连接数据库的步骤
我在网上看到的一个教程,感觉那个老师总结的特别好,他是引用<红楼梦>中的人物,将连接数据库的步骤进行了总结。
“贾琏欲执事”
贾:加载注册驱动。
琏:连接数据库
欲:获取预编译语句对象
执:执行预编译语句
事:释放资源
导入jar包
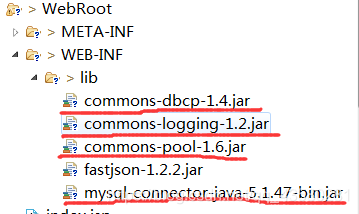
红线标注的就是导入的jar包,jar包可以直接去官网下载,下载完之后,直接复制到web-inf下的lib下就行。commons-pool-1.6.jar是连接池的jar包。
新学者可以先不用连接池
(这是注册用户时用到的代码,主要是sql语句不一样,就可以实现不同的功能)
//1.加载注册驱动
Class.forName("com.mysql.jdbc.Driver");
//2.连接数据库 建立连接
//url: jdbc:mysql://主机地址:端口号/数据库
//user:数据库的用户名
//pwd:密码
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/user","root","123456");
//3.创建sql语句
String sql = "insert into user(Name,Password)values('"+user+"','"+pwd+"')";
//4.创建一个statement对象
Statement st = conn.createStatement();
//5.执行插入sql
int rs = st.executeUpdate(sql);
System.out.println(rs);
//6.关闭连接 释放资源
st.close();
conn.close();
使用连接池,使用配置文件连接数据库
为什么使用配置文件?
其实这里也用到了封装的思想,就是减少代码的耦合性。使用配置文件的好处:举个例子,当你在北京的一个公司上班,你把一个项目买到了新疆(意思就是很远的地方)。由于买方需要重新建立数据库,或者用自己公司的数据库,那么数据库名,密码什么的也就不一样了。如果买方懂编程还好,你可以告诉他改那一包下面的代码。但是,在公司的忌讳是严禁看源码的,这里涉及到知识产权的问题。所以就假设买方不懂源码。假设能看你的源码,你也不能让它改啊,因为他根本看不懂,再改到其他地方,那你的代码离崩溃也不远。这里就配置文件就解决了这个尴尬的问题。
在src下右键new->folder(相当于文件夹)把数据库配置问件放在下面。因为以后如果开发大型项目,不可能只有一个配置文件,这是便于管理配置文件。

这里我用的是db.properties,后缀是properties就是配置文件。配置文件的底层用的也是hashmap就是一个key,一个value。
对创键好的配置文件进行设置
#key=values格式
#连接数据库的四要素
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/jdbcdemo(数据库名称)
username=root(数据名)
password=123456(密码)
读取配置文件里的内容,获取连接对象,关闭连接
一般加载注册驱动只需要加载注册一次就行了,这样我们就想到静态代码块。只需要在程序启动是加载一次就行了。读取配置文件中的内容,我们想到了反射,只需要一个全限定名称就可以获取配置文件类,获取到里面的字段属性和方法。
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.commons.dbcp.BasicDataSourceFactory;
public class DBUtil {
private static Properties p = new Properties();//获取配置文件对象
private static DataSource ds = null;//数据源对象为null
// 1.加载注册驱动
static {
// 获取配置文件,转换成一个输入流
try {
p.load(Thread.currentThread().getContextClassLoader().getResourceAsStream("db.properties"));//从配置文件中读取配置信息
// 获取数据源对象
ds = BasicDataSourceFactory.createDataSource(p);//这是从连接池中获取连接对象
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
// 2.获取连接对象
public static Connection getConn() {
Connection conn = null;
try {
conn = ds.getConnection();//获取连接对象
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return conn;//返回连接对象
}
// 3.关闭连接
public static void clossAll(Connection conn, Statement st, ResultSet rs) {
//关闭连接遵循先开的最后关闭,不过关之前先看看是否为null,如果为null,就不需要关闭
try {
if (rs != null) {
rs.close();
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
if (st != null) {
st.close();
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
if (conn != null) {
conn.close();
}
} catch (Exception e2) {
// TODO: handle exception
}
}
}
}
}
总结
为什么使用连接池?使用连接池的好处?
直接举个例子,如果你的家在河的一边,你的外婆家在河的另一边。假设没有交通工具可以过河,你只能通过架设一个桥来到你的外婆家去。没使用连接池之前,相当于每连接一个数据库你就架设了一个桥,当你到达河的对面,也就是对数据库的操作(增,删,查,改操作),你关闭数据库连接就相当于把桥销毁了。当你再次过河时还要重新架桥。这样就大大增加了cpu的工作量,效率会大大降低。所以,连接池就应运而生。连接池主要思路是,先给你建好几个连接对象,当你使用完毕,它没有销毁,只是返回给连接池,让你下次方便使用。所以这里使用连接池,可以大大增加效率。