异常检测问题
异常检测问题的定义如下:
假设我们有m个正常的样本数据 ,我们需要一个算法来告诉我们一个新的样本数据 是否异常。
我们要采取的方法是:给定无标签的训练集,对数据集
建立一个概率分布模型
。当我们建立了
的概率模型之后,我们就会说,对于新的样本
,如果概率
低于阈值
:
那么就将其标记为异常,反之,我们就认为它是正常的。

高斯分布
假设x是一个实数随机变量(即:x∈R),如果x的概率分布服从高斯分布:其中均值为μ,方差为
,那么将它记作:
这里的∼符号读作:”服从…分布”。大写字母N表示Normal (正态),有两个参数,其中μ表示均值, 表示方差。
如果我们将高斯分布的概率密度函数绘制出来,它看起来将是这样一个钟形的曲线:

这个钟形曲线有两个参数,分别是μ和σ。其中μ控制这个钟形曲线的中心位置,σ控制这个钟形曲线的宽度。
从图中可以看出来,x取中心区域的值的概率相当大,因为高斯分布的概率密度在这里很大;而x取远处和更远处数值的概率将逐渐降低,直至消失。
高斯分布中,μ和σ的关系
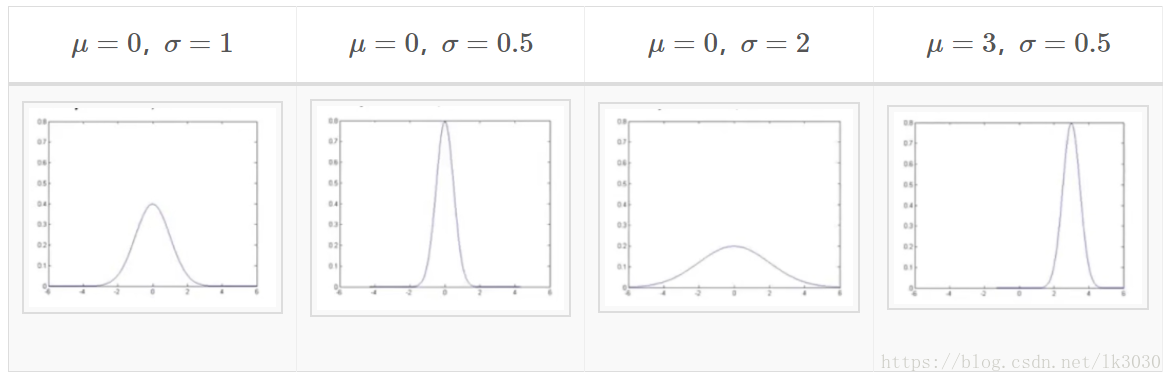
- 值得提醒的是,在高斯分布的图像中,不管曲线的形状如何,曲线围城的总面积都是1。
- 所以如果σ很大,就意味着数据的离散化程度越大,中间区域就会变宽,但由于总概率为1,所以高度会降低。
- 反之如果σ很小,就意味着数据的离散化程度越小,中间区域就会变窄,但由于总概率为1,所以高度会升高。
异常检测的具体算法
假如说我们有一个无标签的训练集,其中共有m个训练样本,并且这里的训练集里的每一个样本都是n维的特征,因此你的训练集应该是m个n维的特征构成的样本矩阵:
对于我们的异常检测算法,我们要从数据中建立一个p(x)概率模型。由于x是一个向量,因此:
假定特征
都服从高斯正态分布:
其中 (读作pai,是 的大写形式)类似 符号,只不过这里将连加换成了连乘。顺便要说的是,估计 的分布问题,通常被称为密度估计问题。
异常检测算法步骤总结
- 从样本中选择一些能体现出异常行为的特征 。
分别计算出每个特征的参数
给定一个新的样本x,计算出它对应的p(x):
通过判断p(x)<ε,来判断是否有异常发生。
异常检测 VS 监督学习
评价一个异常检测算法时,使用了一些带标签的数据,以及一些我们知道是异常或者正常的样本(用y=1或y=0来表示)。
这就引出了这样一个问题:既然我们有了带标签的数据,那么为什么我们不直接用监督学习的方法(比如逻辑回归或者神经网络)呢?
| 异常检测 | 监督学习 |
|---|---|
| 负样本量很少(通常是在0到20个之间),正样本很多的时候 | 正负样本都很多的时候 |
| 有多种不同的异常类型时(因为对任何算法来说,从大量正样本中去学习到异常具体是什么,都是困难的);未知的异常与我们已知的异常完全不一样时。 | 有足够多的正样本来让你的算法学习到对应的特征,并且在未知的正样本中,也和已知的样本是类似的。 |
其实关键区别就是在异常检测算法中我们只有一小撮正样本,因此监督学习算法不能从这些样本中学到太多东西。
对不服从高斯分布的数据进行转换
在我们的异常检测算法中,我们做的事情之一就是使用正态(高斯)分布来对特征向量建模。
通常情况下,我们都需要用直方图来可视化这些数据,为了在使用算法之前,确保我们的数据看起来是服从高斯分布的(当然即使你的数据并不是高斯分布,它也基本上可以良好地运行,但最好转换成高斯分布的样式之后在带入计算)。
如果你的样本的某个特征展示效果完全不像一个正态分布的形状:

那么我们就需要对数据进行一些转换,来确保这些数据能看起来更像高斯分布。一般情况下,我们都会对原始数据尝试求对数或者开根号操作进行转换:

通过多元高斯分布改良异常检测算法
在多元高斯分布中,对于n维特征x∈Rn,不要把模型 , ,…, 分开,而要建立 整体的模型。
多元高斯分布的参数包括向量µ和一个n×n的协方差矩阵Σ:
对于多元高斯分布来说,一个很棒的事情就是我们可以用它来对数据的相关性建模。也就是说,我们可以用它来给 和 高度相关的情况建立模型。