Javap 反编译class文件 –verbose 显示冗余信息
(1)魔数:所有的class字节码文件的4个字节都是魔数,魔数固定值:0xCAFEBABE
(2)版本:魔数之后4个字节是版本信息,前两个字节minor version次版本号例如0,后两个字节是主板号major version例如52表示1.8.0。
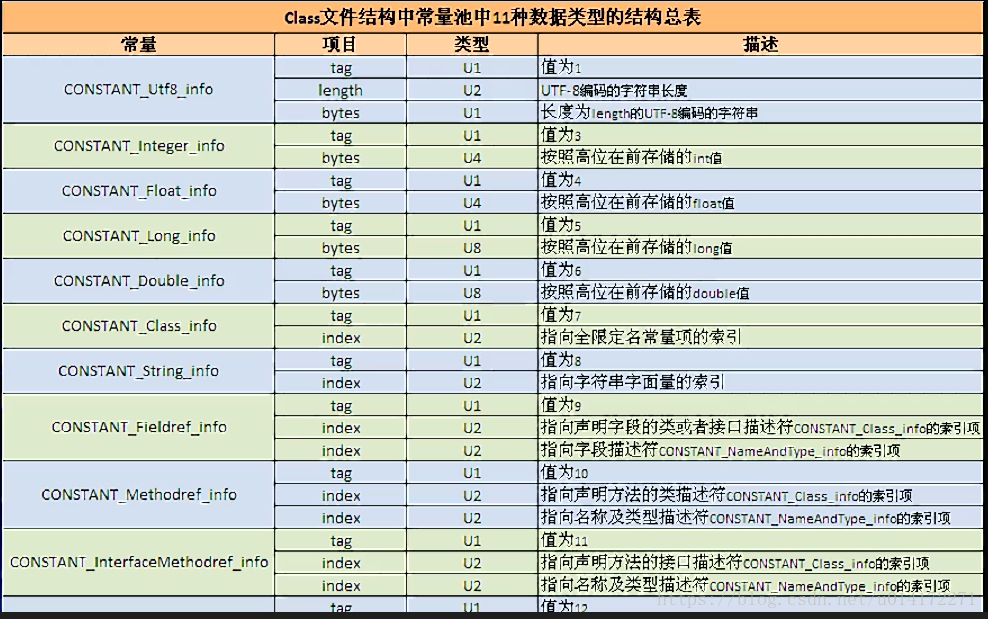
(3)常量池:主版本后就是常量池入口。常量池的长度不是固定的。Java类中定义的很多信息都是由常量池来维护和描述的。可以将常量池看做是Class文件的资源仓库,例如说java类中定义的方法与变量信息。常量池中主要存储两类常量:字面量和符号引用。
①字面量:文本字符串,final常量。
②符号引用:类和接口的全局限定名。字段名称和描述符,方法的名称和描述符。
Java类所对应的常量池主要由常量池数量与常量池数组(也称常量表)这两部分共同构成。(这么做可以最大压缩存储文件体积)。常量池数量紧跟在主版本号后面,占用2个字节。常量池数组仅跟在常量池数量之后。常量池数组不同与一般数组,不同元素类型,结构都不相同。每一个元素的第一个数组都是u1类型,是一个标志位,占据1个字节,JVM在解析常量池时,会根据u1类型来获取元素的具体类型。值得注意的是,常量池数组中元素的个数=常量池-1(其中0暂时不使用)。目的是满足某些常量池索引值的数据在特定情况下所需表达[不引用任何常量池]的含义。索引0是一个保留常量,不位于常量数组中,对应null值,所以索引从1开始。
(4)在jvm规范中,每个变量/字段都有描述信息,描述信息主要作用是描述字段的数据类型,方法的参数列表(包括数量、类型、顺序)与返回值。根据描述符规则,基本数据类型和代表无返回值的void类型都用一个大写字符来表示,对象类型则使用字符串L加对象的权限定名来表示。为了压缩字节码的体积,对于基本数据类型,jvm都只使用一个大写字母来表示,如下所示:B –byte, C –char, D –double, F—float, I—int, J –long S – short, Z – Boolean, V—void, L—对象类型。例如Ljava/lang/String
对于数组类型来讲,每一个维度使用一个前置的[来表示,如int[]被标记为[I,String[][]被标记为[[Ljava.lang.String 注意:这个是给机器看的
用描述符描述方法时,按照先参数列表,后返回值的顺序来描述。参数列表按照参数的严格顺序放在一组()之内。例如String getRealnameByIdAndNickname(int id, String name)的描述为:(I,Ljava/lang/string;) Ljava/lang/String;

| Constant pool: #1 = Methodref #4.#20 // java/lang/Object."<init>":()V #2 = Fieldref #3.#21 // com/lesson/model/MyTest.a:I #3 = Class #22 // com/lesson/model/MyTest #4 = Class #23 // java/lang/Object #5 = Utf8 a #6 = Utf8 I #7 = Utf8 <init> #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 LocalVariableTable #12 = Utf8 this #13 = Utf8 Lcom/lesson/model/MyTest; #14 = Utf8 getA #15 = Utf8 ()I #16 = Utf8 setA #17 = Utf8 (I)V #18 = Utf8 SourceFile #19 = Utf8 MyTest.java #20 = NameAndType #7:#8 // "<init>":()V #21 = NameAndType #5:#6 // a:I #22 = Utf8 com/lesson/model/MyTest #23 = Utf8 java/lang/Object { public com.lesson.model.MyTest(); descriptor: ()V flags: ACC_PUBLIC Code: stack=2, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: aload_0 5: iconst_1 6: putfield #2 // Field a:I 9: return LineNumberTable: line 3: 0 line 5: 4 LocalVariableTable: Start Length Slot Name Signature 0 10 0 this Lcom/lesson/model/MyTest;
