8.1 目标任务
1.用jieba库实现中文词性标注
2.用SnoeNLP库实现中文词性标注
8.2 实验数据
novel.txt

8.3 实验过程
8.3.1 实验准备
1.安装jieba库:
pip install jiebajieba库繁体分词和自定义词典,它支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析
全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
下载地址:https://pypi.python.org/pyp/jieba
2.安装SnowNLP库:
pip install snownlpSnowNLP受到了TextBlob的启发而撰写的中文处理python类库,自带一些训练好的字典。可完成中文分词、词性标注、情感分析、文本分类、文字转拼音、繁体转简体、提取文本关键词、提取文本摘要等功能。
下载地址:https://github.com/isnowfy/snownlp
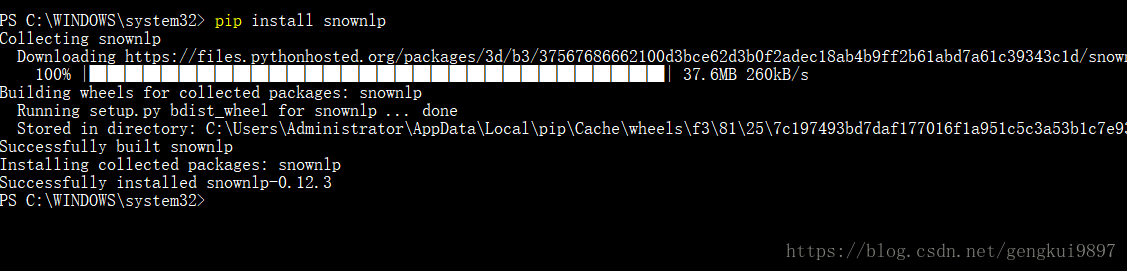
3.安装nlth库:
pip install nltk自然语言工具包(nltk)是用于处理自然语言语法及语义分析的python库,它提供超过50个语料库和词典资源,文本处理库包括分类、分词、词干提取、解析、语义推理。
下载地址:https://pypi.python.org/pypi/nltk
如果使用的anaconda安装的python,则已经自动导入了nltk,只需下载数据包到python安装目录即可。


8.3.2 数据的输入输出
将输入数据文件放到自己指定的目录下,输出即可在命令行,也可输出到txt文件查看。
8.3.3 实验步骤
实验一、使用jieba进行中文词性标注
1.导入jieba库
将工作路径切换到python安装目录,输入pip2 install jieba,等待下载安装即可。
2.导入成功后将工作路径切换到数据文件所在目录
进入python环境,输入以下命令:
import jieba
import jieba.posseg
filein = open('./novel.txt','r')
str = filein.read()
seg = jieba.posseg.cut(str)
l = []
for i in seg:
l.append((i.word,i.flag))
print l实现分词:

可将分词结果输出到文件:
import jieba
import jieba.posseg
filein = open('./novel.txt','r')
str = filein.read()
seg = jieba.posseg.cut(str)
fout = open('novel_out.txt','w')
for i in seg:
s = i.word+'\t'+i.flag+'\n'
fout.writelines(s.encode('utf-8'))
fout.close()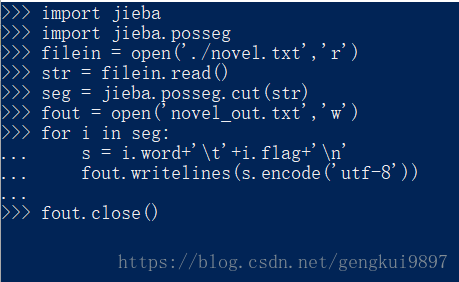

实验二、使用SnowNLP进行中文分词
1.导入SnoeNLP库
2.进入python环境,输入以下代码:
from snownlp import SnowNLP
fin = open('novel.txt','r')
str = fin.read()
str = str.decode('utf-8')
s = SnowNLP(str)
fout = open('novel_out_snownlp.txt','w')
for i in s.tags:
s = i[0]+'\t'+i[1]+'\n'
fout.writelines(s.encode('utf-8'))
fout.close()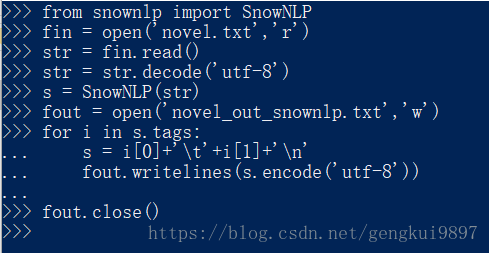

8.4 结果分析
尽管都采用HMM模型,可以发现两个库对相同文件的分词结果略有差异,在对空格等细节的处理上也不同。这应该与使用了不同的训练数据和不同的词库有关。