前两篇代码写了初始化与查询,知道了S函数,初始权重矩阵。以及神经网络的计算原理,总这一篇起就是最重要的神经网络的训练了。
神经网络的训练简单点来讲就是让输出的东西更加接近我们的预期。比如我们输出的想要是1,但是输出了-0.5,明显不是 我们想要的。
误差=(期望的数值)-(实际输出),那么我们的误差就是1.5。那么我们需要缩小这个差距,就需要让误差的变化形成的函数的值最小。
专业点来讲就是让损失函数的导数为0。那么首先我们需要知道我们的损失函数是一个什么样的函数。
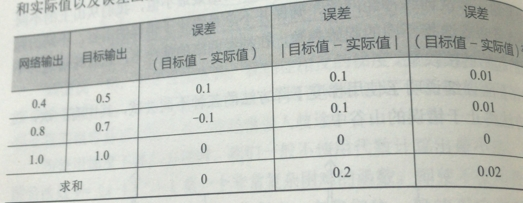
第一个候选就是(目标-实际),非常简单明了的,但是以此判断网络误差的时候,会出现误差为零,正负误差相抵消了。所以这个不好。
第二个候选的是 |目标-实际|,这意味着我们的可以无视符号,误差不能相抵消,可是由于在最小值附近的时候是一个V字形,所以到不了最小的值,只能左右徘徊,也不太好
第三个候选的是 (目标-实际)^2,二次函数是平滑连续的,求导容易计算,越接近最小值斜率越小,方便调节步长。
误差函数用来干什么呢?以后再讲
综上我们决定在这三个里面选择第三个损失函数,但是还有其他的复杂的又去的损失函数,可以自行探索。
现在我们知道我们的误差了。那么这个误差来自哪里呢?
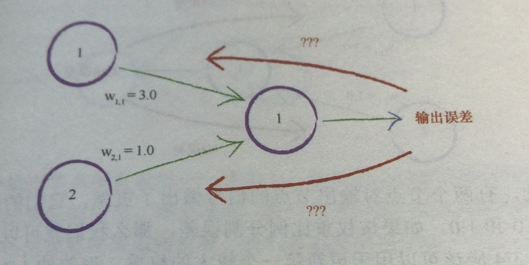
如图可以看到,我们的输出误差是由之前的数值和权重相乘导致的,那么我们的误差的来源应该是权重成正比的。
比如两个节点权重分别是3.0与1.0,那么我们输出误差的3/4应该分给权重大的节点,1/4分给权重小的节点。
然后我们把这个思想扩展到多个节点,如果我们隐藏层有100个节点,按照每条链接的权重的比例,相应分配输出的误差,
这个就是反向传播,BP(back propagation)。
隐藏层第一个节点的误差就是

我们假设输出的误差为0.8与0.5,重要的是计算过程,权重就随机吧。
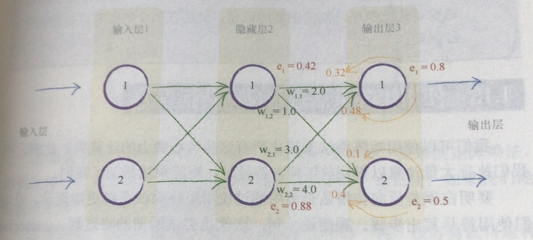
然后将这种反向传播到更前面的层。
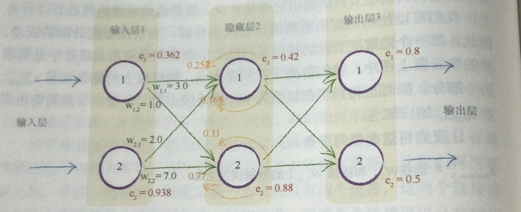
那么我们就从最后的输出一层一层,将前面所有的误差全都算出来。
可是很明显这种计算是十分费时费力的,这就有要用到我们的矩阵运算了。
首先是用输出的误差计算隐藏层的误差
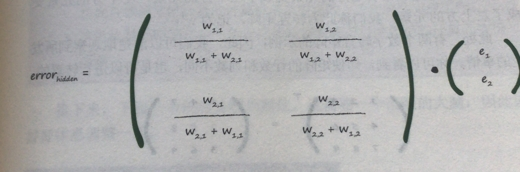
右边的e1,e2就是输出的误差。权重比例矩阵点乘输出的误差,新矩阵就是隐藏层的每个节点的误差的列矩阵了。
但是很明显分母太碍事了。而带上分母只是表示这一条链路的权重与相比于其他连在这个输出节点的链路上的占比,
简单一点的说法就是这个分母是用来标准化的。不看它,我们仅仅失去了后馈误差的大小(这里我没理解,我困扰了好久,为什么可以没有)
我们可以用简单容易的方法来辨认。
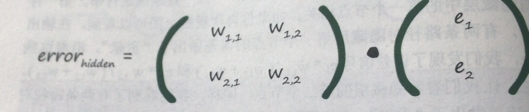
这和我们之前的权重矩阵与输入矩阵相乘感觉很相似
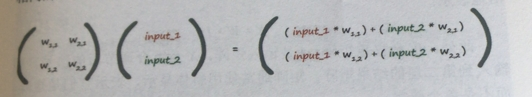
正好就是我们正向计算时候的权重矩阵的转置,也方便我们代码的书写
用简洁的写法写出来就是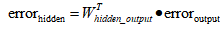
