数据集:
使用吴恩达机器学习课程:https://study.163.com/course/courseMain.htm?courseId=1004570029
章节8中的课时60:编程作业:Logistic回归的资料中的数据集ex2data1.txt(训练集)和ex2data2.txt(测试集),下载地址:

我们的任务是:根据测试集学生已知的两次考试成绩和最后的录取结果训练一个模型,然后判断测试集中的学生样本是否会被录取。
搭建第一个逻辑回归(logistic regression,也就是单层感知机)模型:
感知器:
感知器神经网络是一种典型的前馈神经网络,具有分层结果,信息丛输入层进入网络,逐层向前传递至输出层。根据感知器神经元转移函数、隐层数以及权值调整规则的不同,可以形成具有各种功能特点的神经网络。
单层感知器:
一种具有单层计算单元的神经网络,即感知器(Perceptron)。如果包括输入层在内,应为两层,即输入层和输出层。单层感知器的结构和功能非常简单,以至于目前在解决实际问题时很少被采用,但由于它是神经网络的基础,适合作为神经网络学习的起点。
单层感知器的结构:
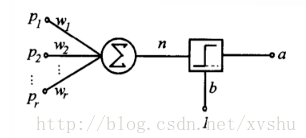
我们可以发现,logistic regression函数实际上就是一个最简单的单层感知器。
当然,单层感知器还可以有其他形式,如:
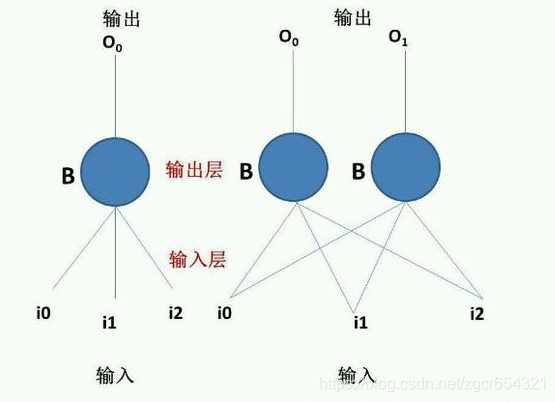
左边是一个单层单输出感知器,右边是一个单层多输出感知器。
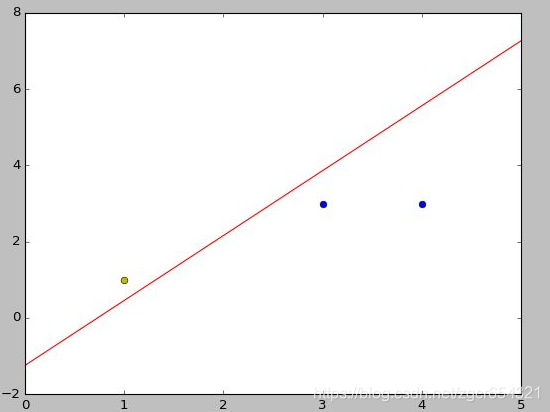
单层感知器有一个缺点,即它们只能对线性可分的数据集进行分类。
比如下面这样的数据可以被单层感知器区分:
建立logistic regression(即单层感知机)模型:
我们将ex2data1.txt和ex2data2.txt与我们的模型的.py文件放到同一目录下。
首先处理训练数据集,将训练数据集的x数据规整为shape=(100,2)的数组,y数据规整为shape=(100,1)的数组;
定义取得w和b变量的函数;
对x数据进行z_score标准化,否则进行sigmoid计算时数据会溢出;
定义X和Y占位符,用于将输入的x和y数据转化相应shape的张量;
定义w和b变量,定义logistic regression函数;
新建一个训练对话,迭代训练20000次;
处理测试数据集的数据,方法同对训练数据集一样,并对测试数据集的x数据进行z_score标准化;
新建一个测试对话,计算测试的准确率并输出。
占位符placeholder:
即动态分配了一块“空间”出来给placeholder类型的变量,空间指定了其内容的大小和类型,而里面填充什么内容需要经过之后的处理才知道。
Feed--Fetch机制:
feed使用一个tensor值临时替换一个操作的输出结果。通俗地说,就是把神经网络的结构与数据分开。对于一个节点,我们可以事先通过placeholder开辟一块空间,然后在session中给它“喂”数据。使用的方法是Python的字典。方法结束后feed就会消失。
代码如下:
import tensorflow as tf
from math import sqrt, pow
import csv
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
train_x_data_set = []
train_y_data_set = []
# 从ex2data1.txt中提取出用于train的x数据集和y数据集
with open('ex2data1.txt', 'r', encoding='UTF-8', errors='ignore') as csv_file:
all_lines = csv.reader(csv_file)
# 遍历train.csv的所有行
for one_line in all_lines:
one_line_x_data = []
one_line_y_data = []
for i, element in enumerate(one_line):
# 去除字符串首尾的空格
element = element.strip()
if i == 2:
one_line_y_data.append(float(element))
else:
one_line_x_data.append(float(element))
train_x_data_set.append(one_line_x_data)
train_y_data_set.append(one_line_y_data)
# 得到的train_x_data_set的shape为(100,2),train_y_data_set的shape为(100,1)
# 测试
# print(train_x_data_set)
# print(train_y_data_set)
# 定义weight变量
def weight_variable(shape):
inital = tf.truncated_normal(shape, stddev=0.1)
# tf.truncated_normal(shape, mean, stddev)函数从截断的正态分布中输出随机值。均值和标准差自己设定。
return tf.Variable(inital)
# 定义bias变量
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
# 对数据作z_score标准化处理,直接计算时sigmoid函数计算会溢出
def data_z_score_standardization(x_data_set):
