一、Prometheus简介
Prometheus 是一套开源的系统监控报警框架。它将所有信息都存储为时间序列数据,实时分析系统运行的状态、执行时间、调用次数等,为性能优化提供依据。他提供了通用的数据模型和便捷的数据采集、存储和查询接口,同时基于Go实现大大降低了服务端的运维成本,可以借助一些优秀的图形化工具(如Grafana)实现友好的图形化和报警。
Prometheus根据配置的任务(job)以周期性的收刮(scrape/pull)指定目标(target)上的指标(metric)。目标(target)可以以静态方式或者自动发现方式指定。Prometheus将收刮(scrape)的指标(metric)保存在本地或者远程存储上(默认使用本地存储)。Prometheus这种以pull来收集指标的方式,对比push,可以实现集中配置。
作为新一代的监控框架,基于中心化的数据采集分析。Prometheus 具有以下特点:
-
强大的多维度数据模型:
1.时间序列数据通过 metric 名和键值对来区分。
2.所有的 metrics 都可以设置任意的多维标签。
3.数据模型更随意,不需要刻意设置为以点分隔的字符串。
4.可以对数据模型进行聚合,切割和切片操作。
5.支持双精度浮点类型,标签可以设为全unicode。 -
多维度上灵活的查询语句(PromQL):在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作。
-
易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
-
高效:平均每个采样点仅占3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
-
通过基于HTTP的pull方式采集时序数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的 metrics。
-
可以采用 push gateway的方式把时间序列数据推送至 Prometheus server 端(可以通过中间网关进行时序列数据推送 pushing)。
-
可以通过动态服务发现或者静态配置采集去获取监控的目标服务器。
-
多种可视化和仪表盘支持。
-
易于伸缩。
在选择Prometheus作为监控工具前,要明确它的适用范围,以及不适用的场景。在微服务的监控上,Prometheus对多维度数据采集及查询的支持也是有特殊优势的。Prometheus更强调可靠性,即使在故障的情况下也能查看系统的统计信息。权衡利弊,以可能丢失少量数据为代价确保整个系统的可用性。因此,它不适用于对数据准确率要求100%的系统,比如实时计费系统。
Prometheus提供了4中不同的Metrics类型: Counter, Gauge, Histogram, Summary。
Counter:只增不减的计数器
计数器可以用于记录只会增加不会减少的指标类型,比如记录应用请求的总量,cpu使用时间等。
对于Counter类型的指标,只包含一个inc()方法,用于计数器+1。
一般而言,Counter类型的metrics指标在命名中我们使用_total结束。
如http_requests_total{method="get", job="Prometheus", handler="query"}
Gauge:可增可减的仪表盘
对于这类可增可减的指标,可以用于反应应用的当前状态。
例如在监控主机时,主机当前空闲的内存大小,可用内存大小或者容器当前的cpu使用率,内存使用率。
对于Gauge指标的对象则包含两个主要的方法inc()以及dec(),用于添加或者减少计数。
如go_goroutines{instance="172.17.0.2", job="Prometheus"}
Histogram:自带buckets区间的数据分布统计图(直方图)
主要用于在指定分布范围内(Buckets)统计事件发生的次数或者大小。
如http_request_duration_microseconds_sum{job="Prometheus", handler="query"}
Summary: 客户端定义的数据分布统计图(概略图)
Summary和Histogram非常相似,都可以统计事件发生的次数或者大小,以及其分布情况。
Summary和Histogram都提供了对于事件的计数_count以及值的汇总_sum。因此使用_count和_sum时间序列可以计算出相同的内容。
Summary和Histogram都可以计算和统计样本的分布情况,比如中位数。不同在于Histogram可以通过histogram_quantile函数在服务器端计算,而Sumamry的分位数则是直接在客户端进行定义的。由此可见,对于分位数的计算,Summary在通过PromQL进行查询时有更好的性能表现,相对的对于客户端而言Histogram消耗的资源更少。
二、Prometheus组成及架构
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
-
Prometheus Server: 根据配置完成数据采集, 服务发现以及数据存储。
-
Client Library: 客户端库,对接 Prometheus Server,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
-
Push Gateway : 为应对部分push场景提供的插件,监控数据先推送到 Push Gateway 上,然后再由 Prometheus Server 端采集 pull 。(若 Prometheus Server 采集间隔期间,Push Gateway 上的数据没有变化, Prometheus Server 将采集到2次相同的数据,仅时间戳不同)。
主要用来支持短连接任务。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。
-