最后就是原代码中train函数的一部分的撰写。我们需要把我们的输入以及正确的结果(用来计算误差)来作为参数
前半部分和查询函数一样,就是计算给定输入对应输出的数值。然后反向计算各层各节点的误差。
#训练神经网络 def train(self,inputs_list,targets_list): #给函数输入列表以及正确的输出列表 inputs = np.array(inputs_list,ndmin=2).T #输入列表转成array数组并转置成列向量用来计算 targets = np.array(targets_list,ndmin=2).T #正确输出的列表转成array数组并转置成列向量用来计算 #计算隐藏层的输入 hidden_inputs = np.dot(self.wih,inputs) #计算隐藏层的输出,代入S函数 hidden_outputs = self.activation_function(hidden_inputs) #计算输出层的输入 final_inputs = np.dot(self.who,hidden_outputs) #计算输出层的输出,代入S函数 final_outputs = self.activation_function(final_inputs) #误差是(目标-实际) #(目标-实际)^2是误差函数,用来减小误差,而不是误差本身 output_errors = targets - final_outputs #隐藏层误差 hidden_errors = np.dot(self.who.T,output_errors) #权重函数转置矩阵点乘乘以输出误差矩阵 pass
可以看到我们辛辛苦苦讲了这么多的东西用,代码倒是没几行。尤其是那个计算各个节点的误差
只用了
#隐藏层误差 hidden_errors = numpy.dot(self.who.T,output_errors) #权重函数转置矩阵点乘乘以输出误差矩阵
就完成了,这里还是要特别说明一下,输入层是没有误差的,输入层只做输入!
迄今为止所有的代码

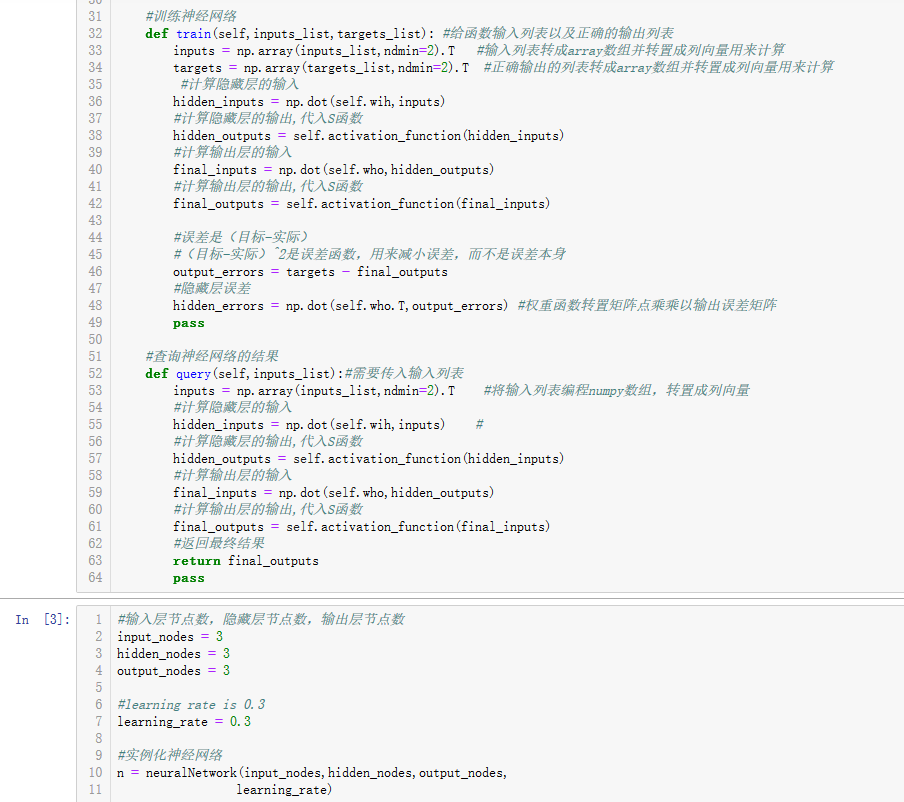
import numpy as np import scipy.special #神经网络类定义 class neuralNetwork: #初始化神经网络 def __init__(self,inputnodes,hiddennodes,outputnodes, learningrate): #设置的是输入层节点数,隐藏层节点数,输出层节点数 self.inodes = inputnodes self.hnodes = hiddennodes self.onodes = outputnodes #设置学习率 self.lr = learningrate #初始化权重函数 #初始化输入层到隐藏层的权重矩阵 # self.wih = np.random.rand(self.hnodes,self.inodes)-0.5 #-0.5为了能出现负数 # #初始化隐藏层到输出层的权重矩阵 # self.who = np.random.rand(self.onodes,self.hnodes)-0.5 #按照均值为0,标准方差为传入链接数的根号的倒数的正态分布的随机取样,获得更好的初始化权重 #初始化输入层到隐藏层的权重矩阵 self.wih = np.random.normal(0.0,pow(self.hnodes,-0.5),(self.hnodes,self.inodes))#pow就是标准方差的表示形式 #初始化隐藏层到输出层的权重矩阵 self.who = np.random.normal(0.0,pow(self.onodes,-0.5),(self.onodes,self.hnodes)) #设置激活函数 self.activation_function = lambda x:scipy.special.expit(x) pass #训练神经网络 def train(self,inputs_list,targets_list): #给函数输入列表以及正确的输出列表 inputs = np.array(inputs_list,ndmin=2).T #输入列表转成array数组并转置成列向量用来计算 targets = np.array(targets_list,ndmin=2).T #正确输出的列表转成array数组并转置成列向量用来计算 #计算隐藏层的输入 hidden_inputs = np.dot(self.wih,inputs) #计算隐藏层的输出,代入S函数 hidden_outputs = self.activation_function(hidden_inputs) #计算输出层的输入 final_inputs = np.dot(self.who,hidden_outputs) #计算输出层的输出,代入S函数 final_outputs = self.activation_function(final_inputs) #误差是(目标-实际) #(目标-实际)^2是误差函数,用来减小误差,而不是误差本身 output_errors = targets - final_outputs #隐藏层误差 hidden_errors = np.dot(self.who.T,output_errors) #权重函数转置矩阵点乘乘以输出误差矩阵 pass #查询神经网络的结果 def query(self,inputs_list):#需要传入输入列表 inputs = np.array(inputs_list,ndmin=2).T #将输入列表编程numpy数组,转置成列向量 #计算隐藏层的输入 hidden_inputs = np.dot(self.wih,inputs) # #计算隐藏层的输出,代入S函数 hidden_outputs = self.activation_function(hidden_inputs) #计算输出层的输入 final_inputs = np.dot(self.who,hidden_outputs) #计算输出层的输出,代入S函数 final_outputs = self.activation_function(final_inputs) #返回最终结果 return final_outputs pass #输入层节点数,隐藏层节点数,输出层节点数 input_nodes = 3 hidden_nodes = 3 output_nodes = 3 #learning rate is 0.3 learning_rate = 0.3 #实例化神经网络 n = neuralNetwork(input_nodes,hidden_nodes,output_nodes, learning_rate)