前言:JVM虚拟机是java程序运行平台,对于一个java程序是十分重要的。在运行时JVM虚拟机的类加载器将.class文件加载到虚拟机中转化为虚拟机的可运行文件运行,在现在的虚拟机中提供了一个HotSpot(热点探测)机制,频繁读取达到某个阈值的.class文件,会直接被以虚拟机可运行的文件存放在虚拟机中。JVM虚拟机中有两个可选机制版本client和server,clident机制为默认机制,如想更改JVM机制版本在jdk\jre\lib\i386\jvm.cfg文件中更改,将server KNOWN放在client KNOWN上即可。client机制一般运行于客户端应用,消耗较少的计算机资源;server机制一般用于服务端应用,消耗较多的计算机资源。
一:JVM的结构
1:JVM结构组成

(1)类加载子系统与方法区:类记载子系统负责从文件系统或网络中加载class信息,加载的类信息放在方法区中,方法区还会存放运行时的常量池信息,包括字符串和数字常量
(2)JAVA堆:java堆在虚拟机启动时建立,他是java程序最主要的内存工作区域,几乎所有的对象实例都存放在堆中。堆是所有线程共享的
(3)直接内存:java的NIO库允许java程序直接使用内存。直接内存是JAVA堆外的。直接向系统申请的内存空间。访问直接内存的速度一般会高于java堆。直接内存的大小不受JVM的限制,只要不高于物理内存就行。
(4)垃圾回收系统:垃圾回收系统是java虚拟机的重要组成部分,垃圾回收系统可以对方法区,java堆和直接内存进行回收。其中,java堆是垃圾收集器的工作重点。java的垃圾回收系统不同于C++,自动在后台工作,不需要手动控制。
(5)JAVA栈:每个java虚拟机线程都有一个私有的栈,一个线程的java栈在线程被创建时创建,java栈中保存着局部变量,方法参数,同时和java方法的调用,返回密切相关
(6)本地方法栈:本地方法栈用于本地方法的调用,java虚拟机允许java程序调用系统本地系统的本地方法。其他的和java栈类似。
(7)PC寄存器:每个线程的私有空间。在任何时刻,一个线程总在执行一个方法。这个正在被执行的方法称为当前方法。如果当前方法不是本地方法,PC寄存器就会指向当前正在被执行的指令。如果当前方法是本地方法,那么PC寄存器指向undefined
(8)执行引擎:执行引擎是JVM最核心的组件之一,它负责执行虚拟机的字节码,现代虚拟机为了提高执行效率,会使用即时编译技术将方法编译为机器码后执行。
2:JAVA堆的分代
(1)为什么要分代
堆内存是java虚拟机管理内存中最大的一块,也是垃圾回收系统回收最频繁的一段。为了方便垃圾回收和内存管理,引入了堆的分代,堆的分代以对象的生存时间为标准,将堆分为了新生代(年轻代),老年代和永久代。这样在一定程度上提高了垃圾回收的效率,而且尽可能减少了内存碎片的产生
(2)内存分代划分
java虚拟机将堆内存分为新生代(年轻代),老年代,永久代,永久代是HotSpot的特有概念,它采用永久代的方式实现方法区。而HotSpot也有去永久化的趋势,jdk1.7已经将字符串常量池从永久代移除。永久代主要存放常量,类信息,静态变量等数据,与垃圾回收关系不大。新生代和老年代是垃圾回收的主要区域,垃圾回收时以新生代和老年代之间为分界线使用不同的垃圾回收器,内存分代示意图如下:
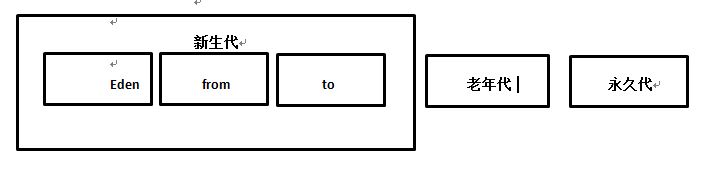
2-1:新生代(年轻代)
新生成的对象优先存放于新生代中,新生对象朝生夕死,存活率很低。常规进行一次垃圾回收,新生代会回收70%-95%的空间,回收效率很高
HotSpot将新生代划分为三块,一块较大的Eden区和两块较小的Survivor区(from区和to区),from有时被称为S0区,to有时被称为S1区,默认的比例为8:1:1。划分的目的是HotSpot以复制算法回收新生代。新创建的对象会保存在Eent中,大对象直接进入老年代。当Eent没有足够的空间进行分配时,虚拟机发起一次Minor GC,GC开始时候,to区域中是空的(每次都是),GC开始时,Eent区域中存活下来的对象会被复制到to中,from中对象的年龄值达到年龄阈值的(通常是15,对象每逃过一次GC,年龄值+1,GC分代年龄存放在对象的Header中),被复制到老年代中,没有达到阈值的被复制到to区中,然后清空Eden区和to区,from区和to区交换身份。现在to区便又为空,为下次GC提供空间。
2-2:老年代
在新生代中经历了多次GC后存活下来的对象会保存到老年代。老年代中的对象的生命周期较长,存活率比较高,在老年代中进行GC的频率相对较低,而且回收的速度也比较慢。
2-3:永久代
永久代存放类信息,常量,静态变量,即时编译器编译后的代码等数据没,对这一区域而言,一般而言不进行垃圾回收
二:JVM垃圾回收算法和收集器
1:垃圾回收常见算法
(1):引用计数
比较古老的回收算法,原理是此对象有一个引用,增加一个计数,删除一个引用则减少一个计数。垃圾回收时,回收计数为零的对象,此算法的缺点是无法处理循环引用问题
(2):复制
此算法把内存空间划分为两个相等的区域,每次只使用其中一个区域。垃圾回收时将正在使用的对象复制到另一个区域。此算法只处理正在使用的对象,因此复制成本低,而且复制时可以进行内存整理,不会出现内存碎片。缺点是需要两倍的内存空间
(3):标记-清除
此算法执行分两阶段,第一阶段从引用根节点开始标记所有被引用的对象,第二次遍历整个堆,把未标记对象的清除,此算法需要暂停整个应用,而且会产生内存碎片
(4):标记-整理
此算法执行分两阶段,第一阶段从引用根节点开始标记所有被引用的对象,第二次遍历整个堆,把未标记对象的清除,并吧存活对象压缩到堆的某一部分,此算法不会产生碎片,也不会浪费空间,结合了2,3的优点。
2:JVM中垃圾收集器
(1):Scavenge GC(次收集)和Full GC(全收集)的区别
新生代 GC(Scavenge GC || Minor GC):作用于新生代的GC,运行十分频繁,回收速度也比较快,当Eden空间不足以为对象分配空间时,会触发Scavenge GC。一般当Eent区为对象分配空间失败时,会触发Scavenge GC,对Eent区进行GC,清除非存活对象,将存活对象保存到Survivor区。然后整理Survivor两个区。Eent区的GC非常频繁,所以采用速度快,效率高的算法。
老年代 GC(Full GC || Major GC):发生在老年代的GC,GC时至少伴随一次Minor GC,Full GC比Minor GC慢十倍以上。当老年代内存不足,或调用System.gc()方法时,会触发Full GC。
次收集:
当新生带对堆空间紧张时会被触发,收集间隔较短
全收集:
老年堆或持久代空间满时会被触发,也可以使用System.gc()方法来启动
3:分代垃圾收集器

