lucene是一个基于java的全文搜索工具包,实现了为应用提供索引和搜索功能。目前很多应用的搜索均基于lucene实现。
lucene可以为文本类型的数据建立索引,而不限制数据来源,可以是来自文件、db等任何数据存储的地方。lucene采用的是反向索引机制。
在lucene为你传给他的文本类型数据简历索引之后,索引会保存在磁盘或内存中,此时再使用查询条件进行查询就可以了。
使用过程:
存储数据文档–>对文档分词并建立索引–>输入关键词–>对关键词分词–>在已经创建的索引中进行查找–>返回与关键词相关的文档
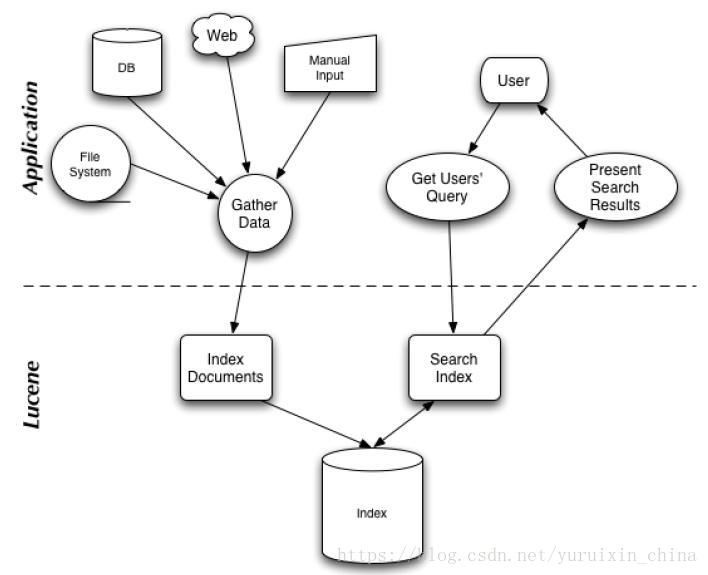
lucene提供的几个基础类:
Document 是用来描述文档的,这里可以理解为一条记录
Field 是用来描述一个文档中的某个属性,这里可以理解为一条记录的某个字段
Analyzer 在对一个文档建立索引之前,需要通过Analyzer进行分词,然后把分词结果交给IndexWriter创建索引。(中文分词采用IK分词器,下载地址)
IndexWriter 创建索引的核心类,它负责将所有Document对象加到索引中来
Directory
这代表Lucened索引存储位置(FSDirectory:存储硬盘中的索引位置;RAMDirectory,存储在内存中的索引位置)
添加索引的示例代码:
public static void index(){
//创建Directory(索引存放位置)
Directory directory = directory = FSDirectory.open(new File("D:\\Documents\\hellolucene\\index02"));
IndexWriter writer = null;
try {
//创建IndexWriter对象 所需参数:索引位置、指定配置、指定分词类
writer = new IndexWriter(directory,new IndexWriterConfig(Version.LUCENE_35,new StandardAnalyzer(Version.LUCENE_35)));
writer.deleteAll();
Document doc = null;
for (int i = 0; i < ids.length; i++) {
doc = new Document();
doc.add(new Field("id",ids[i],Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field("email",emails[i],Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS));
doc.add(new Field("content",contents[i],Field.Store.NO,Field.Index.ANALYZED));
doc.add(new Field("name",names[i], Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS));
//添加文档
writer.addDocument(doc);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}在索引建立完成之后,通过IndexSearcher, Term, Query, TermQuery, Hits等lucene提供的基础类即可完成搜索操作了