去掉相同的主体部分,从而突出微小的变化,我们明确地将这些层重新定义为根据参考层的输入来学习残差函数,而不是学习无参考的函数
问题提出
learning better networks as easy as stacking more layers?
- 第一个问题:梯度消失/爆炸 解决方案:标准初始化,中间层标准化
- 网络退化问题:随着网络深度增加,准确度变饱和,迅速退化,本文引出残差网络解决
解决上述第二个问题的极端情况:基于一个浅层网络构建堆积深层网络,其中堆积层没有学习能力,只是将浅层的网络特征进行复制传递,即恒等映射(identity mapping)
- 对于多层结构,输入为x,网络学习到的特征为H(x),即为输出,两者的差称为残差
- 即此堆层结构学习到的特征提取函数为F(x) = H(x) - x,
- 此网络学习到的特征为h(x) = F(x) + x,便得到如下残差网络结构
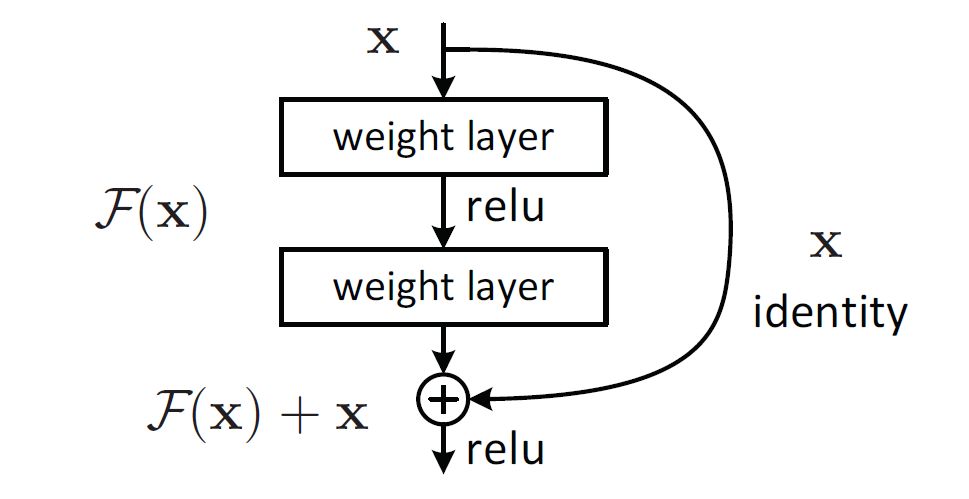
当残差F(x)=0时,为恒等映射,网络的性能不会因层数增加而下降,但实际上残差不会为0,一般残差较小,学习内容少,学习难度也就变小,
- 极端:H(x)-x = 0
- 残差情况: H(x)-x=F(x)
残差单元公式:
根据链式规则:有到层的传递过程为:
其中大括号内的第一项1代表短路机制无损传递函数,不会让梯度消失。
网络结构
- 基于VGG19,利用strid=2的卷积替换pooling,global average pool替换全连接
- 重要原则:当feature map size降低一半,数量要增加一倍,保持复杂度,虚线表示
总结
为什么拟合残差更加容易?
- 比如把5映射到5.1,那么引入残差前是F'(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。
- 引入残差后的映射对输出的变化更敏感:比如s输出从5.1变到5.2,映射F'的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。