对文本序列进行编码获得向量有了很多的工作,而对于如何把前面网络(RNN/CNN的输出)获得的向量进行处理获得特定长度的向量的工作比较少。通常使用简单的max/average pooling,是自下而上的,并且消极的信息聚集,缺少特定任务信息的引导。本文中,提出了一个聚集机制,即动态路由机制来获得固定长度的编码。动态路由机制动态决定怎样和如何进行每个词的信息传递。根据capsule网络的工作,设计了两层动态路由机制聚集RNN/CNN编码层的输出,并传递到最后一层。与其他聚集方法相比,动态路由可以根据最后编码的向量重新改进信息。
https://github.com/FudanNLP/Capsule4TextClassification
1 Introduction
学习文本序列的分布表示,比如句子或是文档,对于自然语言处理的应用特别重要,主要的挑战就是如何把不同长度的文本序列编码成特定长度的向量,而且完全捕获文本的语义信息。
一些有效的文本编码方法通常包括三个重要步骤:
- 文本序列的每个用embedding表示
- 词的embedding作为输入,并计算具有上下文语义的表示,可以使用RNN,CNN。
- 把句子的意思概括成一个固定大小的向量,可以用聚合操作。
这些模型采用监督或无监督的方法训练。
现在,主要专注两步,聚合操作不是特别强调。一些简单的聚合操作,比如max(average),用来把rnn的隐藏状态或是卷积获得的向量(之间计算获得)进行相加,获得一个向量,这种聚合信息的方式是从下向上而且消极的方法,并且缺少特定任务信息的引导,目前,一些工作使用self-attention机制对RNN或CNN进行聚合,而不是pooling。假设是词或句子的地位是不平等,一个或多个任务的上下文语义向量给每个词和不同任务的编码赋予不同的权重。上下文语义向量是训练过程获得,有注意力的聚合可以选择特定任务的信息,但是,学习得到上下文语义向量的特定长度的,
文本中,把聚合操作作为一个路由问题,即如何把源节点的信息传递到目标节点。在我们的实验中,源节点是RNN或CNN的输出,目标节点是特定长度的编码向量,表示文本序列的信息。
从这点上看,pooling和有注意力的聚合操作室特定的路由策略,不需要考虑最后编码向量的状态,比如,最后的编码向量可以接收不同词的冗余概念,固定路由策略无法避免这个问题,因此,我们希望根据最后的编码来聚合信息。
最近很好的工作,capsule网络,动态路由策略提出来了,并且比max-pooling路由更有效,受到他们的启发,提出了使用动态路由机制进行文本序列编码,而且提出了两种不同的动态路由策略。即
- 标准动态路由,和胶囊网络一样,源节点决定多少信息传递到不同的目标节点。
- 反向动态路由,目标节点决定从不同的源节点接收多少信息。
实验表明动态路由策略比其他聚合操作更好,比如max poolling,average pooling和self-attention。
2 Background: general sequence encoding for text classification
文本分类框架包括embedding层,encoding层,aggregation层,prediction层
2.1 Embedding Layer
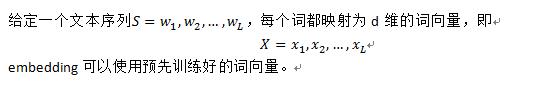
2.2 Encoding Layer

2.3 Aggregation Layer


2.4 Prediction Layer

3 Aggregation via Dynamic Routing






3.1 Analysis
DR-AGG和attention机制有点相似,但也有不同。
在标准DR-AGG,每个输入胶囊(词的编码)作为一个向量给输出胶囊设置一个权重,也就是给输出胶囊输入一部分信息,对于所有的输入胶囊,一个输入胶囊的获得的所有信息量是相同的。
在反转DR-AGG,每个输出胶囊作为一个向量给每一个输入胶囊设置一个权重,所以输出胶囊从输入胶囊获得一部分信息,对于所有的输出胶囊,一个输出胶囊获得的所有信息量是相同的。
DR-AGG和self-attention的差别是self-attention的向量是与任务有关的,且在训练过程是一个参数,而DR-AGG的向量是输入或输出的胶囊,是与例子有关的且动态的。

另外,self-attention聚合收集信息的方式是bottom-up方式,不考虑最后状态的编码,这很难避免信息冗余和信息损失,在标准DR-AGG里,每个词决定怎么和把多少信息送到最后状态。
4 Hierarchical Dynamic Routing for Long Text
动态路由机制可以聚合不同长度的文本编码,所以可以处理长文本,比如全段和文档。
为了加强信息聚合的有效性和伸缩性,使用了层次级动态路由机制来处理长文本。层次级路由策略可以并行计算。
首先,把文本分成多个句子,分别在词级和句子级使用动态路由机制,首先把每个句子编码成固定长度的向量,然后把句子向量编码成文本向量。
5 Experiment
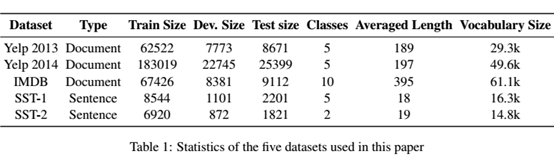
5.1 Datasets
5.2 Training


5.3 Experimental Results