3-1:新生代(年轻代)收集器
(1)串行收集器(Serial)
Serial收集器是HotSpot运行在Client模式下的默认新生代收集器。使用复制算法,他的特点是只用以一个CPU/一条线程去完成工作,且在GC时必须要暂停其他所有的工作线程(STW,可以使用-XX:+UseSerialGC打开)。这一点通过安全点的触发和释放完成
(2)并行收集器(ParNew)
ParNew是前面Serial的多线程版本,除使用多条线程进行GC外,其他的控制参数,收集算法,对象分配规则,回收策略等和Serial完全相同(也是使用VM启用老年代CMS收集器-XX:useConMarkSweepGC的默认新生代收集器,useConMarkSweepGC收集器也可以与Serial收集器搭配使用),在单核处理器下的效率不一定高于单线程的Serial,而且多线程切换麻烦,所以可以通过XX:ParallelGCThreads=<N>参数控制参与GC的线程数量。减少了安全点的时间,即减少了用户线程等待的时间,从理论上垃圾收集线程可以与工作线程一同运行,但实际上并未完全实现这一点
(3)Parallel Scavenge收集器
与ParNew类似,Parallel Scavenge也是使用复制算法,也是并行多线程收集器,但是与其他收集器尽可能缩短垃圾收集时间不同,Parallet Scavenge收集器更关注系统吞吐量(系统吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间))。停顿时间越短越适用于用户交互的程序,良好的响应速度可以提高用户体验,而高吞吐量则适用于后台运算而不需要太多交互的任务,最高效率利用CPU时间。
Parallel Scavenge提供了如下参数设置系统吞吐量
| Parallel Scavenge收集器参数 | 描述 |
| -XX:MaxGCPauseMillis | (毫秒数)收集器将尽量保证内存回收时间不超过设定值,但如果太小会导致GC的频率增加 |
| -XX:GCTimeRatio | (整数:0<GCTimeRatio<100)是垃圾收集时间点 |
3-2:老年代收集器
(1)Serial Old收集器
Serial Old是Serial收集器的老年代版本,同样是单线程收集器,使用“标记-整理”算法(老年代没有Survivor区,无法使用复制算法)。可以与任何一个新生代收集器配合使用。
(2)Parallel Old 收集器
Parallel Old是Parallel Scavenge的老年代版本,使用多线程和“标记-整理”算法,吞吐量优先,主要与Parallel Scavenge配合使用。
(3)CMS收集器
CMS(Concurrent Mark Sweep)收集器是一款划时代的收集器,一枚真正意义上的并发收集器(不用暂停用户线程,用户线程和GC线程并行,称为并发)。虽然现在有理论上表现更好的G1收集器,但主流的互联网企业线上选用的仍然是CMS。CMS是一种以获取最短回收停顿时间为目标的收集器,CMS又称为多并发低暂停的收集器,基于“标记-清除”算法(CMS可以与Serial,ParNew新生代收集器配合使用,默认使用ParNew)大概分为以下四个步骤:1),3)需要暂停工作线程
1):初始标记(initlal mark)
2):并发标记(CMS Concurrent Mark:GC rootsTracing过程)
3):重新标记(CMS remark)
4):并发清除(CMS concurrent Sweep,死亡对象被就地释放。注意:此处没有压缩)
3-3:分区收集器-G1收集器
G1收集器是面向服务器端的收集器,主要目的是配备多核CPU的服务器治理大内存,G1收集器保留老年代,新生代,永久代的概念,但是不基于分代处理,而是将堆分为多个大小相等的独立区域。可用于整个堆的垃圾回收。
--xx:+UseG1GC 启用G1收集器
三:JVM的调优
1:JVM自带的监测小工具
(1)jps
用于查看JVM中所有进程的具体状态,包括进程的PID,程序路径等
jps -v //输出JVM参数
jps -q //输出JVM中各个线程的PID
jps -m //输出main方法的参数
jps -l //输出完全的包名,主类名,PID等

