x)-y)
= 2 ∗ 2 1 ( h θ ( x ) − y ) ∂ θ i ∂ ( h θ ( x ) − y )
=
(
h
θ
(
x
)
−
y
)
∂
∂
θ
i
(
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
⋯
+
θ
n
x
n
−
y
)
=(h_\theta(x)-y)\frac{\partial }{\partial \theta_i}(\theta_0+\theta_1x_1+\theta_2x_2+\dots+\theta_nx_n-y)
= ( h θ ( x ) − y ) ∂ θ i ∂ ( θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n − y )
θ
i
x
i
\theta_ix_i
θ i x i
所以,上式为:
=
(
h
θ
(
x
)
−
y
)
∂
∂
θ
i
θ
i
x
i
=(h_\theta(x)-y)\frac{\partial }{\partial \theta_i}\theta_ix_i
= ( h θ ( x ) − y ) ∂ θ i ∂ θ i x i
=
(
h
θ
(
x
)
−
y
)
x
i
=(h_\theta(x)-y)x_i
= ( h θ ( x ) − y ) x i
代入公式,最后可以得出关于
θ
\theta
θ
θ
i
=
θ
i
−
α
(
h
θ
(
x
)
−
y
)
x
i
\theta_i=\theta_i-\alpha(h_\theta(x)-y)x_i
θ i = θ i − α ( h θ ( x ) − y ) x i
=
θ
i
−
α
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
i
(
i
)
=\theta_i-\alpha \sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x_i^{(i)}
= θ i − α i = 1 ∑ m ( h θ ( x ( i ) ) − y ( i ) ) x i ( i )
使用梯度下降算法的步骤:
1)对θ赋初始值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得目标损失函数J(θ)按梯度下降的方向进行减少。$\theta=\theta-\alpha\frac{\partial J(\theta)}{\partial \theta} $
其中
α
\alpha
α
3)当下降的高度小于某个定义的值,则停止下降。
python语言实现:
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
# 构造训练数据
x = np.arange(0,10,0.2)
m=len(x)
x0 = np.full(m,1)
input_data = np.vstack([x0,x]).T
y= 2*x+5+np.random.randn(m)
plt.scatter(x,y)
plt.xlabel("x")
plt.ylabel("y")
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
plt.title("散点图")
plt.show()
#设置终止条件
loop_max = 10000
epsilon = 1e-3
count = 0 #循环次数
finish = 0 #终止次数
#初始权值theta
theta = np.random.randn(2)
error = np.zeros(2)
alpha = 0.001 # 学习速率
while count < loop_max:
count +=1
sum_m = np.zeros(2)
for i in range(m):
dif = (np.dot(theta,input_data[i])-y[i])*input_data[i]
sum_m = sum_m + dif # 当alpha取值过大时,sum_m会在迭代过程中溢出
theta = theta - alpha * sum_m #当alpha取值过大时,会导致振荡
#判断是否已经收敛
if np.linalg.norm(theta-error) < epsilon:
finish = 1
break
else:
error = theta
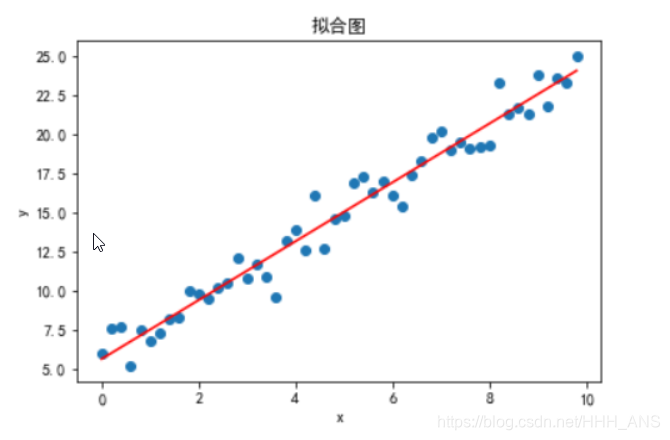
plt.scatter(x,y)
plt.plot(x,theta[1]*x+theta[0],'red')
plt.xlabel("x")
plt.ylabel("y")
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
plt.title("拟合图")
plt.show()