# 对x_data_set中所有的数据都进行归一化
for index in range(len(x_data_set[0])):
# 取出需要归一化的一组数据
data_list = []
for one_data in x_data_set:
data_list.append(one_data[index])
# 计算这组数据的平均值
data_mean = 0.0
for data in data_list:
data_mean = data_mean + data
data_mean = data_mean / len(data_list)
# 计算这组数据的方差
data_variance = 0.0
for data in data_list:
data_variance = data_variance + pow((data - data_mean), 2)
data_variance = data_variance / len(data_list)
# 计算这组数据的标准差
data_standard_deviation = sqrt(data_variance)
# 将train_x_data_set的相关数据标准化
for subscript, one_data in enumerate(x_data_set):
x_data_set[subscript][index] = (one_data[index] - data_mean) / data_standard_deviation
return x_data_set
# 对train_x_data_set做z_score标准化
train_x_data_set = data_z_score_standardization(train_x_data_set)
# 用X和Y占位符来传输训练集的x数据和y数据(把输入的数据变成指定shape的张量)
X = tf.placeholder(tf.float32, [None, 2])
Y = tf.placeholder(tf.float32, [None, 1])
iteration = 20000
# 生成w和b,计算y_pred
w_train = tf.Variable(weight_variable([2, 1]))
b_train = tf.Variable(bias_variable([1]))
y_pred = 1 / (1 + tf.exp(-(tf.matmul(X, w_train) + b_train)))
cross_entropy = tf.reduce_mean(- tf.reduce_sum((Y * tf.log(y_pred) + (1 - Y) * tf.log(1 - y_pred)), 1))
optimizer = tf.train.GradientDescentOptimizer(0.005).minimize(cross_entropy)
saver = tf.train.Saver(max_to_keep=5)
# 创建保存模型的路径
if not os.path.exists("./tmp/"):
os.mkdir("./tmp")
with tf.Session() as sess_train:
sess_train.run(tf.global_variables_initializer())
if os.path.exists("./tmp/checkpoint"):
# 判断模型是否存在,如果存在则从模型中恢复变量
saver.restore(sess_train, tf.train.latest_checkpoint('./tmp/'))
for i in range(iteration):
# 注意feed_dict不接受tensor张量,但可以是np的数列或python的列表等
_, loss = sess_train.run([optimizer, cross_entropy],
feed_dict={X: train_x_data_set, Y: train_y_data_set})
w, b = sess_train.run([w_train, b_train], feed_dict={X: train_x_data_set, Y: train_y_data_set})
w, b = w.flatten(), b.flatten()
if i % 20 == 0:
print("iteration:{} loss值:{} w值:{} b值:{}".format(i, loss, w, b))
if i % 100 == 0:
saver.save(sess_train, "./tmp/train_model", global_step=i)
if loss <= 0.205:
break
test_x_data_set = []
test_y_data_set = []
# 从ex2data1.txt中提取出用于train的x数据集和y数据集
with open('ex2data2.txt', 'r', encoding='UTF-8', errors='ignore') as csv_file:
all_lines = csv.reader(csv_file)
# 遍历train.csv的所有行
for one_line in all_lines:
one_line_x_data = []
one_line_y_data = []
for i, element in enumerate(one_line):