Exporters(探针): 是Prometheus的一类数据采集组件的总称。提供采集接口,用于暴露已有的第三方服务的 metrics 给 Prometheus。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取。类似传统意义上被监控端的 agent 。
-
Alertmanager: Prometheus server 主要负责根据告警规则分析数据并发送告警信息到alertmanager,alertmanager则是根据配置处理告警信息并发送。从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对应集成的接受端,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。Alertmanager三种处理告警信息的方式:
1、分组:将监控目标相同的告警进行分组。如发生停电,收到的应该是单一信息,信息中包含所有受影响宕机的机器,而不是针对每台宕机的机器都发送一条告警信息。
2、抑制:抑制是指当告警发出后,停止发送由此告警引发的其他告警的机制。如机器网络不可达,就不再发送因网络问题造成的其他告警。
3、沉默:根据定义的规则过滤告警信息,匹配的告警信息不会发送。
-
一些其他的工具,如可视化的dashboard (两种选择,promdash 和 grafana。目前主流选择是 grafana)。
Prometheus 架构图如下:
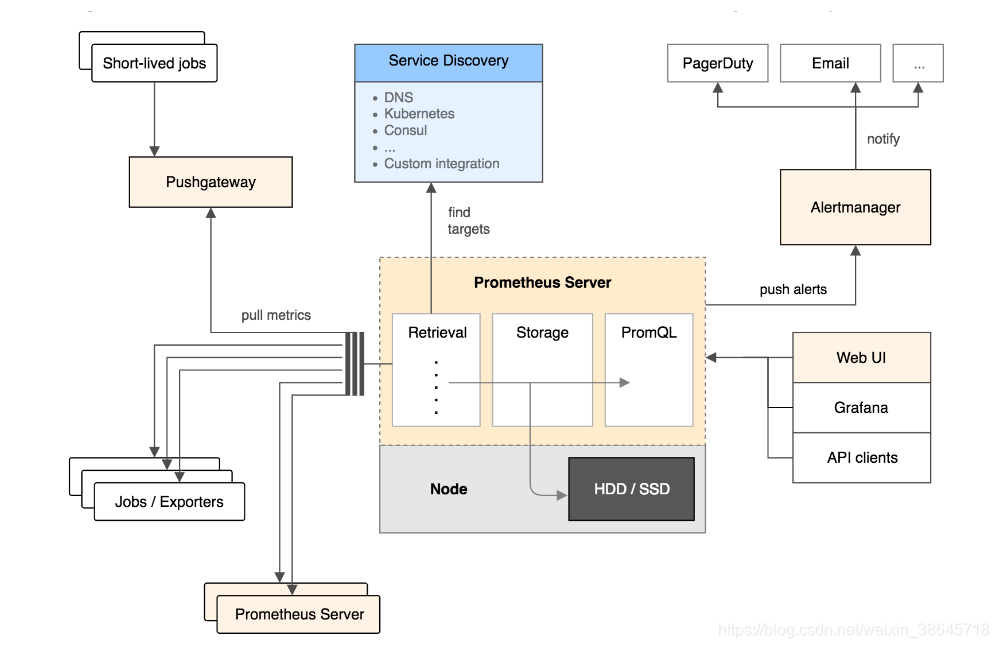
其大概的工作流程是:
- Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
- Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
- Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
Prometheus 中存储的数据为时间序列,是由 metric 的名字和一系列的标签(键值对)唯一标识的,不同的标签则代表不同的时间序列。
- metric 名字:该名字应该具有语义,一般用于表示 metric 的功能,例如:http_requests_total, 表示 http 请求的总数。
- 标签:使同一个时间序列有了不同维度的识别。例如 http_requests_total{method=“Get”} 表示所有 http 请求中的 Get 请求。当 method=“post” 时,则为新的一个 metric。
- 样本:实际的时间序列,每个序列包括一个 float64 的值和一个毫秒级的时间戳。
- 格式:
< metric name >{ < label name > = < label value >, … }
instance 和 jobs
instance: 一个单独 scrape 的目标, 一般对应于一个进程。
jobs: 一组同种类型的 instances(主要用于保证可扩展性和可靠性),例如:
job: api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
instance 3: 5.6.7.8:5670
instance 4: 5.6.7.8:5671
当 scrape 目标时,Prometheus 会自动给这个 scrape 的时间序列附加一些标签以便更好的分别,例如:
由于 Prometheus 主要用于监控 web 服务,如果需要监控机器层面的 metrices(如 ubuntu server),则需要在本机上安装 Node exporter。Node exporter 主要用于暴露 metrics 给 Prometheus,metrics 主要包括:cpu 的负载,内存的使用情况,网络等。

quantile(分位数)、bucket(块)
三、Prometheus名词理解
探针:
利用Prometheus官方或第三方提供的探针,基本可以完成对所有常用中间件或第三方工具的监控。
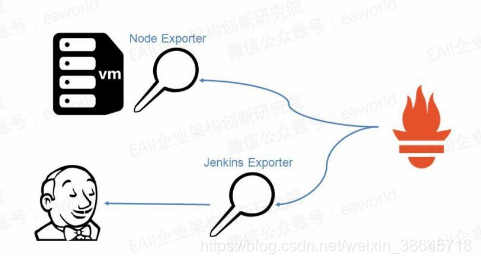
硬件及系统监控探针node exporter通过getMemInfo()方法获取机器的内存信息,然后将机器总内存数据对应上指标node_memory_MemTotal。
Jenkins探针Jenkins Exporter通过访问Jenkins的api获取到Jenkins的job数量并对应指标Jenkins_job_count_value。
探针的作用就是通过调用应用或系统接口的方式采集监控数据并对应成指标返回给prometheus server。注:探针不一定要和监控的应用部署在一台机器。
总的来说Prometheus数据采集流程就是,在Prometheus server中配置探针暴露的端口地址以及采集的间隔时间,Prometheus按配置的时间间隔通过http的方式去访问探针,这时探针通过调用接口的方式获取监控数据并对应指标返回给Prometheus server进行存储(若探针在Prometheus配置的采集间隔时间内没有完成采集数据,这部分数据就会丢失)。
动态服务发现
Prometheus支持多种服务发现的方式,这里主要介绍 file_sd的方式。之前提到Prometheus server的数据采集配置都是通过配置文件,那服务发现该怎么做?总不能每次要添加采集目标还要修改配置文件并重启服务吧。
这里使用file_sd_configs 定义了采集目标的文件。Prometheus server会动态检测该配置文件的变化来更新采集目标信息。现在只要能更新这个配置文件就能动态的修改采集目标的配置了。
这里采用consul+consul template的方式。在新增或减少探针(增减采集目标)时在consul更新k/v,如新增一个探针,添加如下记录Prometheus/linux/node/10.15.15.132=10.15.15.132:9100,然后配置consul template监控consul的Prometheus/linux/node/目录下k/v的变化,根据k/v的值以及提前定义的discovery.ctmpl模板动态生成Prometheus server的配置文件discovery.yml。