文章目录
以下只针对widows平台,linux下没有测试
一、Tesseract-OCR 安装
Tesseract-OCR遵循Apache 2.0 license开源协议。
下载地址:https://digi.bib.uni-mannheim.de/tesseract/
你也可以查看源码编译安装:https://github.com/tesseract-ocr/tesseract/wiki/Downloads
或者非官方安装包:https://github.com/UB-Mannheim/tesseract/wiki
windows下安装一路next
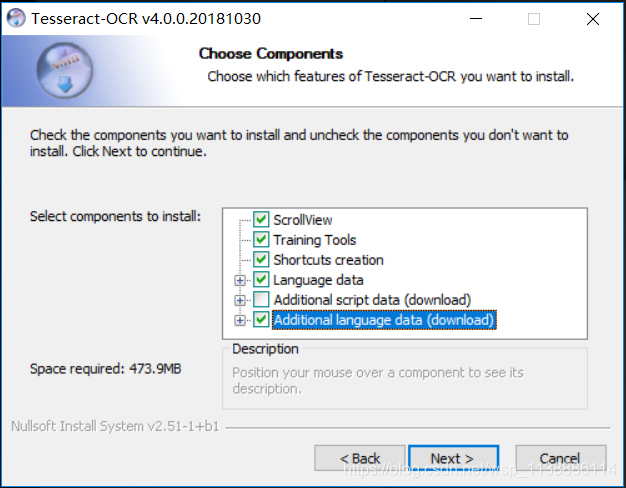
这一步,我们需要选择添加语言 chinese simple
在进入安装目录,执行.\tesseract
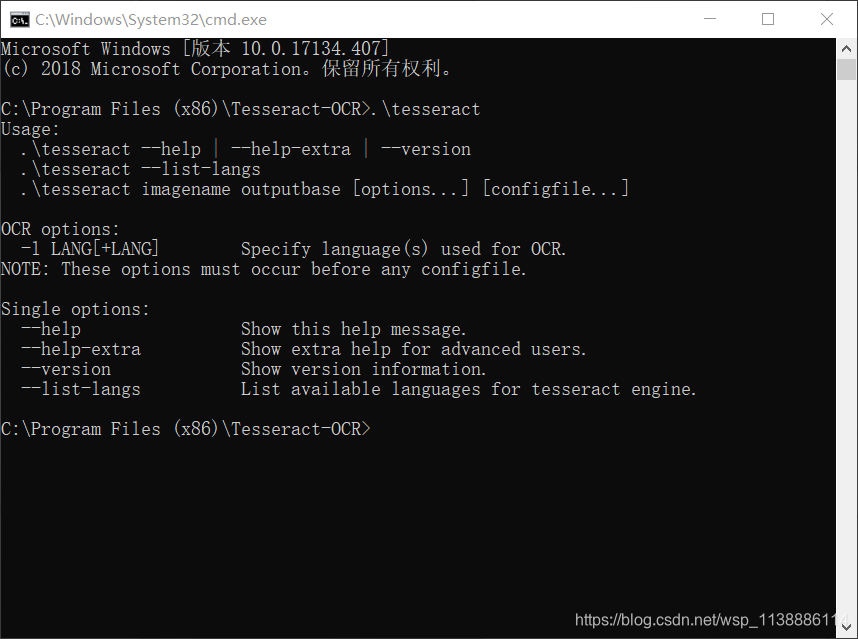
二、测试
-
查看可用的 “语言”
-–list-langs执行:tesseract --list-langs -
执行
tesseract D:\example_05.jpg D:\out默认使用英文识别,输出out.txt -
执行
tesseract D:\example_05.jpg D:\out -l eng指定英文识别,输出out.txt -