# 去除字符串首尾的空格
element = element.strip()
if i == 2:
one_line_y_data.append(float(element))
else:
one_line_x_data.append(float(element))
test_x_data_set.append(one_line_x_data)
test_y_data_set.append(one_line_y_data)
# 得到的test_x_data_set的shape为(100,2),test_y_data_set的shape为(100,1)
# 对test_x_data_set做z_score标准化
test_x_data_set = data_z_score_standardization(test_x_data_set)
with tf.Session() as sess_test:
sess_test.run(tf.global_variables_initializer())
if os.path.exists("./tmp/checkpoint"):
# 直接恢复成训练好的模型,然后开始测试
saver.restore(sess_test, tf.train.latest_checkpoint('./tmp/'))
y_out, y_true, loss = sess_test.run([y_pred, Y, cross_entropy], feed_dict={X: test_x_data_set, Y: test_y_data_set})
# 生成的y_out是shape=(test样本数量,1)的np数组,每个元素在(0,1)之间
# 我们判断数组中每个元素的值,如果大于等于0.5,则y_out对应值是1.0(类1),否则是0.0(类0)
for i in range(len(y_out)):
if y_out[i][0] >= 0.5:
y_out[i][0] = 1.0
else:
y_out[i][0] = 0.0
# 将修改好的列表重新转为张量y_prediction
for i in range(len(y_out)):
print("第{}个样本的预测标签为:{} 真实标签为:{}".format(i, y_out[i][0], y_true[i][0]))
y_prediction = tf.reshape(y_out, [-1, 1])
# 判断张量y_prediction和Y对应元素是否相等,相等则返回True,否则返回False,correct_pre是一个shape=(100,1)的张量
# 该张量中元素值要么是True,要么是False
correct_pre = tf.equal(y_prediction, Y)
# cast函数会将correct_pre张量中元素值为True的变为值1,元素值为False的变为值0,然后求平均值,就是准确率
accuracy = tf.reduce_mean(tf.cast(correct_pre, tf.float32))
acc = sess_test.run(accuracy, feed_dict={X: test_x_data_set, Y: test_y_data_set})
print("测试集loss值为:{} 准确率为:{}".format(loss, acc))运行结果如下:
训练过程就不放了,最后训练到loss值小于0.205停止,然后开始测试数据:
第0个样本的预测标签为:1.0 真实标签为:1.0
第1个样本的预测标签为:1.0 真实标签为:1.0
第2个样本的预测标签为:1.0 真实标签为:1.0
第3个样本的预测标签为:1.0 真实标签为:1.0
第4个样本的预测标签为:0.0 真实标签为:1.0
第5个样本的预测标签为:0.0 真实标签为:1.0
第6个样本的预测标签为:0.0 真实标签为:1.0
第7个样本的预测标签为:0.0 真实标签为:1.0
第8个样本的预测标签为:0.0 真实标签为:1.0
第9个样本的预测标签为:0.0 真实标签为:1.0
第10个样本的预测标签为:0.0 真实标签为:1.0
第11个样本的预测标签为:1.0 真实标签为:1.0
第12个样本的预测标签为:1.0 真实标签为:1.0
第13个样本的预测标签为:1.0 真实标签为:1.0
第14个样本的预测标签为:1.0 真实标签为:1.0
第15个样本的预测标签为:1.0 真实标签为:1.0
第16个样本的预测标签为:1.0 真实标签为:1.0
第17个样本的预测标签为:1.0 真实标签为:1.0
第18个样本的预测标签为:1.0 真实标签为:1.0
第19个样本的预测标签为:1.0 真实标签为:1.0
第20个样本的预测标签为:0.0 真实标签为:1.0
第21个样本的预测标签为:0.0 真实标签为:1.0
第22个样本的预测标签为:0.0 真实标签为:1.0
第23个样本的预测标签为:0.0 真实标签为:1.0
第24个样本的预测标签为:0.0 真实标签为:1.0
第25个样本的预测标签为:0.0 真实标签为:1.0
第26个样本的预测标签为:0.0 真实标签为:1.0
第27个样本的预测标签为:1.0 真实标签为:1.0
第28个样本的预测标签为:1.0 真实标签为:1.0
第29个样本的预测标签为:1.0 真实标签为:1.0
第30个样本的预测标签为:1.0 真实标签为:1.0
第31个样本的预测标签为:1.0 真实标签为:1.0
第32个样本的预测标签为:1.0 真实标签为:1.0
第33个样本的预测标签为:1.0 真实标签为:1.0
第34个样本的预测标签为:0.0 真实标签为:1.0