public int getA(); descriptor: ()I flags: ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: getfield #2 // Field a:I 4: ireturn LineNumberTable: line 8: 0 LocalVariableTable: Start Length Slot Name Signature 0 5 0 this Lcom/lesson/model/MyTest;
public void setA(int); descriptor: (I)V flags: ACC_PUBLIC Code: stack=2, locals=2, args_size=2 0: aload_0 1: iload_1 2: putfield #2 // Field a:I 5: return LineNumberTable: line 12: 0 line 13: 5 LocalVariableTable: Start Length Slot Name Signature 0 6 0 this Lcom/lesson/model/MyTest; 0 6 1 a I } |
(1) 00 36 表示次版本号例如0,主版本号1.8.0
(2) 00 18 (索引0,数组长度)常量池索引0位置为保留, 16进制18即24,也就是数组长度,但是0是保留常量,所以准确来说23.
(3)0A tag值10 对应constant_methodref_info,占据4个字节
前两个表示指向声明字段的类或者接口描述符constant_class_info的索引(00 04--即4)
后两个表示名称及类型描述符constant_nameandtype_info的索引项(00 14即20)
#1 = Methodref #4.#20 // java/lang/Object."<init>":()V
(4)09 tag值9 对应constant_fieldref_info,占据4个字节
前两个表示字段的类型或者接口描述符constant_class_info的索引项(00 03即3)
后两个表示字段描述符constant_nameandtype_info的索引项(00 15即21)
#2 = Fieldref #3.#21 // com/lesson/model/MyTest.a:I
#3-class表示当前类
#21-对应两个部分:#5#6; #5--a(字段名称) #6--I(integer)
(5)07 tag值7 对应constant_class_info, 占据2个字节
00 16 即22 com/lesson/model/MyTest类全限定名称
#3 = Class #22 // com/lesson/model/MyTest
(6) 07 tag值7对应constant_class_info, 占据2个字节
00 17即23 com/lang/object类全限定名称
(7)01 tag值1 对应constant_utf-8_info, 占据3个字节
前两个表示utf-8编码字符长度。00 01 即1个字节
00 01 后面一个字节是61。61就是a(asc 码)
(8) 01 tag值1
………………..就这样一点一点分析就明白了字节码
纵观java字节码的整体结构由下面10个部分构成,精确的描述了字节码信息

try-finally分析:
public static String test(){
String res = "he";
try {
return res;
} finally {
res = "res";
}
}
0: ldc #5 // String he he压入栈顶
2: astore_0 //he 存到本地变量0中
3: aload_0 //本地变量1中压栈
4: astore_1 //he 存到本地变量1中
5: ldc #6 // String res res压入栈顶
7: astore_0 //res 存到本地变量0中
8: aload_1 //本地变量1中压栈
9: areturn //返回本地变量1 he
10: astore_2
11: ldc #6 // String res
13: astore_0
14: aload_2
15: athrow