执行
tesseract D:\example_05.jpg D:\out -l eng pdf使用英文识别,输出out.pdf -
执行
tesseract --print-parameters查看全部参数 -
使用 -c 选项来设定单项参数的值:
tesseract D:\example_05.jpg D:\out -l chi_sim -c language_model_ngram_on=1 -
使用多个 -c 选项来设置多个参数的值。
将多项参数设置写入文件,然后在识别时使用该文件:
tesseract paper.png paper -l chi_sim tess.conf扫描二维码关注公众号,回复: 4090905 查看本文章
-
需要注意的是,如果配置文件有两个配置文件 tess_1.conf 和 tess_2.conf:
tesseract paper.png paper -l chi_sim tess_1.conf tess_2.conf
以上代码确实实现了输出:不过结果糟糕,可以试一下。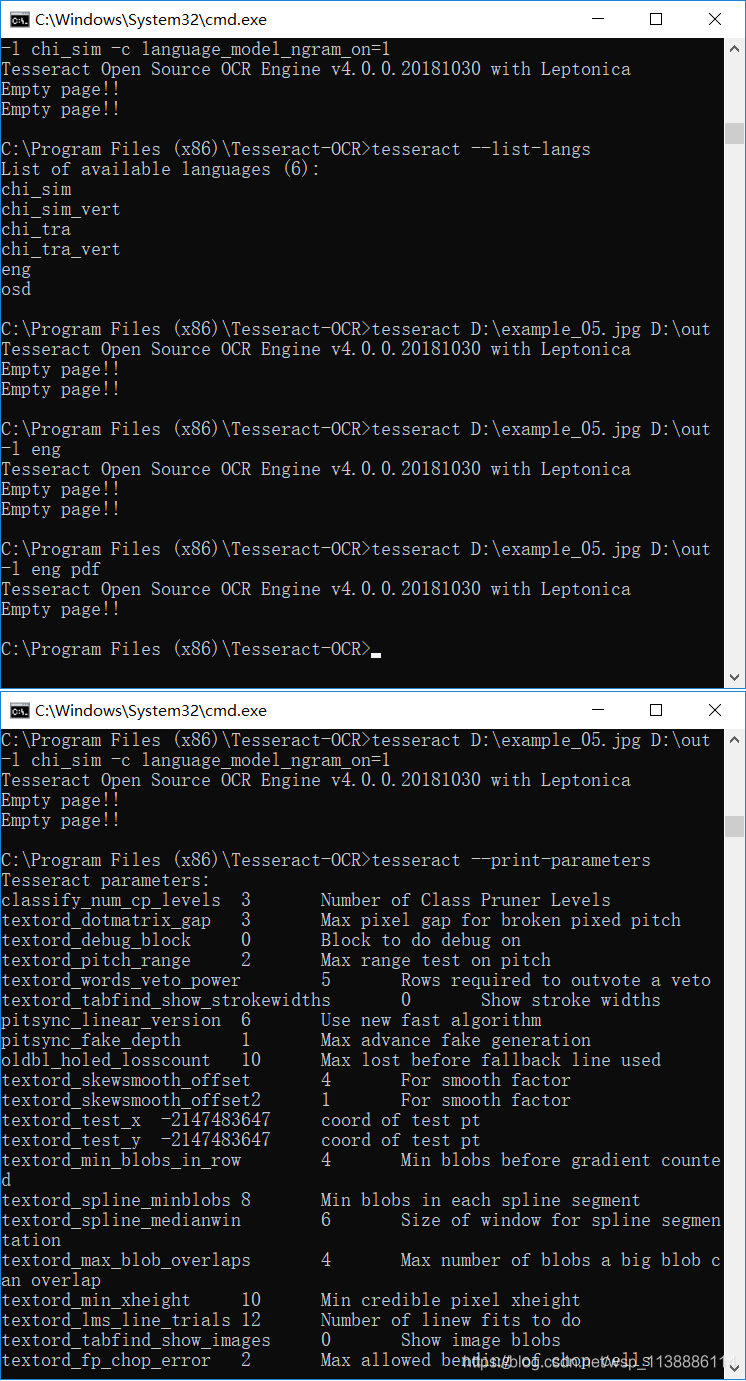
鸣谢
https://blog.csdn.net/haluoluo211/article/details/53304900