第35个样本的预测标签为:0.0 真实标签为:1.0
第36个样本的预测标签为:0.0 真实标签为:1.0
第37个样本的预测标签为:0.0 真实标签为:1.0
第38个样本的预测标签为:0.0 真实标签为:1.0
第39个样本的预测标签为:0.0 真实标签为:1.0
第40个样本的预测标签为:1.0 真实标签为:1.0
第41个样本的预测标签为:1.0 真实标签为:1.0
第42个样本的预测标签为:1.0 真实标签为:1.0
第43个样本的预测标签为:1.0 真实标签为:1.0
第44个样本的预测标签为:1.0 真实标签为:1.0
第45个样本的预测标签为:1.0 真实标签为:1.0
第46个样本的预测标签为:1.0 真实标签为:1.0
第47个样本的预测标签为:1.0 真实标签为:1.0
第48个样本的预测标签为:1.0 真实标签为:1.0
第49个样本的预测标签为:1.0 真实标签为:1.0
第50个样本的预测标签为:1.0 真实标签为:1.0
第51个样本的预测标签为:1.0 真实标签为:1.0
第52个样本的预测标签为:1.0 真实标签为:1.0
第53个样本的预测标签为:1.0 真实标签为:1.0
第54个样本的预测标签为:0.0 真实标签为:1.0
第55个样本的预测标签为:0.0 真实标签为:1.0
第56个样本的预测标签为:0.0 真实标签为:1.0
第57个样本的预测标签为:0.0 真实标签为:1.0
第58个样本的预测标签为:1.0 真实标签为:0.0
第59个样本的预测标签为:1.0 真实标签为:0.0
第60个样本的预测标签为:1.0 真实标签为:0.0
第61个样本的预测标签为:1.0 真实标签为:0.0
第62个样本的预测标签为:1.0 真实标签为:0.0
第63个样本的预测标签为:1.0 真实标签为:0.0
第64个样本的预测标签为:1.0 真实标签为:0.0
第65个样本的预测标签为:1.0 真实标签为:0.0
第66个样本的预测标签为:1.0 真实标签为:0.0
第67个样本的预测标签为:1.0 真实标签为:0.0
第68个样本的预测标签为:1.0 真实标签为:0.0
第69个样本的预测标签为:1.0 真实标签为:0.0
第70个样本的预测标签为:1.0 真实标签为:0.0
第71个样本的预测标签为:1.0 真实标签为:0.0
第72个样本的预测标签为:1.0 真实标签为:0.0
第73个样本的预测标签为:1.0 真实标签为:0.0
第74个样本的预测标签为:0.0 真实标签为:0.0
第75个样本的预测标签为:0.0 真实标签为:0.0
第76个样本的预测标签为:1.0 真实标签为:0.0
第77个样本的预测标签为:0.0 真实标签为:0.0
第78个样本的预测标签为:0.0 真实标签为:0.0
第79个样本的预测标签为:0.0 真实标签为:0.0
第80个样本的预测标签为:0.0 真实标签为:0.0
第81个样本的预测标签为:0.0 真实标签为:0.0
第82个样本的预测标签为:0.0 真实标签为:0.0
第83个样本的预测标签为:0.0 真实标签为:0.0
第84个样本的预测标签为:0.0 真实标签为:0.0
第85个样本的预测标签为:0.0 真实标签为:0.0
第86个样本的预测标签为:0.0 真实标签为:0.0
第87个样本的预测标签为:0.0 真实标签为:0.0
第88个样本的预测标签为:1.0 真实标签为:0.0
第89个样本的预测标签为:1.0 真实标签为:0.0
第90个样本的预测标签为:1.0 真实标签为:0.0
第91个样本的预测标签为:1.0 真实标签为:0.0
第92个样本的预测标签为:1.0 真实标签为:0.0
第93个样本的预测标签为:1.0 真实标签为:0.0
第94个样本的预测标签为:1.0 真实标签为:0.0
第95个样本的预测标签为:1.0 真实标签为:0.0
第96个样本的预测标签为:1.0 真实标签为:0.0
第97个样本的预测标签为:1.0 真实标签为:0.0
第98个样本的预测标签为:1.0 真实标签为:0.0
第99个样本的预测标签为:1.0 真实标签为:0.0
第100个样本的预测标签为:1.0 真实标签为:0.0
第101个样本的预测标签为:1.0 真实标签为:0.0
第102个样本的预测标签为:0.0 真实标签为:0.0
第103个样本的预测标签为:0.0 真实标签为:0.0
第104个样本的预测标签为:0.0 真实标签为:0.0
第105个样本的预测标签为:0.0 真实标签为:0.0
第106个样本的预测标签为:0.0 真实标签为:0.0
第107个样本的预测标签为:0.0 真实标签为:0.0
第108个样本的预测标签为:0.0 真实标签为:0.0
第109个样本的预测标签为:0.0 真实标签为:0.0
第110个样本的预测标签为:0.0 真实标签为:0.0
第111个样本的预测标签为:0.0 真实标签为:0.0
第112个样本的预测标签为:0.0 真实标签为:0.0
第113个样本的预测标签为:0.0 真实标签为:0.0
第114个样本的预测标签为:0.0 真实标签为:0.0
第115个样本的预测标签为:1.0 真实标签为:0.0
第116个样本的预测标签为:1.0 真实标签为:0.0
第117个样本的预测标签为:1.0 真实标签为:0.0
测试集loss值为:2.23197078704834 准确率为:0.508474588394165
Process finished with exit code 0我们可以发现准确率非常低,和蒙差不多。这是因为这组数据集的数据分布的非常均匀,无法用线性函数区分,而单层感知器只能用来区分线性可分的数据。因此这个数据集我们应该用更加复杂的神经网络结构来进行预测。