(2)jstat
监测资源和性能,监测JVM内存中各个区域的内存大小和使用量
结构:jstat [option] [pid] [time>] [count]
option //可选参数
time //间隔多长时间打印一次,单位毫秒
count //打印多少次,不写无限打印
option:
jstat -compiler [pid] //显示JVM实时编译的数量等信息
jstat -class [pid] //显示加载类的数量,和所占用的内存空间
jstat -gc [pid] //显示GC的信息,查看各区的分配大小和使用量
jstat -gcutil [pid] //统计GC信息
jstar -gccapacity [pid] //JVM中三代对象的内存使用和占用状态
jstat -printcompilation [pid] //当前JVM执行的信息

(3)jmap
可以获得JVM的堆中的详细信息,从而分析堆的运行状态
结构:
jmap [option] [pid]
参数:
jmap -heap [pid] //打印堆的信息。GC算法,内存大小和使用情况等
jmap -histo [pid] //打印堆的对象信息,包括内存大小等
jmap -histo:live [pid] //会先触发GC
jmap -finalizerinfo //打印等待回收的对象信息

(4)jstack
打印栈的详细信息,从而分析栈的运行状态
结构:jstack [option] [pid]
参数
jstack -F [pid] //当jstack -l [pid]没有响应时强制打印栈信息
jstack -l [pid] //长列表,打印锁的附加信息
jstack -h //打印帮助信息

(5)jconsole
监控java应用程序
jconsole [pid] //本地监控
jconsole [IP:port] //远程监控
远程监控需要配置jmx代理信息,如修改tomcat的bin目录下吃的catalina.bat文件
set JAVA_OPTS= %JAVA_OPTS% -Djava.rmi.server.hostname=HostIP
set JAVA_OPTS= %JAVA_OPTS% -Dcom.sun.management.jmxremote.port=8888
set JAVA_OPTS= %JAVA_OPTS% -Dcom.sun.management.jmxremote.ssl=false
set JAVA_OPTS= %JAVA_OPTS% -Dcom.sun.management.jmxremote.authenticate=false

(6)jvisualvm
jdk自带的图形话监测工具,可以使用插件,如Visual GC(专门用于监测垃圾回收系统的插件)


2:JVM参数介绍
参数的使用环境(多个参数用空格隔开):
(1)可以在eclipse中设置参数
run as->run configurations->选择运行的程序->arguments->VM arguments->run

(2)命令行中设置参数
![]()
(3)基于JVM的程序自带参数设置,如Tomcat
Tomcat默认可以使用的内存为128MB。
Windows下,在文件/bin/catalina.bat中,在rem Guess CATALINA_HOME if not definedset CURRENT_DIR=%cd%后面添加JVM参数
Unix下,在文件/bin/catalina.sh中,在文件头部设置JVM参数
配置大概如下:
JAVA_OPTS="-Xms50m -Xmx100m -XX:ParallelGCThreads=8"
2:一些参数
-Xms //初始堆大小,如-Xms10m
-Xmx //最大堆大小,如-Xmx100m
-XX:NewSize=n //设置新生代大小
-XX:MaxPermSize=n //设置持久代大小
-XX:NewRatio=n //年轻代和老年代的比值
-XX:SurvivorRatio=n //Eden区和Survivor区的比值
XX:+UseSerialGC //设置串行收集器
-XX:+UseParallelGC //设置并行收集器
-XX:+UseParalledlOldGC //设置并行年老代收集器
-XX:+UseConcMarkSweepGC //设置并发收集器
等等等等。。。。。
官方英文文档:http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html
非官网中文文档:http://www.jvmer.com/jvm-xx-%E5%8F%82%E6%95%B0%E4%BB%8B%E7%BB%8D/